9 AI Search Tools Compared: Choosing the Right Search Solution for Your Agent
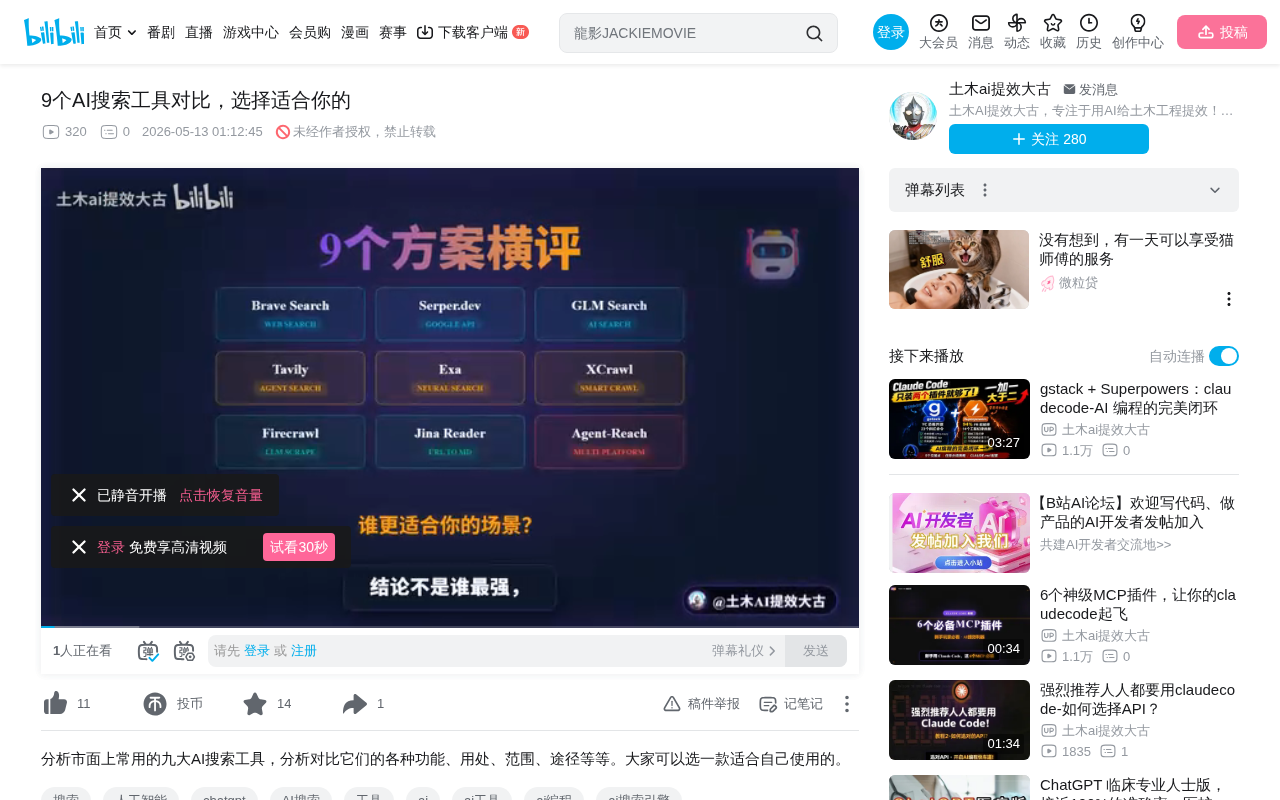
Hands-on comparison of 9 mainstream AI search tools with scenario-based selection recommendations
This article addresses the need for AI Agents to use external search tools by hands-on testing 9 mainstream solutions (including Google SERP API, GLM Search, Tavily, Exa, XCrawl, Firecrawl, Jina Reader, and AgentReach) across four dimensions: search accuracy, web crawling, SERP coverage, and special features. It provides specific tool combination recommendations for five scenarios: zero budget, Chinese-language use, Agent development, cross-border products, and heavy data collection.
Why Do AI Agents Need External Search Tools?
Many people notice a problem when using AI Agents: the model can write code and perform analysis just fine, but when it comes to research, the information often turns out to be inaccurate. The reason is simple—large language models don't have reliable built-in search and web reading capabilities.
This stems from two fundamental limitations of Large Language Models (LLMs). First is the knowledge cutoff problem: LLM training data has a temporal cutoff point. For example, GPT-4's training data cuts off at the end of 2023, meaning it has no knowledge of events, updated technical documentation, or the latest market data after that date. Second is the hallucination problem: when the model encounters uncertain information, it tends to "fabricate" answers that sound plausible but are actually incorrect. By connecting external search tools, Agents can access real-time, verifiable information sources, fundamentally reducing the probability of hallucinations.
Therefore, the mainstream approach today isn't to rely on a single model alone, but to equip Agents with external tools for search, crawling, web reading, social media reading, and more. But with so many tools available, choosing becomes the real challenge.
This article is based on hands-on testing by a Bilibili content creator, using the same test query ("What are the keys to making good videos with Remotion") to horizontally evaluate 9 mainstream AI search solutions across four dimensions: search accuracy, web crawling, SERP coverage, and unique capabilities.
A Complete Overview of Four Categories of AI Search Tools
Category 1: Pure Search Tools
- Google Search Results API: Affordable, suitable for lightweight SERP queries
- GLM Search MCP: More oriented toward Chinese-language Agent scenarios, suitable for domestic content retrieval
SERP (Search Engine Results Page) refers to the complete results page returned when a user enters a query in a search engine. SERPs include not only traditional blue links but also Featured Snippets, Knowledge Panels, image carousels, People Also Ask, and various other rich media elements. For AI Agents, being able to parse the complete SERP structure means accessing information from multiple dimensions, not just web links.
MCP (Model Context Protocol) mentioned in GLM Search MCP is an open protocol proposed by Anthropic, designed to standardize communication between LLMs and external tools. Through MCP, AI Agents can use external tools like function calls without writing specific integration code for each tool. The emergence of this standardized protocol has significantly reduced the development and maintenance costs of Agent tool chains.
These tools are characterized by handling only search without deep crawling—low cost and fast response.
Category 2: Search + Crawling Tools
- Tavily: Very common in the Agent development community, easy to get started with, returns results with fields optimized for LLM consumption
- Exa (XA): Excels at semantic search—you describe what you mean, and it delivers more precisely targeted results
- XCrawl: Search, crawling, sitemaps, batch fetching, SERP search engine aggregation, LLM search—the most comprehensive capability set
Regarding Exa's semantic search, it's worth explaining the fundamental difference from traditional keyword search. Traditional search engines rely on keyword matching—the words users input must appear on the target webpage to be retrieved. Semantic search is based on Vector Embedding technology, converting both queries and documents into points in a high-dimensional vector space, then calculating cosine similarity between vectors to determine semantic relevance. This means even if a target page doesn't contain your exact search terms, it can still be found as long as the semantics are similar. This is why Exa can understand natural language intent like "I want to find content about video production best practices" and return semantically related pages like Performance Tips and Encoding Guide that don't exactly match the keywords.
Category 3: Web Crawling Tools
- Firecrawl: Extremely comprehensive crawling, ideal for converting web pages into LLM-friendly content
- Jina Reader: The most lightweight option, suitable for quickly reading webpage body text
Category 4: Social Media Aggregation Tools
- AgentReach: Not a single API, but more like an internet capability scaffold for AI Agents, particularly strong at multi-platform social media reading
Four-Dimension Hands-On Comparison Results
Search Accuracy Comparison
GLM Search returned 10 Chinese-language results covering diverse sources including Zhihu, Tencent Cloud, CSDN, and Qiniu Cloud—superior in quantity and breadth for Chinese scenarios. XCrawl returned 5 results for Chinese queries with adequate quality; switching to English with US region settings yielded official documentation and Reddit content with high richness.
Exa works differently—it uses semantic search. When searching for "Best Practices," it doesn't match keywords but understands the intent and recommends pages like Performance Tips and Encoding Guide. Tavily's distinguishing feature is automatically including an AI summary with search results, eliminating the need for separate summarization.
Summary: GLM has broader Chinese coverage, Exa is more precise in semantic understanding, XCrawl is more convenient for switching between Chinese and English, and Tavily uniquely offers AI summaries.
Web Crawling Capability Comparison
All tools were tested crawling the same Remotion official documentation page:
- Firecrawl: Outputs very complete Markdown with rich metadata (title, description, tags) and fully preserved code blocks
- XCrawl: Supports 4 output formats (Markdown, JSON, HTML, screenshots). JSON mode automatically splits content into headings, sections, and code blocks—the highest degree of structuring
- Jina Reader: Simplest to use—just one command—but only outputs Markdown with average stability
Why is structured data extraction so important? Web content is essentially unstructured HTML documents containing navigation bars, ads, sidebars, and other noise. Converting web pages into structured data (such as JSON format, categorized by headings, paragraphs, code blocks, etc.) is crucial for LLM processing. Structured data not only reduces token consumption (directly lowering API call costs) but also enables models to more precisely locate needed information without being distracted by irrelevant content. This is why XCrawl's JSON output mode and Exa's Output Schema feature are particularly popular in Agent development.
Summary: Choose XCrawl for structured data, Firecrawl for complete content, and Jina for quick reading.
Search Engine Aggregation Capability
Most tools don't address this dimension. Google SERP API focuses solely on Google, but XCrawl integrates over 30 search engines including Google, Baidu, and Bing. For SEO research and competitive monitoring, you can query multiple search engines simultaneously for comparison—one capability that eliminates the hassle of integrating multiple APIs.
Special Features Summary
- Exa: Output Schema feature—pass in a JSON structure and get structured data back with field-level source citations
- Tavily: Automatically generates a 200-word summary with each search
- XCrawl: LLM search feature that calls ChatGPT for deep research, outputting complete reports with code examples (~3000 words)
- AgentReach: Connects to multiple mainstream social media platforms, some usable directly, others requiring simple configuration
Selection Recommendations by Scenario
Zero-Budget Starter Plan
AgentReach + Jina Reader
One handles multi-platform access, the other handles quick web reading. Low cost, suitable for getting your workflow running first.
Domestic Chinese-Language Scenario
GLM Search MCP + AgentReach + XCrawl
Multi-channel supplementation, suitable for filling gaps in Chinese search and social content.
AI Agent Development Plan
Tavily or Exa (for search) + XCrawl (for deep crawling and structured extraction)
The design logic of this combination decouples "discovering information" from "deeply acquiring information." Tavily/Exa excels at quickly finding relevant pages and returning summary-level content, while XCrawl handles deep crawling and structured processing of key pages. Together they form a complete information acquisition pipeline.
International/Cross-Border Product Plan
XCrawl's capability combination has a clear advantage:
- Can switch countries and languages for searches
- 30+ search engines packaged into one SERP interface—Google, Bing, and local search engines from different countries all accessible with one command
- Focuses on residential proxies, structured extraction, and integrated collection pipelines
- High adaptability for common cross-border scenarios: e-commerce, competitive analysis, recruitment, public opinion monitoring, SEO, etc.
Residential Proxy refers to a proxy service that uses real household network IP addresses for web requests. Compared to data center proxies, residential proxy IPs come from address pools assigned by ISPs to regular users, making them harder for target websites to identify and block. In cross-border data collection scenarios, residential proxies can simulate real user access from different countries and regions to obtain localized search results and content. For example, Google results seen with a US residential IP are completely different from those seen with a Japanese IP—this is particularly critical for cross-border product competitive analysis, price monitoring, and localized SEO research.
Heavy Data Collection Plan
XCrawl + Firecrawl
The former leans toward full-pipeline capabilities and parameter flexibility, while the latter leans toward crawling ecosystem and web content output.
Conclusion
No tool is the absolute best—it's only about what fits your workflow:
- Beginners should first choose a solution that actually runs
- For Chinese content and social media, prioritize filling platform access gaps
- For cross-border Agents, intelligence gathering, structured data processing, or needing to interface with multiple search engines simultaneously, integrated solutions deserve focused attention
The key isn't pursuing "the strongest" but finding the tool combination that best matches your business scenario. As AI Agents rapidly evolve, the tool ecosystem continues to advance as well. It's recommended to periodically reassess your tool chain's effectiveness to ensure you're always using the most suitable solution for your current needs.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.