Claude Haiku 4.5 Real-World Test: Failed All 5 Programming Tasks
Claude Haiku 4.5 fails all 5 complex visual programming tasks in systematic testing
A Bilibili creator tested Claude Haiku 4.5 on multiple visual programming tasks including elephant toothpaste animation, 3D roller coaster, firecracker chain explosions, and cup pouring simulation. The model performed poorly across all dimensions—3D modeling, performance optimization, library references, physics logic, and instruction following—making it unsuitable for complex programming tasks.
Test Background
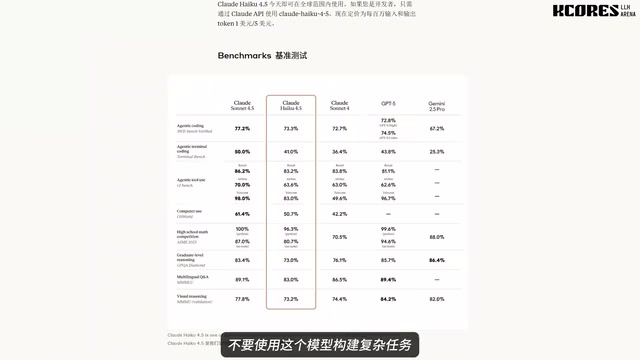
Claude Haiku 4.5 is Anthropic's economy-tier model, marketed for low cost and fast response times. Anthropic's model family is divided into three tiers by capability—Opus, Sonnet, and Haiku—with Haiku positioned for high-throughput, low-latency, cost-sensitive use cases. Its API pricing is significantly lower than the same-generation Sonnet model, targeting large-scale batch processing and budget-conscious developers. But does "cheap and generous" mean quality compromises? A Bilibili content creator systematically tested it through multiple visual programming tasks, with disappointing results.
Elephant Toothpaste Test: Modeling and Performance Both Failed
The first test was a classic "elephant toothpaste" simulation animation. Claude Haiku 4.5 exposed two core problems:
- Erlenmeyer flask modeling error: The model failed to correctly understand and generate the 3D geometry of an Erlenmeyer flask, showing insufficient basic modeling capability
- Eruption animation performance issues: The generated animation code had severe performance bottlenecks, running extremely laggy and nearly unplayable

This shows that Claude Haiku 4.5 lacks both accurate spatial geometry understanding and the ability to generate performance-optimized code for physics simulation and 3D rendering. In particle system animations, performance optimization typically involves object pooling, reducing per-frame DOM operations, and proper use of requestAnimationFrame—none of which the model's generated code considered.
Roller Coaster Test: 3D Library References Broke Immediately
The roller coaster test ended in outright failure. Claude Haiku 4.5's generated code had Three.js reference issues and couldn't run directly. Three.js is a WebGL-based JavaScript 3D graphics library and the de facto standard for web 3D visualization. Correct usage requires handling scene, camera, and renderer initialization, as well as CDN reference paths and module import methods. Common issues with AI-generated code include incorrect reference paths and version API incompatibilities.
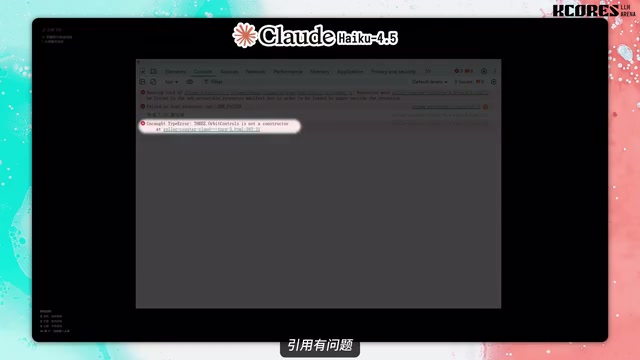
The animation only worked after manual fixes, meaning in real development scenarios, code from this model requires significant human intervention and debugging—actually increasing development costs and defeating the purpose of AI-assisted programming.
Firecracker Chain Explosion Test: Zero Logic Understanding
The firecracker chain explosion test examines the model's understanding of causal logic and physical interactions. Results were extremely poor: all 6 attempts failed to achieve a chain explosion effect.
This isn't an occasional failure but a systematic capability gap. The model couldn't understand the basic chain reaction logic of "one firecracker exploding triggers adjacent firecrackers to explode." Implementing chain explosions requires understanding collision detection, event propagation, and state machine transitions, then combining them into a complete causal chain—demands that exceed this lightweight model's reasoning capabilities.
Python Cup Pouring Test: Poor Instruction Following

In the Python particle simulation cup pouring test, Claude Haiku 4.5's performance was rated "the worst." Specific problems included:
- Failed to follow instruction timing: The test required waiting for all particles to finish generating before rotating the cup; the model didn't follow this explicit instruction
- Geometry modeling error: Added a sealed top to the cup, preventing particles from entering—completely defeating the task objective
This exposes two deeper issues: first, insufficient instruction following capability—a core LLM evaluation metric referring to the ability to strictly execute tasks according to user-specified constraints including timing and conditional logic; second, flawed understanding of physical world common sense—a cup needs an opening to hold water, which is the most basic knowledge.
Overall Evaluation and Recommendations
Capability Score Summary
After multi-dimensional testing, Claude Haiku 4.5's performance on complex programming tasks:
| Capability | Rating |
|---|---|
| 3D modeling understanding | Poor |
| Code performance optimization | Poor |
| Library reference accuracy | Poor |
| Physics logic reasoning | Very Poor |
| Instruction following | Poor |
Recommendations
Do not use Claude Haiku 4.5 for any complex visualization or physics simulation tasks. While its API pricing is low, the failure rate on complex tasks is extremely high, and the time spent debugging far exceeds any cost savings.
This model may only be suitable for simple text processing, basic Q&A, and other lightweight tasks. For scenarios involving code generation, logical reasoning, or spatial understanding, use Claude Sonnet 3.5 or higher-tier models. The "cheap and generous" claim doesn't hold here—you save on token costs but waste developer time.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.