Cursor + Claude 3.7 Sonnet Coding Test: Four Side-by-Side Comparisons Reveal Stunning Improvements
Cursor + Claude 3.7 Sonnet Coding Test…
Claude 3.7 Sonnet shows leapfrog coding improvements over 3.5 in systematic Cursor front-end tests.
A content creator systematically tested Claude 3.7 Sonnet's front-end programming capabilities in Cursor across web page replication, login page design, and React SPA tasks. Compared to 3.5, version 3.7 demonstrated leapfrog improvements in requirement understanding depth, UI aesthetic quality, multimodal recognition precision, and context processing — generating complex projects with complete interactions in a single pass, signaling AI programming's evolution from code completion assistant to full-stack development partner.
Introduction: What Makes Claude 3.7 Sonnet So Much Better?
Claude 3.7 Sonnet, as the first hybrid reasoning model, has been called Claude's most intelligent and powerful coding model to date. "Hybrid reasoning" means the model possesses two capability modes simultaneously: fast intuitive reasoning and deep logical reasoning. Traditional large language models use a single forward reasoning approach, receiving input and directly generating output. Claude 3.7 Sonnet, however, integrates what's analogous to human "fast thinking" and "slow thinking" — users can activate the "extended thinking" feature to let the model engage in longer, deeper deliberation before responding, similar to OpenAI's o1 model's chain-of-thought approach. Anthropic's innovation lies in fusing both modes within a single model, allowing users to flexibly switch based on task complexity rather than choosing between two separate models.
According to official benchmark data, its coding capabilities far exceed the previous 3.5 version — but benchmarks are just benchmarks. How does it actually feel in practice?
A Bilibili content creator conducted systematic hands-on comparisons in Cursor, using four groups of front-end development tasks at varying difficulty levels to visually demonstrate Claude 3.7 Sonnet's programming improvements over 3.5. A brief introduction to the testing tool: Cursor is an AI-native code editor built on the VS Code architecture, developed by Anysphere. It's designed from the ground up for AI collaboration, supporting entire project contexts (including file structures, dependencies, screenshots, etc.) as model inputs — a fundamental difference from plugin-based solutions like GitHub Copilot.
The front-end domain was chosen for testing for two reasons: first, official documentation explicitly states that 3.7 has "particularly significant improvements" in coding and front-end web development; second, front-end results are highly visual, making differences immediately apparent.
Test 1: Web Page Replication — Massive Improvement in Information Extraction
The test goal was to replicate Feishu's "Flying Club" page, with the prompt requesting an HTML+CSS+JavaScript screenshot replication, using open-source free image links as placeholders for images.
The core challenge here is the model's multimodal understanding capability — the ability to simultaneously process text and image inputs. In a web page replication scenario, the model needs to identify the visual hierarchy, text content, color scheme, spacing ratios, component types, and other information from a screenshot, then convert this visual information into corresponding HTML structure and CSS styling code. This process involves the Vision Encoder's feature extraction from images, as well as the language model's semantic understanding of these visual features and code generation capability.
Claude 3.5's Performance
The page generated by Cursor + Claude 3.5 Sonnet was missing a large amount of information, basically only constructing the navigation menu and the topmost card area, with a significant gap from the original page.
Claude 3.7's Performance
Cursor + Claude 3.7 Sonnet essentially built out the complete page framework. While there were some layout alignment issues, these were resolved after a second round of adjustments. More importantly, 3.7 extracted and reproduced far more content information from the screenshot than 3.5.
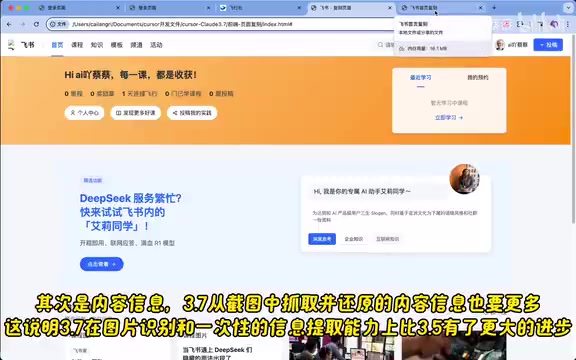
Key Difference: This test demonstrates that Claude 3.7 has achieved a qualitative leap in image recognition and single-pass information extraction capability. Improvements in Vision-Language Alignment in version 3.7 enable it to extract more fine-grained layout and content information from a single screenshot, with significantly enhanced multimodal understanding.
Test 2: Responsive Login Page — Exceeding Expectations in Requirement Understanding
The prompt requested designing a responsive login page supporting both desktop and mobile devices, including username and password input fields and a login button, implemented with HTML/CSS/JavaScript, ensuring reasonable layout across different screen sizes.
Claude 3.5: Adequate but Unremarkable
Claude 3.5 generated a page that basically met requirements — functionally complete but without any surprises.
Claude 3.7: Genuinely Impressive
The tester said they were "genuinely amazed at first sight." Specific highlights included:
- UI Level: The page design was noticeably more sophisticated and polished
- Functional Interaction Level: Not only did it accurately understand the explicit requirements, but it proactively added input field placeholder text, "Remember me," and "Forgot password" — implicit needs the user never described
This essentially delivered current best practices for web product registration/login windows — an AI coding experience that exceeded all expectations. The model is no longer a simple "instruction executor" but is beginning to demonstrate product thinking. This capability improvement likely stems from the deep reasoning mode in the hybrid reasoning architecture: before generating code, the model can "think about" what elements a complete login page should have in a real product, filling in functionality that users didn't explicitly express but actually need.
Test 3: React Single Page Application — One-Shot Generation of Complex Projects
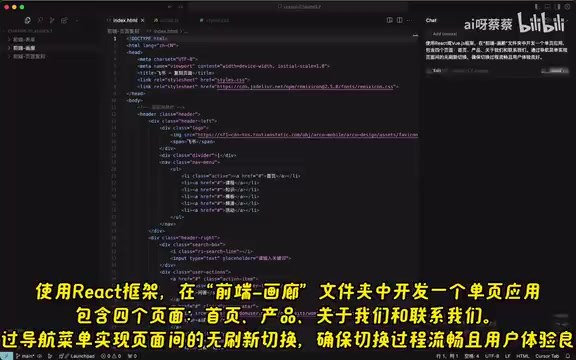
This was the most challenging test group. The prompt requested developing a single page application using the React framework with four pages (Home, Products, About Us, Contact Us), implementing refresh-free navigation switching through a navigation menu.
A React Single Page Application (SPA) is the mainstream architecture pattern in modern front-end development. Unlike traditional multi-page websites, SPAs load all necessary resources on the initial load, then dynamically update page content via JavaScript without full-page refreshes. Implementing a complete React SPA involves multiple technical layers: React Router for client-side routing management, component state management, Props passing, conditional rendering, event handling, and more. A four-page application also involves shared layout components (Header/Footer), navigation state synchronization between pages, filtering and search interaction logic — being able to generate such a complete application in one shot means the model needs to simultaneously maintain dependency relationships and logical consistency across multiple files, placing extremely high demands on context window and long-range reasoning capabilities.
Claude 3.5: Barely Functional
The generated pages basically had the described functionality, but overall layout and interaction were poor — most page buttons beyond the navigation menu were non-interactive.
Claude 3.7: Comprehensive Dominance
3.7's output was impressive once again, demonstrated across three dimensions:
- Content Richness: Page content was much more substantial, no longer empty shells
- Page Structure: Complete Header, Body, and Footer structure, with Header and Footer shared across all four pages
- Interaction Completeness: Supported navigation menu switching, Banner area "Browse Works" button, Body area "View More" quick jumps, product page category filtering, and even a works search function
All of these functional interactions were completed by Claude 3.7 Sonnet in a single round of code generation. Of course, the corresponding generation time was longer, and the number of project files and file sizes generated significantly exceeded the 3.5 version. This performance fully demonstrates 3.7's enormous progress in context window utilization efficiency and multi-file coordinated generation.
Four Core Conclusions

Through three groups of systematic comparative tests, four core conclusions can be drawn:
1. Requirement Understanding: From "Adequate" to "Exceeding Expectations"
Claude 3.5 could only meet basic requirements (sometimes falling short), while Claude 3.7 not only meets explicit requirements but can also read implicit needs users haven't expressed, delivering implementations that exceed expectations.
2. Front-End UI Aesthetics: Cursor's Weakness Is No Longer Weak
Previously, Cursor-generated UIs were often criticized as "too ugly," requiring tools like V0 to compensate. V0 is an AI front-end generation tool launched by Vercel, focused on converting natural language descriptions into high-quality React/Next.js component code, excelling in visual aesthetics and component standardization. Previously, developers often needed to first generate attractive UI components with V0, then import the code into Cursor for logic development, creating a fragmented workflow. Now with Claude 3.7, even without style-specifying keywords, the baseline UI aesthetics of generated output are already quite solid — this fragmented workflow can potentially be unified.
3. Multimodal Capability: A Qualitative Leap in Replication Precision
Previously, Claude 3.5 could only replicate reference pages in limited scope. Now Claude 3.7 shows massive improvements in replication scope, precision, and detail.
4. Context Processing: Larger-Scale One-Shot Generation
Claude 3.7 supports one-shot generation of more project files and larger codebases. Combined with Cursor 0.46's powerful Agent capabilities — this version allows AI to autonomously execute multi-step tasks including creating files, installing dependencies, running terminal commands, and more, significantly reducing manual intervention — the boundaries of AI programming are being pushed further.
Summary and Outlook
From this hands-on testing, Claude 3.7 Sonnet's coding capability improvement isn't an incremental "slightly better" — it's a leapfrog "much better." It demonstrates significant progress across four dimensions: depth of requirement understanding, UI aesthetic quality, multimodal recognition precision, and context processing capability.
For developers who regularly use Cursor for AI-assisted programming, upgrading to Claude 3.7 Sonnet is practically a must. Especially in front-end development scenarios, work that previously required multiple rounds of dialogue and repeated adjustments can now achieve a remarkably high level of completion in a single generation. This isn't just an efficiency improvement — it's a qualitative transformation in the AI programming experience.
Notably, the capability leap reflects a broader trend: AI programming tools are evolving from "code completion assistants" to "full-stack development partners." When a model can understand product intent, possess design aesthetics, and generate complete projects in one shot, the barriers and processes of software development will be fundamentally redefined.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.