Claude Sonnet 4.5 vs GPT-5 Codex: A Hands-On Soft-Body Physics Programming Showdown

Claude Sonnet 4.5 and GPT-5 Codex face off recreating classic soft-body physics game in C++
A tech YouTuber pitted Claude Sonnet 4.5 against GPT-5 Codex to recreate the 1996 classic game Terep 2's soft-body physics driving effects in C++. Testing revealed Claude excels at visual presentation and terrain generation with faster responses, while GPT-5 delivers superior physics calculations and soft-body deformation. Neither model's initial code compiled successfully, both required multiple iterations, and both struggled with physics parameter tuning — resulting in no clear winner.
A Hardcore AI Programming Showdown
Now that AI coding assistants can easily build web apps, a more interesting question emerges: can they handle truly hardcore programming tasks? A Chinese tech YouTuber recently published a highly technical comparison test, pitting Anthropic's newly released Claude Sonnet 4.5 against OpenAI's GPT-5 Codex high-performance model in a head-to-head battle. The task: recreate the soft-body physics driving simulation from the 1996 classic game Terep 2 (Deformers) in C++.
This classic game was famous for its stunning soft-body physics vehicle deformation effects, which remain impressive even by today's standards. The brilliance of choosing this task lies in its complexity: it requires not just graphics rendering, but the coordinated work of multiple complex subsystems — mass-spring physics, terrain generation, collision detection, and more — making it far more challenging than typical web development tests.
C++ in Practice: From Compilation Errors to Barely Running
Initial Code Generation Phase
The tester used identical prompts, asking both models to create a game in C++ featuring soft-body physics, simple vehicle deformation, and an off-road track, generating all necessary files. Claude was set to thinking mode (Sonnet 4.5), GPT-5 Codex was set to high-performance mode, and both were kicked off simultaneously.
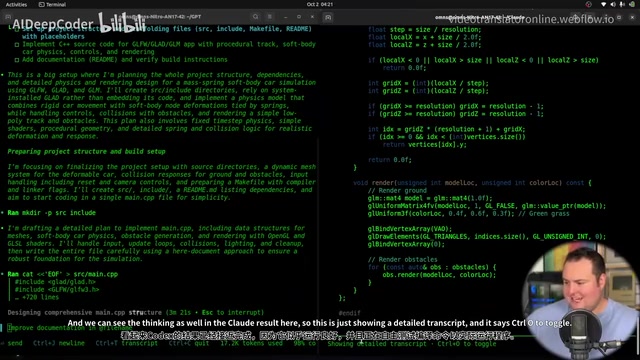
Both models quickly began planning their project structures. Claude's output was noticeably more thorough — not only generating extensive code but also helpfully explaining how to handle different Linux distributions. Codex demonstrated a methodical approach to designing the C++ mass-spring physics system. However, neither model's initial code could compile and run directly; both hit dependency and compilation errors.
Iterative Fix Process
The tester pasted error messages back to each model, letting them fix their own issues rather than searching for solutions the traditional way. This setup was crucial — it simulated a real-world scenario where an amateur developer relies entirely on an AI coding assistant.
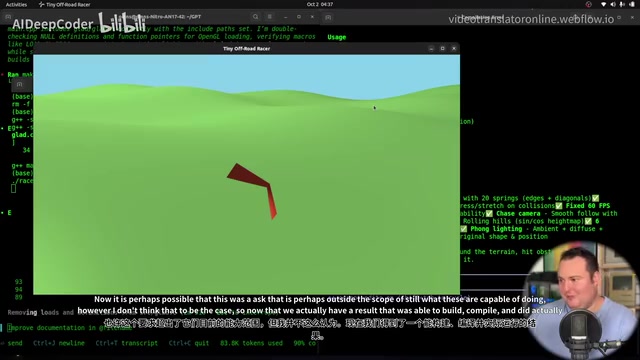
After multiple rounds of fixes, both models produced compilable, runnable programs, though the initial results were underwhelming:
- Claude Sonnet 4.5: Decent terrain rendering with an off-road feel, but the vehicle shape was subpar and movement controls didn't work
- GPT-5 Codex: WASD vehicle controls worked, but terrain rendering had issues
The tester admitted disappointment that neither model could draw a decent vehicle model, especially since in browser-based JS tests, they could at least render basic vehicle shapes.
Final C++ Results Comparison
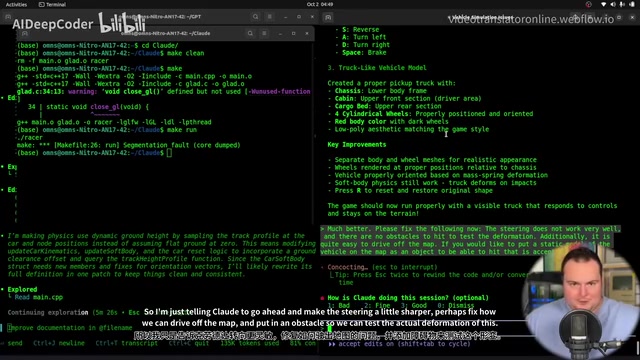
After further feedback iterations, both models showed significant improvement:
- Claude's strengths: Superior terrain with peaks and valleys, better suited for off-road tracks; vehicle correctly followed terrain contours; faster working speed and quicker bug fixes
- Codex's strengths: Better vehicle model; more pronounced soft-body physics effects with the vehicle bouncing like jelly, closer to the Terep 2 tech demo feel
Switching to Web Tech Stack: JS and HTML Performance
Out of curiosity, the tester had both models complete the same task using HTML, JS, and CSS. As expected, development with the web tech stack was much faster, with Claude finishing first once again.
Interestingly, regardless of programming language, both models exhibited similar bug patterns:
- Claude's web version: Terrain and graphical style looked great, but improperly tuned spring forces caused the vehicle to constantly sink into the ground or shake apart explosively. Even after four iterations, it couldn't perfectly balance drivability and physics stability
- Codex's web version: Delivered what was arguably the best result across all four tests — the soft-body physics deformation was impressive, and the way the vehicle deformed on impact closely resembled the feel of the original game
Key Findings and In-Depth Analysis
Programming Capability Profiles of Both Models
This test revealed distinct differences in programming capabilities between Claude and GPT-5:
Claude Sonnet 4.5 excels at UI polish and overall visual presentation, generates more natural terrain, provides more thorough code documentation, and responds faster. However, it struggled with physics parameter tuning, failing to balance the spring system's various parameters even after multiple iterations.
GPT-5 Codex may have the edge in mathematical and physics calculations, producing more realistic soft-body deformation effects and more reasonable collision responses. However, it fell slightly short in visual polish and terrain design.
Implications for Developers
You might not have noticed, but the tester specifically emphasized that Sonnet is not Anthropic's top-tier model (that would be Opus), and considering this, Sonnet 4.5's performance was already quite impressive. This hints at an important trend: AI coding assistants are rapidly evolving from "can build web pages" to "can handle complex systems-level programming."
That said, this test also exposed several current limitations of AI programming:
- Physics parameter tuning remains a challenge: Both models struggled to balance spring forces, damping coefficients, and other parameters
- Cross-language consistency issues: Similar bugs appeared in both C++ and JS implementations, indicating the problems stem from algorithmic understanding rather than language-specific issues
- Human feedback loops are still necessary: Neither model could produce usable results on the first try; both required multiple iterations
Conclusion: No Clear Winner, But Each Has Its Strengths
This Claude vs GPT-5 programming showdown is hard to call with a definitive winner. If you prioritize development efficiency and visual quality, Claude Sonnet 4.5 is the better choice; if you care more about physics simulation accuracy and mathematical computation, GPT-5 Codex might be more suitable.
For everyday developers, the more important signal is this: AI coding assistants can now handle fairly complex graphics and physics programming tasks in systems-level languages like C++. While the results are far from perfect, considering this was a from-scratch process requiring almost no manual coding, the progress is exciting enough.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.