Zicoder三层搜索架构:代理编程中的代码检索设计实践

Zicoder通过三种搜索方式(AST语义检索、Trigram全文搜索、智能体搜索)构建代理编程的核心搜索能力。
文章阐述了搜索能力在AI代理编程中的核心地位,并详细介绍了Zicoder项目设计的三种搜索方式:基于AST的三层架构搜索实现语义级代码检索,Trigram倒排索引实现毫秒级精确全文搜索,以及基于ReAct框架的智能体搜索实现自主多轮探索。三者互补协作,搜索结果还可转化为可复用Skill,形成知识积累。
为什么搜索是代理编程的核心能力
在AI代理编程(Agentic Coding)领域,搜索能力的好坏直接决定了整个系统的表现。搜索本质上是为语言模型提供上下文数据,如果搜索结果不准确、背景信息不完整,那么即便后续的代码生成做得再好,方向也已经偏了。
在企业级应用中,RAG(检索增强生成)一直是核心需求。RAG是一种将外部知识库与大语言模型结合的架构范式,由Meta AI在2020年提出,其核心思想是在模型生成回答之前先从外部数据源检索相关文档,将其作为上下文注入提示词,从而弥补模型训练数据的时效性不足和领域知识缺口。在代理编程场景中,RAG的挑战远比通用问答复杂——代码库具有强依赖关系、符号引用跨文件分布、且语义理解需要结合上下文结构,这使得单一的向量检索方案往往力不从心。Zicoder项目从代码场景出发,设计了一套完整的三种搜索方式,分别应对不同的使用场景。这套方案对于理解代理编程的搜索架构设计具有很好的参考价值。

基于AST的三层架构搜索:语义级代码检索
设计理念
三层架构搜索是Zicoder中最复杂也最强大的搜索方式。它需要先对项目进行初始化(init),将整个代码库扫描后构建为三层结构:
- 需求层:基于源码进行逆向推导,还原出业务需求
- 架构层:提取系统的架构设计信息
- 实现层:具体的代码实现细节
这种设计的核心思想是:不同粒度的问题需要在不同层次上检索。当你问"系统如何处理用户认证"时,需要在需求层和架构层搜索;当你问"某个函数的具体实现"时,则需要深入到实现层。
技术实现细节
底层实现上,系统首先对整个代码进行AST(抽象语法树)解析,形成树状结构。AST是编译器前端的核心数据结构,它将源代码解析为树状的语法节点,每个节点代表一种语言构造(如函数定义、变量声明、条件语句等)。与纯文本处理不同,基于AST的分析能够理解代码的结构语义——例如区分同名变量在不同作用域中的含义,或识别函数调用链的层级关系。现代工具如Tree-sitter支持对40余种编程语言进行增量式AST解析,已成为代码智能工具的标准底层组件。系统在完成AST解析后,利用大模型对这些节点进行语义描述,形成一张语义图,最终通过向量化存储,支持两个层次的检索:
- 底层搜索:基于代码结构的精确匹配
- 高级语义搜索:基于自然语言的语义理解
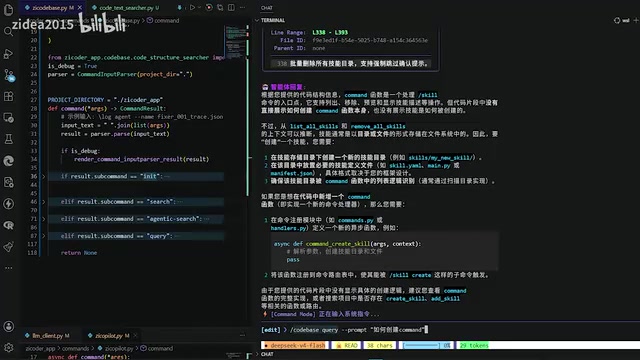
使用方式为:/codebase query --prompt <搜索内容>。例如搜索"如何创建一个command",系统会返回所有相关的代码块,包括函数签名、所在文件位置,以及结构化的描述信息。
全文搜索:Trigram倒排索引实现毫秒级定位
适用场景
并非所有搜索都需要复杂的语义理解。当你只是想知道某个变量、函数名在哪里被引用时,全文搜索是最高效的选择。这类似于VS Code中的全局搜索功能,但Zicoder将其封装为Agent可调用的工具。
Trigram + 倒排索引方案
全文搜索采用了Google的三元组(Trigram)+ 倒排索引算法。Trigram索引是一种将字符串分解为连续三字符片段的文本索引技术——例如字符串"hello"会被分解为"hel"、"ell"、"llo"三个trigram,倒排索引则记录每个trigram出现在哪些文档中。查询时,将搜索词同样分解为trigram,取各trigram对应文档集合的交集,即可快速定位候选文档。Google的代码搜索工具Zoekt和正则搜索工具Codesearch均采用此方案。这种方案的特点是:
- 无需向量化:不依赖embedding模型,完全基于内存操作
- 纯内存操作:毫秒级响应速度,支持正则表达式
- 精确匹配:适合代码符号的精确定位,是向量检索的高效互补方案
使用方式为:/codebase search --dir <搜索范围> <关键词>。系统会在指定目录范围内进行全文扫描,返回匹配位置及对应函数的签名定义。
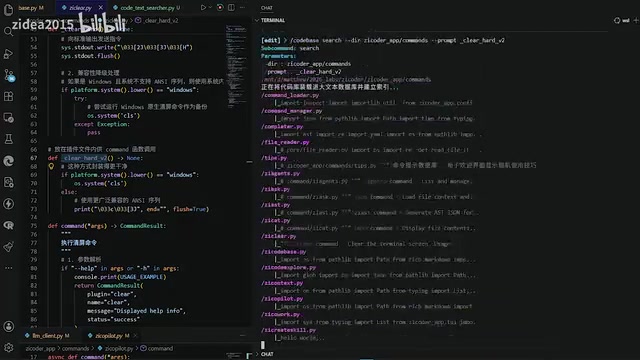
这种搜索方式的优势在于速度极快,且结果确定性高,非常适合Agent在编码过程中快速定位符号引用。
智能体搜索(Agentic Search):自主探索式代码检索
核心概念
智能体搜索是最具"AI代理"特色的搜索方式。它不是一次性返回结果,而是让一个Agent自主地、多轮地探索代码库,逐步收集和整合信息。其工作机制本质上是ReAct(Reasoning + Acting)框架的具体应用——ReAct由普林斯顿大学和Google Brain于2022年提出,核心是让语言模型在推理(Thought)和行动(Action)之间交替迭代:模型先分析当前状态,决定调用哪个工具,观察工具返回结果,再进行下一轮推理。
使用方式为:/codebase agentic --dir <范围> <搜索内容>。
工作机制
系统为搜索Agent提供了一系列工具:
- 文件列表浏览
- 文件内容读取
- grep搜索
- 目录遍历
Agent会在一个循环(loop)中不断调用这些工具,每次迭代都会收集新的信息。在代码探索场景中,Agent可能需要先列出目录结构,再读取关键文件,再通过grep验证假设,经过多轮迭代才能形成完整的理解——这正是静态RAG无法替代的能力边界。系统以"里程碑"的方式记录每次收集的进展,最终Agent会整合所有信息,返回一套完整的解决方案。
搜索结果转化为可复用Skill
智能体搜索返回的不仅是代码片段,还包括:
- 步骤化的操作指南
- 函数定义和调用关系
- 可直接转化为Skill的结构化知识
这里有一个精妙的设计:搜索结果可以通过"command to skill"命令转化为可复用的技能(Skill)。这种设计本质上是一种外部记忆(External Memory)机制——模型的参数权重是静态的训练知识,而Skill库则提供了动态的、可更新的操作性知识。微软的Voyager项目(基于Minecraft的自主Agent)也采用了类似的技能库设计,证明了这种知识积累机制在复杂任务中的有效性。对于企业级代码库,这意味着Agent在处理重复性架构模式时会越来越高效,真正实现"搜索即学习
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。