Claude Opus 4.8 Hands-On: What Can You Build in One Hour?
Claude Opus 4.8 Hands-On: What Can You…
Claude Opus 4.8 quietly launches; hands-on tests show limited improvements in code and creativity.
Claude Opus 4.8 launched claiming improved judgment and honesty, but hands-on testing reveals underwhelming results. For coding, a Mario game required multiple iterations to become playable, and a card game took over an hour to develop with frequent bugs. Creative writing showed no noticeable improvement over version 4.6. Max mode quota consumption is extremely high, severely disrupting development continuity. The Codex planning + Claude Code implementation workflow shows potential but suffers from poor handoffs—overall a minor tune-up rather than a breakthrough.
Opus 4.8 Quietly Goes Live
Claude Opus 4.8 was officially released in the early hours recently. Anthropic claims it offers sharper judgment and greater honesty about its own progress compared to Opus 4.7.
About the Claude Opus iteration logic: Anthropic's Claude models use a tiered naming system—Haiku (lightweight and fast), Sonnet (balanced), and Opus (flagship). The Opus series represents Anthropic's strongest reasoning and creative capabilities at any given time. Minor version iterations (e.g., 4.7→4.8) typically fine-tune specific dimensions rather than overhauling the entire architecture. Anthropic invests heavily in model safety and "honesty," with its Constitutional AI methodology requiring models to maintain accuracy in self-awareness—which is why Opus 4.8 emphasizes "improved honesty." However, the fact that it incorrectly reported its own identity during actual testing creates a rather ironic contrast.
That said, the "honesty" thing seems a bit overcorrected—when someone tested it via API and asked what model it was, it alternately claimed to be Qwen and DeepSeek, behaving quite erratically. Fortunately, Anthropic has already fixed this bug in the client.
Opus 4.8 is now fully available and can be used directly in both the client and Claude Code, with the default model being Opus 4.8 Hi. You might not have noticed, but using Max mode is not recommended because the quota consumption is extremely high—the tester burned through 2% of their quota just by asking "what model are you?"
Why Max mode is so "quota-hungry": Claude's Max mode essentially invokes a longer context window and deeper reasoning configuration, potentially consuming several times or even tens of times more tokens than standard mode. The Claude Opus series sits at a higher pricing tier among mainstream LLMs (approximately $15 per million input tokens), and complex code generation tasks can consume tens or even hundreds of thousands of tokens per call. This explains why a single conversation burned 2% of the monthly quota. For scenarios requiring extended continuous development, the token limit mechanism forcibly interrupts workflows—this is one of the major friction points for AI programming tools in engineering practice.
Classic Mario Game Test
First Attempt Failed, Retry Yielded Decent Results
The first test was a channel staple—having AI create a Mario mini-game. The first attempt was a complete failure with a blank screen. The retry showed significant improvement: the pixel art for monsters and characters was quite detailed, and zooming in revealed the classic "M" icon on the character's head, with sound effects added as well.
However, bugs persisted: some terrain was impossible to jump over, pipes displayed incorrectly, and the background map moved along with jumps. After feedback about the map issue, the AI spent another ten minutes thinking before delivering the final product.
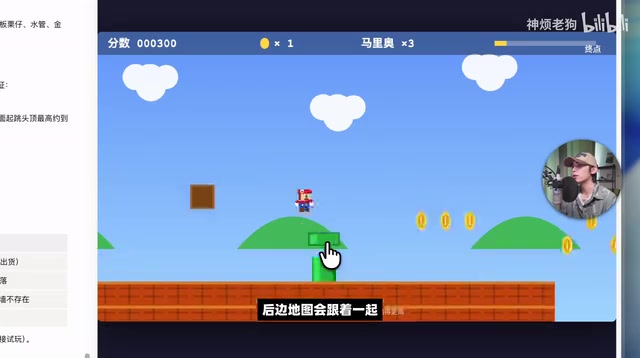
Overall, the generation quality for single-file mini-games is acceptable, but human feedback and multiple iterations are still needed to reach a basically playable state.
Card Game Development in Practice
Codex Planning + Claude Code Development Collaboration
The second test was more ambitious: creating a card game in the style of Slay the Spire.
Design complexity of Slay the Spire and Roguelike card games: Slay the Spire was officially released in 2019 and pioneered the fusion of Roguelike and Deck-Building game paradigms, subsequently becoming a popular reference for indie game developers and AI code generation tests. Its core mechanics include: randomly generated route branches, a node system of battles-shops-events, card upgrades and relic combinations for build crafting, and the signature Roguelike permadeath mechanic. This system's complexity far exceeds a Mario side-scroller, involving state management, numerical balancing, UI interaction, and randomization algorithms across multiple engineering dimensions—making it an ideal scenario for testing the upper limits of AI code generation.
Since Claude itself cannot generate images, the tester first spent half an hour using Codex to generate digital assets (backgrounds, maps, character sprites, etc.), then handed everything to Claude Code for game development.
The division of labor between Codex and Claude Code: OpenAI Codex and Anthropic Claude Code represent two different product forms of current AI programming assistants. Codex leans more toward task planning, code framework generation, and multi-step engineering decomposition, with stronger project-level vision; Claude Code excels at terminal integration, file operations, and iterative fixes, making it better suited for executing specific coding tasks within existing frameworks. The tester's approach of "Codex for planning assets + Claude Code for coding implementation" essentially simulates the "architect + developer" collaboration model in software engineering, complementing the relative strengths of both models. This kind of multi-model collaborative workflow (Multi-Agent Workflow) is becoming a new trend in AI-assisted development, but context transfer between models and task handoff overhead remain major bottlenecks.
This process exposed several issues:
- Image slicing disaster: Claude split complete sprite sheets in half when processing assets, producing "shattered" results. Codex ultimately had to redo the image slicing.
- Quota bottleneck: At the 16-minute mark of development, the 5-hour quota was exhausted, requiring a wait for quota recovery before continuing.
- Total time exceeded one hour: Between 34 minutes of actual coding time, the previous 20 minutes, and waiting periods, the entire process took over an hour.
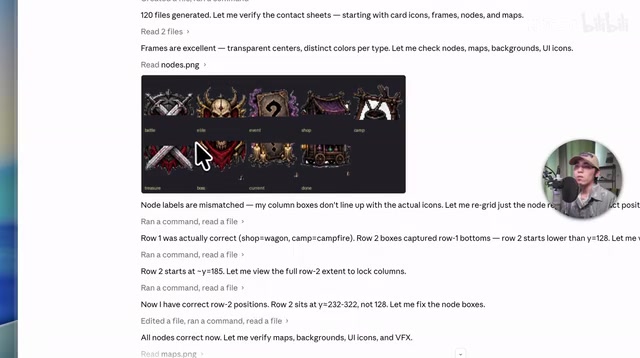
Final Product: Looks the Part but Riddled with Issues
The game ultimately ran, and the overall "feel was quite authentic"—featuring character selection, route branching, a combat system, event triggers, shops, and campsites—all the complete elements of a Roguelike card game.

But issues were frequent during actual gameplay:
- Unresponsive click bug: After selecting a character, clicking "Confirm Expedition" did nothing. Claude encountered the same issue during its own testing and even admitted "I used the console to directly call the function to bypass it"—an honest but exasperating answer.
- UI display issues: Some templates were missing, card information wasn't properly placed within frames, and bottom image slicing still had flaws.
- Numerical imbalance: The tester quickly died due to insufficient HP—elite monsters had 92 HP compared to the player's 10 HP, with virtually no balance whatsoever.
The tester admitted that if the entire project had been handed to Codex alone, the results might have been better, since Codex did the planning in the first place.
Beyond Code: Copywriting and Creative Abilities
Search and Evaluation Capabilities
The tester also tried non-code scenarios. When asking Opus 4.8 to search for and critique a content creator, the search tool's content skewed toward current affairs, finance, and tech, with some information blocked by anti-scraping mechanisms, resulting in inaccurate evaluations. However, the AI's "sharp-tongued" commentary style had a certain flair.
Novel Writing Test
Asking Opus 4.8 to write an "infinite flow" novel with the tester as the protagonist yielded mediocre results.
Infinite flow and AI creative writing evaluation dimensions: Infinite flow (无限流) is a genre originating from Chinese web fiction, with the core premise of a protagonist traversing different film, game, or historical worlds to complete missions, blending isekai elements, dungeon-crawling, and system mechanics. This genre tests AI creative capabilities in several ways: maintaining worldview consistency, narrative coherence across scenes, and self-consistent character ability system design. The tester's assessment that Opus 4.8's writing is "about the same as 4.6" points to a common bottleneck in current large language models for creative writing—scaling model size yields higher marginal returns for reasoning and code capabilities than for literary creativity and stylistic uniqueness. Evaluating AI creative writing lacks objective quantitative metrics and is highly subjective, which is why conclusions from such tests often vary from person to person.
The AI designed an ability called "personal LLM with internet access"—allowing the protagonist to summon an AI assistant in their mind to answer any question. The concept was reasonably creative, but the tester rated it "about the same as Opus 4.6, no improvement," and didn't notice the obvious verbal tics previously seen in ChatGPT.

Summary: An Unremarkable Iteration
The tester's summary was quite blunt: "a bit boring" and "unremarkable." Specifically:
- Code capabilities: Can complete complex projects but bugs are frequent, requiring extensive manual intervention and multiple rounds of fixes
- Quota consumption: Max mode consumption is excessive, and even standard mode easily hits limits, severely impacting development continuity
- Creative capabilities: No noticeable improvement over 4.6/4.7, performance is mediocre
- Collaboration model: The division of labor with Codex handling planning and assets while Claude Code handles coding shows some viability, but handoffs are still not smooth enough
As the tester self-deprecatingly noted, this isn't a video deliberately showcasing good results—it's an honest record of the "current experience." The Opus 4.8 upgrade feels more like a minor tune-up than an exciting leap forward. For users hoping for a qualitative breakthrough in AI programming capabilities, the wait continues.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.