AI Agent Investment Research Showdown: ChatGPT vs. Kimi vs. Manus — Who Delivers Better Financial Analysis?

Kimi's Swarm Agent outperforms ChatGPT and Manus in investment analysis through multi-agent collaboration.
Using the same prompt, a tester had ChatGPT, Manus, and Kimi analyze the U.S. Magnificent Seven tech giants and deliver investment reports. Kimi's Swarm Agent produced a 76-page report closest to professional sell-side analyst standards, identifying the core tension between AI capital expenditure and monetization efficiency. Manus was fast but shallow and overly optimistic; ChatGPT had a solid framework but lacked depth. The decisive differentiator was multi-agent collaborative architecture enabling parallel task decomposition, cross-validation, and fault-tolerant recovery — the key to making AI Agents practically useful.
When AI Agents start challenging the work of professional financial analysts, who can deliver a truly in-depth investment research report? A Bilibili content creator named Lafei used the same prompt — spending nearly $60 in total — to have ChatGPT, Manus, and Kimi each tackle a high-difficulty task: conducting a deep analysis of the U.S. "Magnificent Seven" tech giants and delivering complete investment analysis documents. The differences in results were striking.
Task Setup: Same Prompt, Three AI Agents Head-to-Head
The test requirements were crystal clear: perform an in-depth investment analysis of the seven major U.S. tech giants and deliver three types of documents — a Word research report, an Excel data spreadsheet, and a PowerPoint presentation.
This is a classic sell-side analyst workflow. Sell-side analysts are core roles at investment banks and brokerage research departments, producing research reports for institutional investors. Their workflow typically includes: financial data modeling (DCF, relative valuation, etc.), industry research, management interviews, risk scenario analysis, and ultimately outputting research reports with explicit buy/sell ratings and price targets. A complete sell-side report often requires an analyst team to collaborate for days or even weeks, covering data collection, financial modeling, logical reasoning, and document writing. This is precisely why the test used "simultaneous delivery of Word, Excel, and PPT documents" as the evaluation criterion — this is the standard deliverable package in real sell-side research, testing not only the AI's information-gathering ability but also its analytical framework, logical reasoning, and professional judgment.
The three contestants were: ChatGPT's Deep Research feature, Manus, and Kimi's Swarm Agent. Both Manus and Kimi delivered complete multi-file outputs, while ChatGPT, limited by its model capabilities, only delivered a Word document.
Head-to-Head Comparison: Clear Quality Gaps Across Three Reports
Manus: Fastest Speed, Shallowest Depth
While Manus completed the task in the shortest time, its report quality ranked last among the three. The biggest issue was that it missed the most critical deep analysis report entirely, and even after being reminded, it only supplemented a document that merely listed opinions.
More critically, Manus exhibited a clear analytical bias — it defaulted to the assumption that "higher AI investment spending means faster future business growth," making its overall perspective overly optimistic. But even from a common-sense standpoint, we know you can't just look at who spends more money; what matters is whether that spending can be converted into revenue, profit, and free cash flow. These opinions lacked data support, merely listing projected 5-year revenue growth rates for each company — far from sufficient analytical depth.
Kimi Swarm Agent: The Closest to a Real Sell-Side Analyst
Kimi's Swarm Agent delivered a complete 76-page report that most closely approximated professional sell-side analyst standards. It was genuinely performing analysis rather than simply listing information.
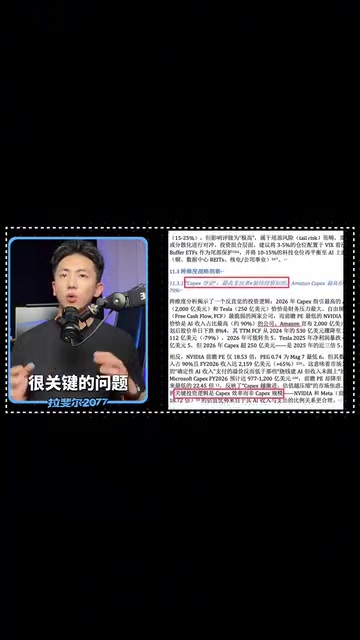
Kimi identified a critically important issue: increased AI capital expenditure does not necessarily translate to business revenue growth — what truly matters is whether these investments ultimately lead to improved monetization efficiency and free cash flow recovery.
Understanding this judgment requires some financial background: Capital Expenditure (CapEx) refers to spending on acquiring or upgrading fixed assets, which in the tech industry primarily manifests as data center construction, GPU procurement, and network infrastructure investment. In recent years, AI-related CapEx from tech giants like Microsoft, Google, Amazon, and Meta has exploded, collectively exceeding $200 billion in 2024. However, increased CapEx does not directly equal revenue growth — the key lies in the "investment return cycle" and "monetization pathway": how long the time lag is between CapEx and revenue conversion, how much free cash flow (FCF) gets compressed, and how visible the ROI is. Kimi's ability to identify this core contradiction demonstrates that its analytical framework approaches professional standards.
Additionally, Kimi broke down AI monetization pathways — not all companies are directly selling AI products; some are embedding AI into existing advertising, e-commerce, and cloud service ecosystems, making their existing businesses more profitable. This is far more insightful than simply saying "whoever has AI is better."
Regarding risk awareness, Kimi raised a noteworthy perspective: AI investment may transition from a "faith-driven" to an "evidence-driven" phase by 2026. This judgment has macro context: during 2023-2024, the AI investment wave was primarily supported by "narrative-driven" dynamics — the market was willing to pay high premiums for AI's future potential, even when near-term commercialization paths remained unclear. However, as major tech companies' AI CapEx continues to climb while monetization progress varies widely, institutional investors are beginning to demand clearer ROI evidence. Research reports from Morgan Stanley, Goldman Sachs, and other institutions have noted that 2025-2026 will be a critical window for AI investment's "delivery period." Kimi's judgment aligns closely with mainstream sell-side institutional views, demonstrating its accurate grasp of macro investment cycles — the market will no longer pay for stories alone but demands real returns.
However, Kimi also had notable shortcomings: total runtime exceeded one hour; short-term, medium-term, and long-term investment logic wasn't clearly delineated; and position-sizing recommendations lacked sensitivity analysis, jumping straight to conclusions.
ChatGPT: Solid Framework but Insufficient Depth
ChatGPT spent 20 minutes producing a relatively concise report. Its strengths were a stable framework and restrained conclusions — it wouldn't jump to excessive optimism like Manus.
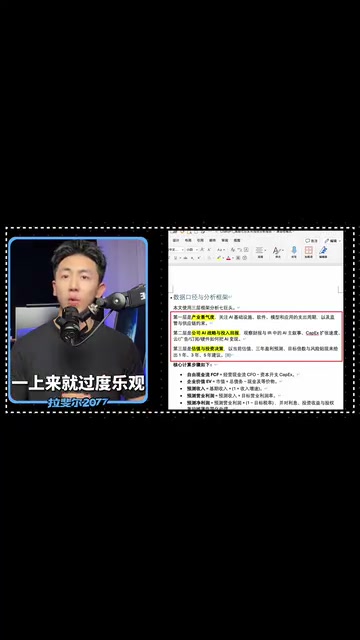
However, ChatGPT didn't live up to what its Deep Research feature should deliver. When it came to actually categorizing and individually analyzing seven companies, data support was insufficient and analysis wasn't deep enough. Overall, it felt more like a round of organizing publicly available information — suitable as a first draft for an investment memo, but still a considerable distance from a true deep analysis report.
The Core Gap: Multi-Agent Collaboration vs. Single-Agent Operation
After the horizontal comparison, the biggest differentiator came from the fundamental difference in parallel capabilities between multi-agent and single-agent systems.
Multi-Agent Systems (MAS) represent an important research direction in artificial intelligence, referring to computational frameworks where multiple autonomous agents collaborate to complete complex tasks. Unlike the linear reasoning of a single large model, MAS's core advantages include: parallel task decomposition (breaking complex tasks into parallelizable subtasks), role specialization (different Agents handling different functions such as data collection, analysis, and writing), and cross-validation (multiple Agents verifying the same conclusions to reduce hallucination risk). Leading organizations including OpenAI, Anthropic, and Google are all actively exploring Multi-Agent architectures.
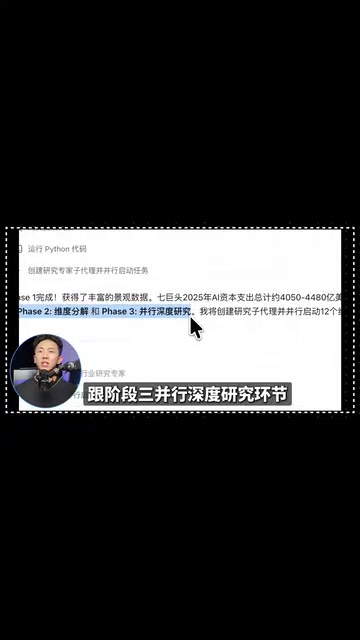
Kimi's Swarm Agent is an engineering implementation of this architecture — it's not simply spawning parallel clones to search web pages, but rather a multi-agent system with clear reporting lines, cross-validation capabilities, division of labor, and organizational structure. Specifically, its workflow breaks down into several key phases:
Phase 1: Data Collection. The Swarm Agent first collects required financial data from sources like Yahoo Finance.
Phase 2: Dimensional Decomposition and Parallel Research. Based on task requirements, it created three types of Agents — individual stock analysts, valuation analysts, and AI ecosystem analysts. When it determined that individual stock research could be parallelized, it immediately spawned 7 individual stock analysts to research the seven giants in parallel, while simultaneously spawning 2 valuation analysts and 2 AI ecosystem analysts working in relay.
Phase 3: Collaborative Writing and Delivery. Industry research experts and individual stock deep analysts worked in relay, linking breadth-first search with depth-first research, finally handing off to 8 writing agents to complete the 76-page report in parallel.
This is like a small research team working collaboratively — first dividing labor, then working in parallel, then consolidating — rather than one person writing from start to finish.
Fault Tolerance: Truly Practical Agents Must Be Self-Healing
An interesting detail emerged during testing: when generating the Excel file, the Swarm Agent encountered an error. But unlike many traditional Agents that freeze upon encountering an error or enter infinite loops on the same problem, it handled the situation gracefully.

Fault Tolerance is one of the core metrics for measuring AI Agent engineering maturity. In real-world workflows, Agents executing long-chain tasks inevitably encounter exceptions such as API call failures, code errors, and missing data. Low-maturity Agents typically freeze at the error point or enter infinite retry loops, causing the entire task to fail. Highly reliable Agent systems need to possess: error detection and isolation (identifying failed subtasks without affecting the overall flow), parallel recovery (continuing to advance other tasks while repairing the failed one), and graceful degradation (providing partially usable results when full repair isn't possible). This aligns with the "resilient design" principles in distributed systems engineering.
Kimi's Swarm Agent demonstrated exactly this kind of engineering-grade fault tolerance: while Excel repair continued on one track, it simultaneously generated the Word document and PPT report on another, ultimately delivering all three files together. This fault tolerance and parallel recovery capability is a key characteristic of Agents becoming practically useful.
Even more interesting: when the tester fed all three reports to ChatGPT for third-party evaluation, even ChatGPT acknowledged that Kimi's output most closely resembled a sell-side analyst's report and that it was "genuinely performing analysis."
Current Capability Boundaries of AI Agents
Despite Kimi's Swarm Agent delivering the best performance, it still falls short of truly professional investment report standards. Sensitivity analysis, scenario assumptions, and valuation derivation details still need more rigor, and the hour-plus runtime has room for optimization.
But this evaluation reveals an important trend: The value of AI Agents lies not in how smart a single conversation is, but in whether they can work autonomously over extended periods — decomposing tasks, dividing labor, self-correcting errors — and ultimately delivering results that can be directly integrated into workflows.
This is the agent form that enterprises truly want — not a smarter chatbot, but an AI team capable of collaborative work. Kimi is on the right track with its Agent approach: not just making models smarter, but transforming AI into an organization that can truly work collaboratively.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.