Context Mode: How One MCP Plugin Cured AI Coding Assistants' Amnesia
Context Mode: How One MCP Plugin Cured…
Open-source plugin Context Mode solves AI coding assistants' context amnesia via sandbox isolation and external memory
AI coding assistants like Claude Code frequently "forget" due to context windows being stuffed with tool outputs. Turkish developer Mert K. Esolou's open-source project Context Mode solves this through three mechanisms: sandbox isolation that keeps raw data out of context (saving 99%+), SQLite+FTS5 external memory for session continuity, and a "Thinking in Code" philosophy where AI writes scripts instead of ingesting data. The project earned nearly 10,000 Stars in two months, proving AI needs better resource management, not bigger context windows.
Claude Code's "Amnesia" and an Open-Source Solution
You're coding along with Claude Code when it suddenly asks: "What were we working on again?" The architecture you spent half an hour building? Gone from its memory. This problem that plagues countless developers was solved by a Turkish developer with a single MCP plugin—racking up 9,700 Stars in two months and hitting #1 on Hacker News.
Today we'll dissect this project called Context Mode and examine what it got right.
The Root Cause: The Context Window Is Stuffed with Garbage
Claude Code has a 200K token context window. Sounds massive, but in practice it's far from enough.
What is a context window? A large language model's "context window" refers to the maximum text length the model can process in a single inference pass, measured in tokens. Tokens aren't equivalent to characters or words—in English, one token corresponds to roughly 4 characters; in Chinese, one character typically maps to 1-2 tokens. Claude's 200K token window translates to approximately 150,000 English words, or about 300 pages of A4 documents. However, this "brain capacity" is shared: system prompts, tool definitions, conversation history, and tool outputs all compete for the same space. When the window approaches its limit, the model triggers automatic compaction, replacing earlier conversations with summaries—this is the direct cause of "amnesia."
Once you install a few commonly used MCP servers, context consumption becomes alarming: a Playwright screenshot eats 56KB, pulling 20 GitHub Issues consumes 59KB, a single log file takes 45KB. After 30 minutes, 40% of your context is gone.
What is MCP? MCP (Model Context Protocol) is a standardized protocol open-sourced by Anthropic in late 2024, designed to solve the fragmentation problem of integrating AI models with external tools and data sources. Before MCP, every AI application needed custom adapters for Slack, GitHub, databases, etc., with enormous maintenance costs. MCP defines a unified client-server architecture: the AI model acts as the client, various tools expose capabilities as MCP Servers, and both sides communicate via standardized JSON-RPC protocol. This design is analogous to USB port standardization—any tool that conforms to the spec can plug and play. Context Mode operates as a "middleware" layer within the MCP ecosystem, inserting interception and compression logic into the tool call pipeline.
Worse still, when the system automatically compresses conversations to free up space, it forgets which file you're editing, where you are in the task, and what you last asked it to do. Project author Mert K. Esolou puts it bluntly: After installing commonly used MCPs, 70% of your context is consumed before you even start working.

This is the root cause of AI coding assistants' "amnesia"—it's not that the model isn't smart enough, it's that we've stuffed too much garbage data into its brain.
Three Core Mechanisms: Sandbox Isolation, Session Continuity, and Thinking in Code
Sandbox Isolation: Raw Data Never Enters the Context
Context Mode's first core design is sandbox isolation. Every tool call is intercepted via a Pre-tools hook and executed in an isolated subprocess. Only the distilled output enters the conversation context—raw data never pollutes your context window.
How dramatic are the results? Playwright screenshots save 99%, access logs save 100%, and a 7.5MB JSON API response ends up using only 0.9KB. This isn't micro-optimization—it's orders-of-magnitude compression.
Session Continuity: Giving AI an External Memory
Context Mode's second core capability is session continuity tracking. It tracks 26 types of events: file reads/writes, Git operations, task status, error messages, user decisions—all stored in a SQLite database.

Why SQLite? SQLite is the world's most widely deployed embedded relational database, with core advantages of zero configuration, single-file storage, and no need for a standalone service process. Context Mode's choice of SQLite over Redis or PostgreSQL is a pragmatic engineering decision—it allows the entire memory system to travel with the project directory, requiring no infrastructure dependencies.
When conversations are compressed, it indexes events into the FTS5 search engine, uses the BM25 algorithm to retrieve only relevant content, and generates a Session Guide of no more than 2KB. With this Guide, the model can continue working from exactly where you left off.
What are FTS5 and BM25? FTS5 (Full-Text Search 5) is SQLite's built-in full-text search extension module, supporting inverted indexes, prefix search, and custom tokenizers. BM25 (Best Match 25) is a classic ranking algorithm in information retrieval, an improved version of TF-IDF that calculates document-query relevance scores by considering term frequency saturation and document length normalization. Compared to simple keyword matching, BM25 more accurately finds the "most relevant" rather than "most keyword-dense" content fragments.
Its search engine isn't simple keyword matching either—it runs two search strategies simultaneously, merges rankings using Reciprocal Rank Fusion, and includes proximity re-ranking, typo correction, and intelligent snippet extraction.
What is Reciprocal Rank Fusion? RRF is a fusion algorithm that merges multiple ranked lists into a single ranking, first proposed by Cormack et al. at the 2009 SIGIR conference. Its core idea is elegantly simple: for each document, take the reciprocal of its rank in each list and sum them—higher scores mean higher final rankings. The formula is: RRF(d) = Σ 1/(k + rank_i(d)), where k is typically set to 60 as a smoothing constant. RRF's advantage is robustness against anomalous rankings—even if one subsystem produces an erroneous high ranking, it won't have a decisive impact on the final result. In Context Mode, it's used to fuse semantic search and keyword search results, balancing semantic similarity with exact matching.
In plain terms, it builds a mini search engine on top of your tool outputs. This architecture is essentially a lightweight RAG (Retrieval-Augmented Generation) system—rather than stuffing all knowledge into the context window, it maintains an externally searchable knowledge base and retrieves on demand during inference. Context Mode chose the lightweight SQLite+FTS5 combination, sacrificing some semantic understanding capability in exchange for zero dependencies, low latency, and easy local deployment.
Thinking in Code: Scripts Replace Data Dumping
The third design philosophy is "Thinking in Code"—if you need to analyze data, have the AI write a script to do it, rather than stuffing raw data into the context.

Wrong approach: Read 50 files into context and ask the AI to count functions.
Right approach: Have the AI write a script to count them itself, console.log the results. One script replaces 10 tool calls, saving 100x context.
This is an enforced rule across all 12 platforms that Context Mode supports. This design philosophy reveals a deeper truth: AI coding assistants should think like programmers—solving problems with tools, not brute-forcing with memory.
Community Feedback and Real Boundaries
The project scored over 570 points on Hacker News and hit #1, but community feedback wasn't unanimously positive.
The sharpest criticism: someone installed Context Mode to call the Obsidian MCP, and the response went straight into the context—not a single thing was intercepted. The author responded candidly: The 98% savings primarily apply to built-in tools; third-party MCPs indeed can't be intercepted—this is a boundary you need to know about.
This honesty actually increases the project's credibility. In the open-source community, acknowledging limitations earns more trust than exaggerating capabilities.
A One-Person Open-Source Miracle
Mert K. Esolou, the creator of this project, is a Turkish senior engineer with 10 years of experience. He maintains the entire project solo—writing code, documentation, fixing bugs, responding to issues—all by himself.
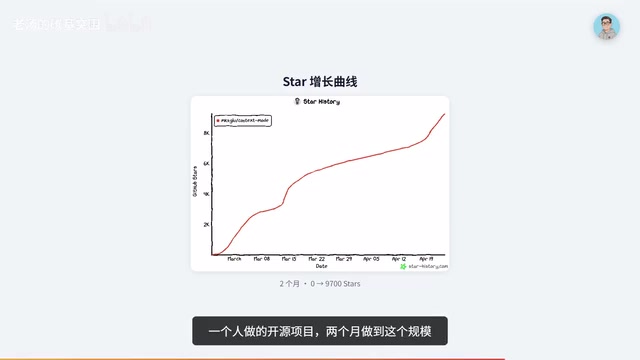
Look at the Star growth curve: created in late February, approaching 10,000 stars by April. Ranked #29 globally on PulseMP, with 13,000 new visitors per week. Enterprise users listed in the README include Microsoft, Google, Meta, Amazon, NVIDIA, and ByteDance. A one-person open-source project reaching this scale in two months is nothing short of miraculous.
Relationship with Competitors: Subtraction vs. Organization
Context Mode and Claude Code's built-in Compact feature don't conflict—they're complementary:
- Compact: Compresses tool definitions, creates semantic summaries, but loses details
- Context Mode: Compresses tool outputs, doesn't summarize but indexes—data is preserved, it just doesn't occupy your window
One does subtraction, the other does organization. Subtraction loses things; organization doesn't.
AI Doesn't Need a Bigger Brain—It Needs an External Hard Drive
Returning to the original question: AI assistants' amnesia isn't fundamentally about the model not being smart enough—it's about how we use them. Context Mode's approach is: Don't stuff it into the brain; build an external hard drive and look things up when needed.
This is actually how humans process information—we don't memorize entire dictionaries, but we know how to look things up. This is also precisely why RAG architecture dominates enterprise AI applications: a model's parametric memory is static and limited, while external retrieval systems are dynamic and scalable.
As AI coding tools become more widespread, context management will become an increasingly important infrastructure layer. Context Mode's success proves a simple truth: sometimes the most valuable innovation isn't making models more powerful, but making them use existing resources more efficiently.
If you use Claude Code or other AI coding tools daily, Context Mode is absolutely worth trying.
Key Takeaways
- Context Mode's sandbox isolation mechanism executes raw tool call data in subprocesses, with only distilled output entering the context, achieving over 99% context savings
- Session continuity tracking captures 26 event types stored in SQLite, using FTS5 search engine and BM25 algorithm to generate a Session Guide under 2KB, solving memory loss after conversation compaction
- The "Thinking in Code" philosophy has AI write scripts to analyze data rather than dumping it into context—one script can replace 10 tool calls, saving 100x context
- The project is maintained by a single Turkish developer, gaining nearly 10,000 Stars in two months, with enterprise users including Microsoft, Google, Meta, and other tech giants
- Context Mode complements Claude Code's built-in Compact feature—the former does "organization" (indexes without losing data), the latter does "subtraction" (summaries lose details)
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.