ChuanhuChatGPT: A Comprehensive Analysis of the 15K-Star Open-Source Multi-Model Chat Interface
ChuanhuChatGPT is an open-source AI chat interface supporting unified multi-model management.
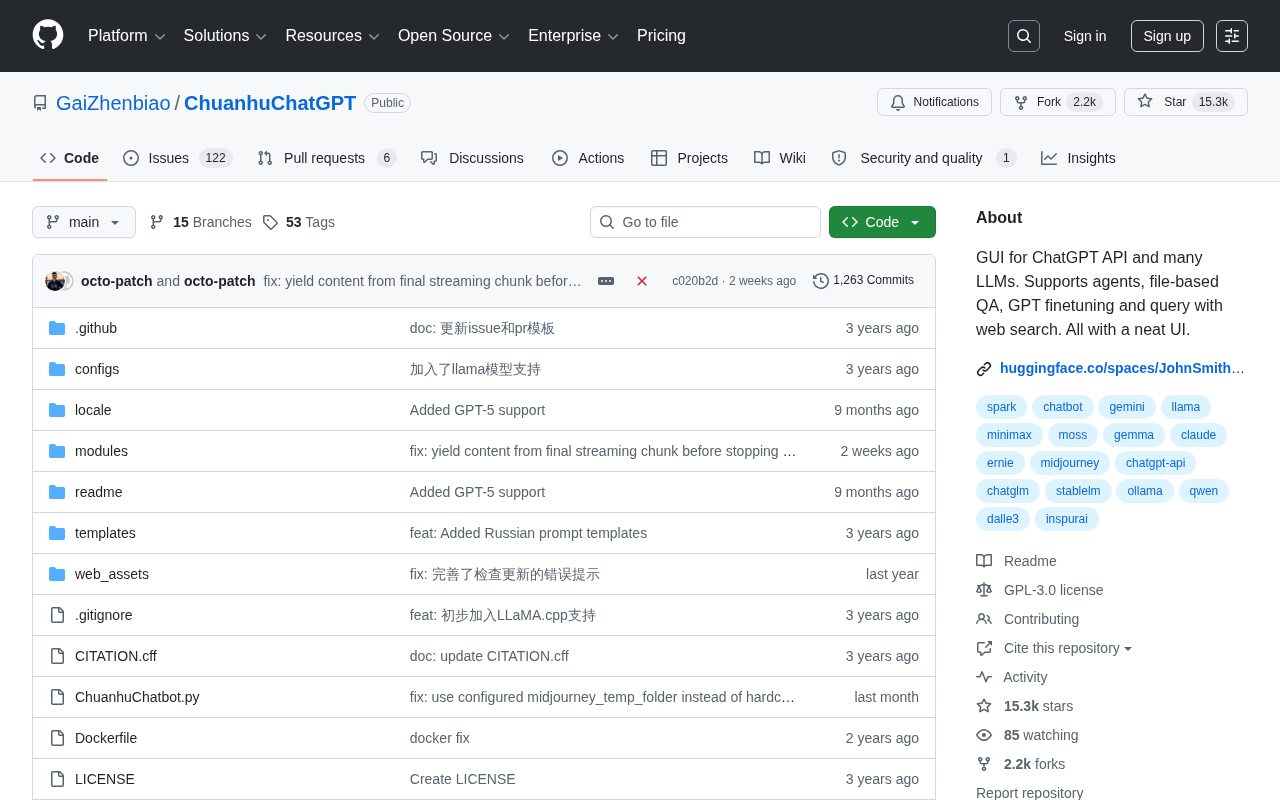
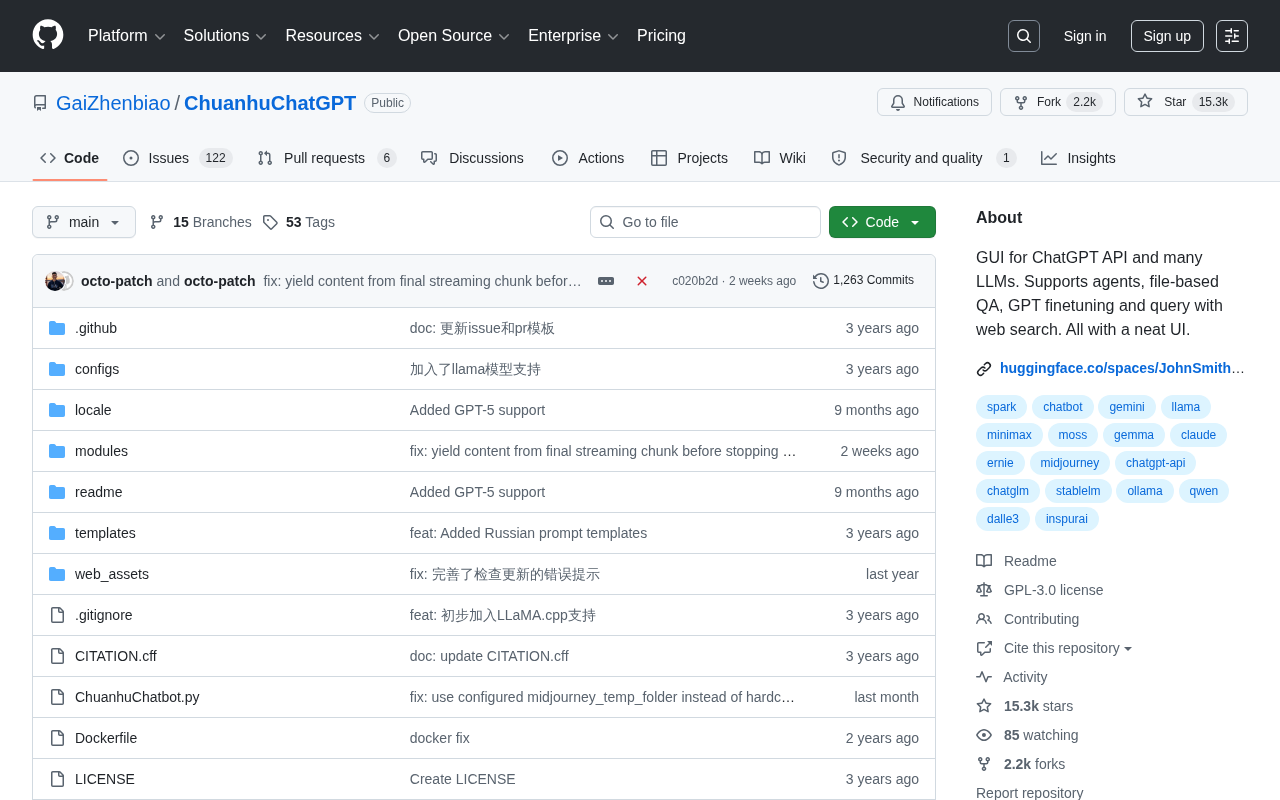
ChuanhuChatGPT is a 15K+ Star open-source project on GitHub, built with Python and Gradio, providing a unified interface for accessing multiple LLMs. Core features include multi-model comparison, Agent support, RAG-based file Q&A, GPT fine-tuning, and web search integration. It serves individual users, developers, researchers, and enterprise teams, and is one of the most popular ChatGPT GUI tools in the Chinese-speaking community.
Project Overview: What Is ChuanhuChatGPT?
In an era where large language models (LLMs) are flourishing, having a unified, elegant interface to manage and use multiple AI models has become a pressing need for many developers and everyday users. Large Language Models (LLMs) are deep learning models based on the Transformer architecture, pre-trained on massive text datasets. Since Google published the seminal paper Attention Is All You Need in 2017, introducing the Transformer architecture, the parameter scale of language models has rapidly grown from hundreds of millions to hundreds of billions or even trillions. Representative models such as the GPT series (OpenAI), Claude (Anthropic), LLaMA (Meta), and Gemini (Google) each have their own strengths, varying in reasoning capability, context window length, multilingual support, and more. This "hundred flowers blooming" landscape means users often need to work with multiple models simultaneously, driving strong demand for a unified management interface.
ChuanhuChatGPT is precisely such an open-source project — it has earned over 15,300 Stars on GitHub, making it one of the most popular ChatGPT graphical interface tools in the Chinese-speaking community.
Initiated by developer GaiZhenbiao and built with Python, the project supports not only the ChatGPT API but also a wide range of mainstream LLMs. It offers comprehensive capabilities spanning from basic conversations to advanced features such as Agent support, file-based Q&A, model fine-tuning, and web search.
Core Features of ChuanhuChatGPT in Detail
Unified Multi-Model Access
The standout feature of ChuanhuChatGPT is its "unified multi-model management" design philosophy. Users don't need to switch between different tools — a single interface lets them call OpenAI GPT series models, Claude, locally deployed open-source models, and more. This design significantly lowers the barrier to entry and is especially useful for researchers and developers who need to compare outputs across different models. In practice, different models show notable performance differences across tasks like code generation, creative writing, logical reasoning, and Chinese language comprehension. The unified interface allows users to quickly run side-by-side comparisons using the same prompts, helping them choose the optimal model for specific tasks.
Agent Support
The project includes built-in Agent functionality, allowing models to invoke external tools and execute multi-step reasoning tasks during conversations. Agents are one of the hottest research directions in AI today. The core idea stems from the "ReAct" (Reasoning + Acting) paradigm — enabling LLMs not only to perform text-based reasoning but also to interact with the real world by calling external tools such as search engines, code interpreters, and database query interfaces. A typical Agent workflow includes: perceiving the task objective → formulating an execution plan → calling tools step by step → observing intermediate results → dynamically adjusting strategy → producing the final answer. Frameworks like LangChain, AutoGPT, and CrewAI are all driving the standardization of Agent capabilities.
Users can have AI do more than just "chat" — it can actually complete complex tasks like automatically retrieving information, processing data, and generating reports. The addition of Agent capabilities elevates ChuanhuChatGPT from a simple chat interface to an AI workstation with a degree of autonomy, transforming LLMs from passive "Q&A machines" into "digital workers" capable of independently completing multi-step complex tasks.
File-Based RAG Q&A
In real-world work scenarios, users frequently need to ask questions based on specific documents. ChuanhuChatGPT supports uploading files and directly querying their contents. Under the hood, it combines text chunking and vector retrieval (RAG) technologies, enabling the model to precisely locate relevant content within documents and provide answers.
RAG (Retrieval-Augmented Generation) is a technical framework proposed by Meta AI in 2020, designed to address the "hallucination" problem and knowledge timeliness issues of LLMs. Its working principle involves three core steps: First, uploaded documents are split into appropriately sized segments through text chunking strategies. Second, embedding models (such as OpenAI's text-embedding-ada-002 or the open-source BGE series) convert these text segments into high-dimensional vectors, which are stored in vector databases (such as FAISS, Chroma, or Milvus). Finally, when a user asks a question, the system vectorizes the query, retrieves the most relevant document segments through similarity search, and injects these segments as context into the LLM's prompt, guiding the model to generate answers based on actual document content. This "retrieve first, generate second" approach significantly improves answer accuracy and traceability.
This feature is highly practical in scenarios such as academic research, legal document analysis, and technical documentation review.
GPT Fine-Tuning
The project also integrates GPT fine-tuning functionality, allowing users to perform customized model training through the graphical interface without writing complex training scripts. Fine-tuning refers to further training a pre-trained large model using labeled data from a specific domain or task, enabling the model to better adapt to target scenarios. OpenAI's fine-tuning API allows users to upload training data in JSONL format to customize models like GPT-3.5-turbo or GPT-4. The core value of fine-tuning lies in the fact that, compared to pure prompt engineering, fine-tuning enables the model to internalize domain knowledge and output styles. During inference, it can produce expected results without lengthy system prompts, while also reducing token consumption per call. Additionally, the open-source community has developed parameter-efficient fine-tuning methods such as LoRA (Low-Rank Adaptation) and QLoRA, making it possible to fine-tune models with billions of parameters on consumer-grade GPUs.
For teams looking to adapt general-purpose large models to specific domains (such as healthcare, finance, or education), this is a very user-friendly entry point.
Web Search Integration
LLMs have inherent knowledge timeliness limitations — for example, a model with training data cut off in 2023 cannot answer questions about events in 2024. ChuanhuChatGPT addresses this by integrating web search functionality, enabling the model to access real-time information and combine search results with its responses, effectively compensating for the information lag caused by training data cutoff dates. This feature is typically implemented through search API calls (such as Google Search API, Bing Search API, or the open-source SearXNG). The system injects search result summaries into the model's context, enabling it to reason and respond based on the latest information.
Technical Architecture and Design
Frontend Interface: Custom Development Based on Gradio
ChuanhuChatGPT builds its frontend interface using the Gradio framework. Gradio is an open-source Python library maintained by Hugging Face, designed specifically for rapid prototyping and interactive demonstrations of machine learning models. Developers can create web interfaces with input/output components in just a few lines of Python code, supporting multiple data types including text, images, audio, and video. Gradio is built on FastAPI and Svelte under the hood, with the frontend using WebSocket for real-time streaming output — which is crucial for the token-by-token generation experience of LLMs. Over 300,000 demo projects on the Hugging Face Spaces platform are built with Gradio, making it the de facto standard demo framework in the AI field.
The project has undergone extensive customization on top of Gradio, creating a clean and attractive interactive interface that supports conversation history management, multi-session switching, theme switching, and more. However, since Gradio was originally designed for rapid prototyping rather than production-grade frontend applications, it falls somewhat short in UI customization flexibility and visual polish compared to modern frontend frameworks like React/Next.js — an inherent challenge for ChuanhuChatGPT's frontend experience.
Backend Architecture: Modular Python Implementation
The backend is implemented entirely in Python, using a modular design to decouple API calls for different models, file processing, search integration, and other functionalities. The advantage of this architectural approach is that adding support for new models only requires implementing a unified interface adapter layer without modifying core logic. The project has over 2,200 Forks, with active community contributors continuously adding new model support and feature optimizations. As the dominant language in the AI/ML field, Python's rich ecosystem (including libraries like LangChain, LlamaIndex, and Transformers) provides natural convenience for extending ChuanhuChatGPT's capabilities.
Use Cases and Target Users
ChuanhuChatGPT is suitable for the following user groups:
- Individual users: Those who want to use the ChatGPT API through an attractive interface, paying per usage (based on actual token consumption) rather than the $20/month ChatGPT Plus subscription — especially for infrequent users, API call costs can be as low as one-tenth of the subscription fee
- Developers: Those who need to quickly test and compare outputs from different LLMs, evaluating model performance differences on specific tasks
- Researchers: Those leveraging the file Q&A feature for literature analysis or using the fine-tuning feature for experiments to quickly validate research hypotheses
- Enterprise teams: Can be privately deployed in intranet environments, enjoying multi-model capabilities while ensuring sensitive data doesn't leak, meeting data compliance requirements
ChuanhuChatGPT vs. Similar Open-Source Projects
In the open-source ChatGPT interface tool space, ChuanhuChatGPT faces competition from projects like ChatGPT-Next-Web, LobeChat, and Open WebUI. ChatGPT-Next-Web is built on Next.js (a React framework) with a frontend-backend separated architecture, offering smooth frontend experiences and PWA (Progressive Web App) offline support, with extremely convenient deployment to platforms like Vercel. LobeChat, also based on Next.js, is known for its plugin-based architecture and polished UI design, supporting a rich plugin ecosystem and multimodal interactions. Open WebUI (formerly Ollama WebUI) focuses on managing and using local open-source models, deeply integrated with the Ollama runtime. The differences in technology stack choices among these projects directly influence their respective strengths: the JavaScript/TypeScript ecosystem has advantages in frontend interaction experience and cross-platform deployment, while the Python ecosystem excels in AI/ML toolchain integration and backend extensibility.
In comparison, ChuanhuChatGPT's core advantages include:
- Feature comprehensiveness: Integrates advanced features like Agents, fine-tuning, file Q&A, and web search, rather than offering only basic conversations
- Chinese community friendliness: Project documentation and community discussions are primarily in Chinese, making it more accessible to users in China
- Python ecosystem: Built on Python, making it convenient for AI/ML practitioners to perform secondary development and feature extensions, with direct integration of mainstream AI libraries like LangChain and Transformers
However, in terms of frontend experience polish and deployment convenience, Next.js-based projects (like ChatGPT-Next-Web) may have a slight edge — they can be deployed to Serverless platforms like Vercel with one click, while Python projects typically require server environment configuration.
Conclusion and Future Outlook
With over 15K Stars, ChuanhuChatGPT has demonstrated strong market demand for a "unified multi-model interface." As the large model ecosystem continues to evolve — from pure text conversations to multimodal understanding, from single-turn Q&A to complex Agent workflows, from cloud APIs to on-device deployment — the value of such tools will become even more pronounced. If the project continues to advance in multimodal support (image understanding and generation, voice interaction), richer Agent toolchains (such as integration with emerging standards like the MCP protocol), and enterprise-grade deployment solutions (user permission management, audit logs, load balancing), it has the potential to become a key piece of infrastructure in the AI application layer.
For developers looking to quickly build a private AI assistant, ChuanhuChatGPT is a high-quality open-source project well worth exploring and trying out.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.