AI Coding Real-World Test: GPT-5, Gemini 2.5 Pro, Kimi K2, and Grok 4 All Fail at Web Scraping
AI Coding Real-World Test: GPT-5, Gemi…
Four top LLMs all fail at a static web scraping task while Claude maintains its lead with 126 pages
In an AI coding arena test, GPT-5, Gemini 2.5 Pro, Kimi K2, and Grok 4 were tasked with static web scraping using Cursor IDE—all four failed. Kimi K2 finished fastest but returned empty content, GPT-5 limited itself to 10 pages with empty body text, Grok 4 found zero links, and Gemini couldn't even handle a space in a file path. Meanwhile, Claude previously scraped 126 pages successfully, proving that parameter scale and brand recognition don't equal engineering execution capability.
Test Background
When it comes to real-world validation of AI coding capabilities, the actual performance of large language models often falls far short of their marketing claims. In this third episode of the AI Coding Arena series, the tester used the same IDE (Cursor international version) to compare GPT-5, Gemini 2.5 Pro, Kimi K2-0905, and Grok 4 on a static web scraping task.
About the Testing Tool: Cursor is an AI-native IDE built on a deep modification of VS Code. Its core feature is the direct integration of large language models into the code editing and terminal execution environment, with support for multi-model switching. In Cursor's Agent mode, models can not only generate code but also autonomously execute terminal commands, read/write files, and install dependencies, forming a complete "perceive-plan-execute" loop. This setup makes testing closer to real development scenarios and better exposes models' weaknesses at the engineering execution level—because errors are immediately executed with real consequences, rather than remaining at the code generation level.
About the Test Task: Static web scraping refers to data extraction from web pages where the server directly returns complete HTML content. Compared to dynamic scraping (which requires JavaScript rendering), it's theoretically less difficult. The core workflow includes: sending HTTP requests to fetch HTML documents, parsing the DOM tree using CSS selectors or XPath, extracting target content, and recursively following links. Common toolchains include Python's requests+BeautifulSoup or the Scrapy framework. This type of task serves as an excellent benchmark for AI coding assistants because it tests both code generation ability and the capacity to understand target website structure and debug effectively.
In previous tests, Claude successfully scraped 126 pages, setting the current benchmark. Could these four models surpass or at least match that result? The outcome was shocking—all of them failed.
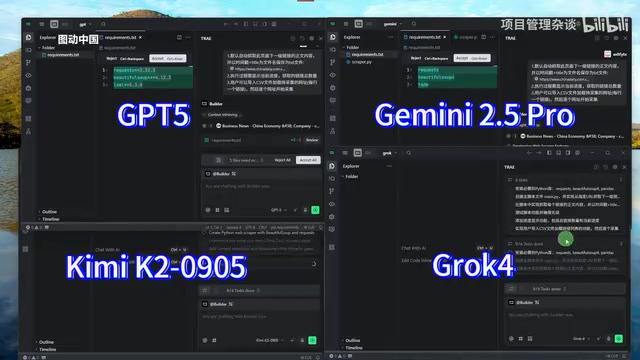
Execution Process Comparison of the Four Models
Notable Differences in Startup Speed
After receiving the same scraping requirements, the four models exhibited distinctly different execution strategies:
- Grok 4: Fastest to start, immediately began installing dependencies without first writing a requirements file, directly executing pip install
- Kimi K2: Impressively fast, quickly showing a Complete status
- GPT-5: Noticeably slow to start, running virtual environment configuration multiple times
- Gemini 2.5 Pro: Adopted a conservative strategy, insisting on waiting for the virtual environment to be fully installed before writing any code
Engineering Best Practices Context: Python virtual environments (venv/conda) are standard engineering practice for isolating project dependencies, preventing package version conflicts between different projects. The proper workflow is: first create a requirements.txt declaring dependencies, then batch install them in a virtual environment. Grok 4 skipping the requirements file to directly pip install, and Gemini 2.5 Pro serially waiting for the environment installation to complete before writing code, both violate engineering best practices. The former makes dependencies difficult to reproduce, while the latter wastes time that could be used for parallel processing—reflecting that these models' understanding of software engineering conventions remains superficial.
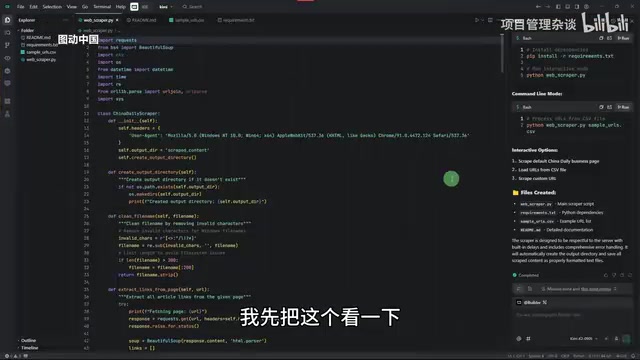
Specific Problems Each Model Encountered
Gemini 2.5 Pro ran into issues during the environment installation phase—it misidentified the file path because the path contained a space. This kind of basic error is inexcusable for a top-tier large language model. Its logic was also flawed: insisting on waiting for the virtual environment to finish installing before writing code, rather than handling tasks in parallel.
GPT-5 successfully initiated the scraping task but set the maximum page limit to 10, and ultimately all scraped content was empty—the body text was never successfully extracted.
Grok 4 performed even more absurdly—it not only installed a bunch of dependencies that are never normally needed, but inexplicably created a GUI interface. The final result showed "No Links Found"—not a single link was discovered.
Kimi K2 completed fastest, but upon opening the result file, all scraped body content was empty, making it effectively a failure as well.
Why Does "Empty Content" Occur? The "empty body text" issue appearing across multiple models typically stems from CSS selectors or XPath paths that don't match the target website's actual DOM structure. Modern websites often use semantic class names (like article__body, post-content) or deeply nested div structures. If a model fails to correctly analyze the target page's HTML structure, it will use incorrect selectors resulting in empty scraping results. Additionally, some websites use dynamically generated class names or lazy-loading mechanisms for content areas—even static pages may contain such pitfalls. The "empty content" problem with GPT-5 and Kimi K2 was most likely caused by selector targeting failures.
Web Scraping Test Results Summary
| Model | Execution Speed | Pages Scraped | Content Quality | Final Result |
|---|---|---|---|---|
| Claude (previous test) | Normal | 126 pages | Correct | ✅ Success |
| Kimi K2-0905 | Fastest | 13 pages | Body empty | ❌ Failed |
| GPT-5 | Slower | 10 pages (limited) | Body empty | ❌ Failed |
| Grok 4 | Fast | 0 pages | No content | ❌ Failed |
| Gemini 2.5 Pro | Slowest | 0 pages | No content | ❌ Failed |
Deep Analysis: Why Did They All Fail?
This test exposed several critical issues:
Insufficient Understanding of Web Page Structure
Static web scraping may seem simple, but it requires models to accurately understand the target website's DOM structure, link patterns, and content distribution. These four models clearly lack sufficient practical execution capability in this area.
Lack of Engineering Thinking
Gemini couldn't even handle a space in a file path, and Grok installed irrelevant dependencies while creating an unnecessary GUI. This demonstrates that these models still have very weak engineering judgment in real programming scenarios.
"Fast" Doesn't Mean "Good"
Kimi K2 finished fastest, but the results were all empty data. Speed advantages are meaningless in the face of quality failures.
Parameter Scale Doesn't Equal Engineering Execution Capability
There's a long-standing misconception in the industry: that larger parameter counts and more training data automatically translate to stronger coding ability. In reality, coding execution capability (especially for multi-step tasks in Agent mode) also heavily depends on the model's instruction-following ability, self-error-correction ability, and long-context memory capability. GPT-5, Grok 4, and similar models perform excellently on benchmarks (like HumanEval, SWE-bench), but these tests are typically single-shot code generation, which differs significantly from real engineering tasks requiring multiple rounds of tool calls and dynamic debugging. This is why "arena-style" real-world task testing is more valuable than benchmark scores.
Implications for Developers
This test result reminds us:
- Don't blindly trust a model's brand halo—actual task performance is the hard metric
- In AI-assisted programming, Claude currently maintains a clear advantage in code execution tasks
- Even the latest versions of top-tier models may underperform expectations on specific engineering tasks
- When choosing an AI coding assistant, you should test against your actual use cases
- There's a significant gap between benchmark scores and real engineering task performance—developers should prioritize real-world test data that closely mirrors their own business scenarios
Conclusion
The results of this arena test are quite ironic: four highly anticipated top-tier large language models all failed at a relatively basic static web scraping task, performing worse than Claude, which showed decent results in previous testing. This demonstrates that the competition in AI coding capability is far from settled, and a model's parameter scale and brand recognition don't directly translate into reliable coding execution power. For developers, the answer to "which model should I use" always needs to be verified through actual testing.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.