Claude Opus 4.8 Deep Dive: A Comprehensive Review of Judgment, Honesty, and Cost-Effectiveness
Claude Opus 4.8 Deep Dive: A Comprehen…
Claude Opus 4.8 delivers pragmatic gains in judgment, honesty, and sustained work capability
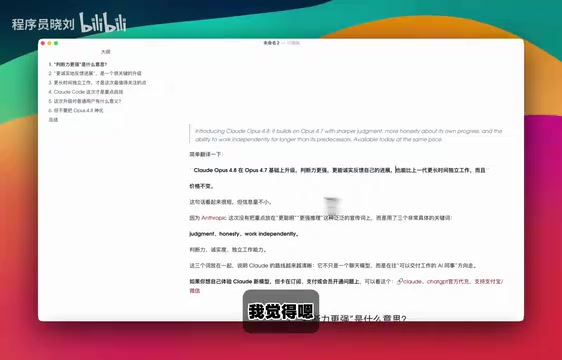
Anthropic releases Claude Opus 4.8 with unchanged pricing but Fast Mode costs reduced to one-third. Core improvements span three areas: enhanced judgment enabling complex tasks with short prompts; optimized honest feedback reducing hallucinations and ineffective outputs; and significantly extended independent work duration through the 1M context window and xhigh thinking mode. Overall, this is a pragmatic iteration rather than a revolutionary breakthrough.
Anthropic recently released the Claude Opus 4.8 model. As the latest iteration in the Opus series, this update isn't simply about stacking more parameters—it delivers pragmatic enhancements in judgment capability, honest feedback, and sustained independent work duration. This article provides an in-depth analysis of the upgrade's real-world value across three dimensions: pricing strategy, core capability improvements, and competitive comparisons.
Pricing Strategy: Same Price, Dramatically Lower Fast Mode Costs
Opus 4.8 maintains the same pricing as its predecessor 4.7, staying at $15 per million input tokens and $75 per million output tokens (approximately ¥35/million input tokens).
About Token Pricing Mechanisms: Large model pricing uses "per million tokens" as the unit of measurement. Tokens are the basic units a model uses to process text—roughly speaking, 1 English word equals about 1-1.5 tokens, and 1 Chinese character equals about 1.5-2 tokens. Input tokens (prompt) and output tokens (completion) are priced separately, with output prices typically much higher than input—because generating text requires the model to perform autoregressive inference, which is far more computationally intensive than encoding input. Opus 4.8's input/output price ratio is 1:5, which is fairly typical for high-end models and directly reflects the actual cost structure of inference computation.
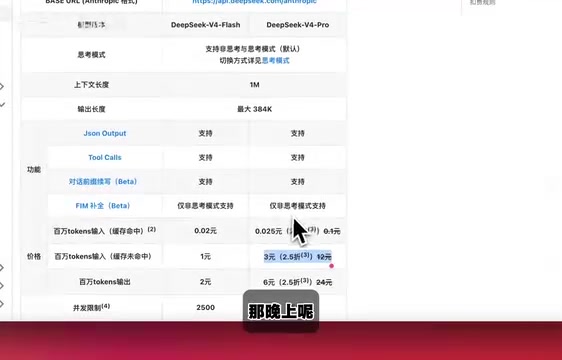
In absolute terms, this positions it at the premium end of the current LLM market—the same budget could fund approximately 11 calls to DeepSeek V4, or 35 calls to DeepSeek V4 Turbo.

However, what truly deserves attention is the cost change in Fast Mode. Anthropic claims this mode now costs one-third of what it previously did—in other words, the same budget allows you to ask three times as many questions in Fast Mode. This is a substantial benefit for everyday lightweight query scenarios, meaning users can significantly reduce costs in situations that don't require deep reasoning.
From a cost-effectiveness perspective, if your use cases primarily involve simple Q&A and rapid iteration, the DeepSeek series remains the more economical choice. But if you need to handle complex programming tasks or long-context reasoning, Opus 4.8's comprehensive capabilities may be worth the investment.
Core Capability Improvements: Not Stronger, but More "Stable"
A Qualitative Leap in Judgment
Opus 4.8's most significant advancement isn't reflected in benchmark scores, but in a dramatically lower "error rate" during actual use. Specifically: complex tasks that previously required carefully crafted long prompts can now be accurately understood with short, concise prompts.
About Prompt Engineering: Prompt Engineering refers to the technical practice of carefully designing input text to guide large models toward desired outputs. Earlier models were extremely sensitive to prompt formatting and wording—subtle differences in expression could lead to drastically different results, spawning specialized techniques like "few-shot prompting" and "Chain-of-Thought prompting." Improved model judgment is essentially enhanced robustness in understanding user intent—the ability to accurately infer task objectives even when input information is incomplete or ambiguously expressed. This kind of improvement typically comes from larger-scale RLHF (Reinforcement Learning from Human Feedback) training and higher-quality alignment data.
This means the model has achieved fundamental improvements in semantic understanding and task decomposition. For developers, this directly lowers the barrier to prompt engineering—you no longer need to spend significant time "teaching" the model to understand your requirements. Instead, you can express intent more naturally and let the model infer the correct execution path on its own.
Optimized Honest Feedback Mechanism
Another important improvement is the model's "honesty" when processing tasks. In previous versions, the model would sometimes generate outputs that appeared reasonable but were actually ineffective, requiring users to repeatedly verify before discovering issues. Opus 4.8 has made targeted optimizations in this area, providing more candid feedback about its processing progress—including clearly indicating which parts are complete and which parts involve uncertainty.
About AI Hallucination and Honesty: The "hallucination" problem in large language models refers to the phenomenon where models generate content that appears plausible but is actually incorrect or fabricated—one of the most critical reliability challenges in current AI systems. The root cause lies in the model's training objective: predicting the probability distribution of the next token, rather than verifying factual accuracy. Anthropic lists "Honesty" as a core value in its model alignment research, encompassing dimensions like non-deception, non-manipulation, and calibrated uncertainty. Opus 4.8's improvement in honest feedback is the engineering implementation of this alignment direction—enabling the model to proactively express uncertainty when uncertain, rather than forcibly generating an answer with artificially inflated confidence.
This improvement is particularly critical for AI programming scenarios. When the model encounters uncertain logic while generating code, rather than "hard-coding" an implementation that might contain bugs, it's better to explicitly flag it for developer intervention. This "knowing what you know and knowing what you don't know" attitude actually significantly improves overall development efficiency.
Extended Independent Work Duration
Combined with the 1M context window and xhigh thinking mode, Opus 4.8 can independently complete complex tasks over longer periods without requiring frequent user intervention for course correction. This is an important breakthrough for scenarios requiring sustained reasoning, such as large-scale code refactoring and long document analysis.
About Context Windows and Long-Range Reasoning: The context window determines the maximum number of tokens a model can process in a single conversation. 1M tokens equals approximately 750,000 English words—equivalent to a complete novel or tens of thousands of lines of code. However, ultra-long context doesn't equal ultra-strong reasoning—research shows that most models experience significantly reduced utilization of information in middle positions once context exceeds a certain length, known as the "Lost in the Middle" phenomenon. The xhigh thinking mode mitigates this issue to some extent by extending the model's internal reasoning chain (Extended Thinking), enabling more stable attention allocation across long contexts and thereby supporting more sustained independent work capability.
Competitive Landscape Comparison
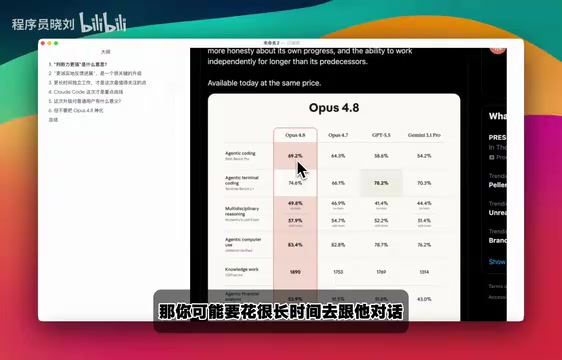
Based on publicly available benchmark results, Opus 4.8 has taken another step up from GPT-5.5 in AI Coding performance. However, it's important to note that benchmark results and actual user experience often diverge.
About the Limitations of AI Coding Benchmarks: Current mainstream AI programming benchmarks include HumanEval, SWE-bench, LiveCodeBench, and others that evaluate coding ability by having models solve standardized programming problems or real GitHub Issues. However, benchmark problems typically have clear boundaries and standard answers, while real engineering problems often involve ambiguous requirements, legacy code, and cross-file dependencies. Additionally, as model training data may include benchmark problems, "data contamination" issues are gradually reducing the reference value of high scores. Therefore, when interpreting benchmark comparisons like "surpassing GPT-5.5," one should consider the specific test set design and real-world use cases holistically, rather than treating them as absolute capability rankings.
The LLM competition has entered a new phase: pure capability improvements are no longer sufficient to create differentiated advantages. Users care more about model stability and reliability in real-world scenarios. From this perspective, Opus 4.8's focus on "stability" and "judgment" rather than blindly chasing benchmark scores is a remarkably pragmatic strategy.
A Rational Perspective: Pragmatic Enhancement, Not Revolutionary Breakthrough
In summary, the Claude Opus 4.8 upgrade can be captured in three key phrases:
- More stable judgment: Complex tasks achievable with short prompts, lowering the usage barrier
- More honest feedback: Reduced ineffective outputs, improved human-AI collaboration efficiency
- More sustained independent work: Long context + deep thinking mode, suitable for complex projects
There's no need to deify Claude—it hasn't fundamentally changed everything. But as a pragmatic iterative upgrade, Opus 4.8 genuinely addresses pain points from the previous generation's real-world usage while maintaining the same price point. For heavy AI programming users and professionals who need to handle complex long-text tasks, this upgrade deserves serious evaluation.
For individual developers with limited budgets, we recommend first experiencing the Fast Mode price reduction benefits. For enterprise users, the combination of xhigh thinking mode with the 1M context window may deliver significant efficiency gains in complex projects.
Key Takeaways
- Claude Opus 4.8 pricing remains unchanged from 4.7, but Fast Mode costs drop to one-third of previous levels
- Core improvement lies in enhanced judgment—short prompts can now accomplish complex tasks that previously required lengthy prompts
- Improved honest feedback mechanism reduces ineffective outputs and provides more candid progress reporting
- Independent work duration significantly extended, with 1M context and xhigh thinking mode suited for complex projects
- AI Coding benchmarks surpass GPT-5.5, but this represents pragmatic enhancement rather than revolutionary breakthrough
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.