Costco Research Automation Agent Hands-On: One-Click Reproduction of Eigenfaces from Paper to Code
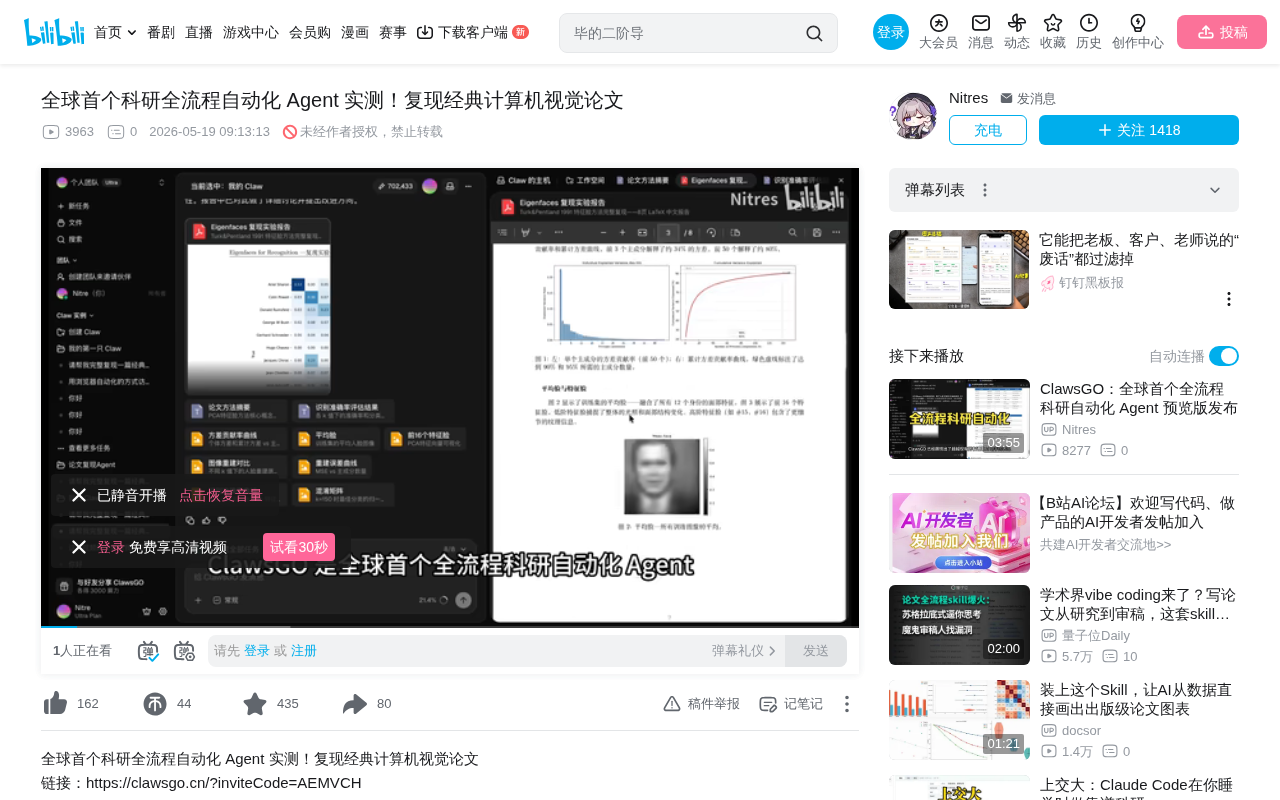
Research automation Agent Costco tested: independently completing the full loop of classic paper reproduction
A Bilibili creator tested Costco, claimed to be the world's first end-to-end research automation Agent, with the task of reproducing the classic 1991 Eigenfaces paper. The Agent independently completed paper understanding, code implementation, model training, experimental evaluation, and LaTeX paper delivery, validating the original paper's core conclusion (50 principal components suffice for recognizable face reconstruction). However, while the Agent excels at reproduction tasks, it remains far from capable of original research.
Introduction: A New Milestone in Research Automation
When AI Agents move beyond just helping you write code or search literature, and can independently complete the entire research loop from problem formulation to paper delivery, the paradigm of research work is undergoing a fundamental shift. The AI Agent discussed here differs from traditional conversational AI tools (like ChatGPT) or code completion tools (like Copilot) in its core capabilities of autonomy and task decomposition. Traditional tools are passively responsive—users ask, AI answers. An Agent, however, possesses goal-oriented planning capabilities, able to decompose complex tasks into sub-task sequences, autonomously determine execution order, self-correct when encountering errors, and coordinate work across multiple tools and environments. This architecture is typically based on the ReAct (Reasoning + Acting) paradigm or similar chain-of-thought reasoning frameworks, enabling the Agent to progressively advance task completion through observe-think-act loops.
Costco—claimed to be the world's first end-to-end research automation Agent—is attempting to realize this vision.
Recently, a Bilibili content creator conducted a hands-on test of Costco, with the task of reproducing a foundational classic in computer vision: the Eigenfaces paper published by Turk and Pentland in 1991. This paper holds landmark status in computer vision and pattern recognition—prior to it, face recognition primarily relied on hand-designed geometric features (such as eye distance, nose width, etc.), while the Eigenfaces method was the first to demonstrate that global feature representations based on statistical learning could be effectively used for face recognition. This work directly inspired subsequent subspace methods including Fisherfaces (based on LDA), Laplacianfaces, and others, laying the theoretical foundation for face recognition in the deep learning era. The paper has been cited over 15,000 times to date and remains essential reading for understanding the evolution of modern face recognition technology.
The core idea of the paper is to use PCA (Principal Component Analysis) to reduce the dimensionality of face images, extracting so-called "eigenfaces," so that any face can be represented as a linear combination of these eigenfaces. PCA is a classic unsupervised linear dimensionality reduction method whose core idea is to transform a set of possibly correlated variables into a set of linearly uncorrelated variables (i.e., principal components) through orthogonal transformation, with these components ordered by decreasing variance. Mathematically, PCA is equivalent to eigenvalue decomposition of the data covariance matrix, or singular value decomposition (SVD) of the data matrix. For face images, a 64×64 pixel grayscale image can be viewed as a point in 4096-dimensional space, and PCA can find the directions of maximum data spread in this high-dimensional space, thereby representing images with far fewer dimensions than the original while preserving the most critical structural features.
Costco's Workflow: Completing the Research Loop in Six Steps
Step 1: Paper Understanding and Method Extraction
Upon receiving the task, Costco first read the original paper and accurately extracted the core methodology of PCA dimensionality reduction and eigenface reconstruction. This step is equivalent to a researcher's literature review phase—understanding the research problem and grasping the technical approach. The Agent's ability to precisely locate core algorithm descriptions from dozens of pages of academic text itself demonstrates its deep comprehension of scholarly writing.
Step 2: Code Implementation and Data Preparation
Costco then wrote complete Python code, loading face images from Scikit-learn's built-in datasets and completing image alignment and preprocessing. Scikit-learn is one of the most widely used machine learning libraries in the Python ecosystem, and its built-in Olivetti Faces dataset (the AT&T face database) contains 10 different 64×64 grayscale face images each of 40 individuals under varying conditions. The existence of such standardized datasets is critical infrastructure for research reproducibility—it ensures different researchers experiment on the same data, making results comparable. It's worth noting that the Replication Crisis is a major challenge facing academia today; according to a 2016 Nature survey, over 70% of researchers have attempted to reproduce others' experiments but failed, which is one reason automated reproduction tools hold significant value.
This step involves multiple data engineering details: data loading, format conversion, normalization, etc., all completed independently by the Agent without human intervention.
Step 3: Model Training and Eigenface Visualization
After PCA training was completed, Costco generated visualizations of the eigenfaces. When the eigenvectors corresponding to the principal components are reshaped back into images, they present blurry face contours—this is precisely the origin of the name "Eigenfaces." These ghost-like faces actually capture the directions of maximum variance in face images and serve as the fundamental features for face recognition. Specifically, the first eigenface captures the pattern of greatest variation across all training faces (typically related to lighting direction), while subsequent eigenfaces capture the most significant patterns in the remaining variance, such as facial contour differences and feature proportion variations.
Step 4: Experimental Evaluation and Results Analysis
In the evaluation phase, Costco systematically tested the impact of different numbers of principal components on reconstruction quality, incrementing from 10 to 200, and recorded the reconstruction error curve. The experimental results validated the core findings of the original paper:
- 50 principal components: Already sufficient to reconstruct recognizable faces
- 100+ principal components: Reconstruction results are virtually indistinguishable from the originals
This conclusion powerfully demonstrates that face image representation in the PCA subspace is efficient and compact—high-dimensional image data contains substantial redundant information, and a small number of principal components can capture the vast majority of useful information. From an information theory perspective, this means the intrinsic dimensionality of face images is far lower than their pixel dimensionality, and facial variations are actually constrained to a low-dimensional manifold. This finding is significant not only for face recognition but also provided important experimental evidence for later work in manifold learning, sparse representation, and related directions.
Step 5: Paper Writing and Deliverable Submission
Finally, Costco delivered a complete research output package:
- A reproduction report in LaTeX format
- All Python experimental code
- Eigenface visualizations
- Reconstruction comparison images with different numbers of principal components
- A directly compilable PDF document
LaTeX is a high-level wrapper around the TeX typesetting system developed by Turing Award winner Donald Knuth, and is the de facto standard for academic paper writing in mathematics, physics, computer science, and related fields. Unlike WYSIWYG editors such as Word, LaTeX uses a markup language approach where authors write source code to describe document structure and content, which is then compiled into the final PDF. Its advantages include beautiful mathematical formula typesetting, standardized reference management, and strong cross-platform consistency. The Agent's ability to generate compilable LaTeX documents means its output can be directly integrated into academic workflows without manual reformatting—a substantive improvement in research efficiency.
Where Are the Boundaries of Agent Research Capabilities?
The Benchmark Value of Reproducing Classic Papers
Choosing Eigenfaces as the test task was a smart choice. This paper has clear methods, publicly available datasets, and well-defined evaluation metrics, making it an ideal benchmark for validating Agent research capabilities. However, we must objectively recognize that this falls under "clear methodology, well-defined implementation path" reproduction tasks, which remain fundamentally different from truly innovative research.
From a research methodology perspective, there exists an important capability gap between replication and original research. The core challenge of replication work lies in accurately understanding and faithfully implementing existing methods—its path is deterministic. Original research, on the other hand, requires making judgments under uncertainty—which direction to explore, how to interpret anomalous results, when to abandon a technical approach. This ability to make creative decisions amid ambiguity remains a core advantage of human researchers.
Current Limitations and Future Outlook
The real challenges for end-to-end research automation Agents lie in:
- Innovative problem formulation: Can they discover new research problems rather than reproducing existing work? Scientific discoveries often stem from keen observation of anomalous phenomena or creative connections between knowledge from different domains, requiring Agents to possess genuine understanding capabilities beyond pattern matching.
- Experimental design flexibility: Can they adjust experimental plans when facing unexpected results? In real research, experimental failures and unexpected discoveries are the norm, and researchers need to dynamically adjust strategies based on intermediate results, or even completely change research directions.
- Cross-disciplinary knowledge integration: Can they creatively combine methods from different fields? Many breakthrough achievements come from interdisciplinary crossover—such as applying physics methods to biology problems, or transferring mathematical theoretical frameworks to engineering domains.
Currently, Costco performs excellently on the "reproduction" dimension, but remains a considerable distance from replacing researchers in conducting original research. However, from the perspective of technological development trends, as large language model reasoning capabilities continue to improve, multimodal understanding capabilities strengthen, and interaction with external tools becomes more refined, the roles that Agents can assume in research assistance will continue to expand.
Conclusion
Based on the hands-on results, Costco indeed demonstrates impressive end-to-end research automation capabilities. The entire loop—from paper reading, method extraction, code implementation, experimental validation, to deliverable submission—was completed independently by the Agent, offering significant practical value for research assistance, teaching demonstrations, and rapid prototype validation scenarios.
For researchers, the greatest value of such tools may not lie in replacing thinking, but in automating repetitive implementation work, allowing human researchers to devote more energy to the phases that truly require creativity. Just as calculators didn't replace mathematicians but freed them from tedious calculations to think about deeper problems, the ultimate positioning of research automation Agents may be as efficient collaborative partners for researchers, rather than replacements.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.