Deep Comparison of o1, o1 pro, and o3-mini-high Coding Capabilities: A Deep Research Analysis
Deep Comparison of o1, o1 pro, and o3-…
Deep Research systematically compares o1, o1 pro, and o3-mini-high coding capabilities, revealing strengths and use cases.
This article uses OpenAI's Deep Research feature to auto-generate a deep comparison of o1, o1 pro, and o3-mini-high coding capabilities in just 9 minutes. Key findings: o1 pro leads in code quality, complex task reasoning, and reliability but costs the most; o3-mini-high achieves near-o1 capability as a smaller model with speed and cost advantages; o1 exhibits an over-reasoning "double-edged sword" effect. The article also showcases Deep Research's unique value as an autonomous research agent that synthesizes multi-source data into deep insights rather than simple information aggregation.
Introduction
OpenAI's Deep Research feature is transforming how people conduct technical research. It doesn't just retrieve information—it excels at offering useful analysis and insights, representing an entirely new form of research.
Deep Research is an Autonomous Research Agent built on the o3 model, launched in early 2025. It can independently plan research paths, execute multi-round searches across the internet, read and synthesize dozens or even hundreds of web pages, and ultimately generate structured, in-depth reports. This is fundamentally different from traditional RAG (Retrieval-Augmented Generation)—RAG typically performs a single retrieval before generating output, whereas Deep Research dynamically adjusts its search strategy based on intermediate results, simulating the iterative thinking process of a human researcher. Today, we'll look at a real-world example of how Deep Research helps us systematically compare the coding capabilities of three models: o1, o1 pro, and o3-mini-high.
The entire analysis report was automatically generated by Deep Research in approximately 9 minutes, citing numerous sources from OpenAI's official website and academic papers, demonstrating impressive depth and breadth.
Official Coding Benchmark Data Review
Before diving into Deep Research's analysis, let's review the official coding capability data published by OpenAI. To understand this data, we first need to know what each benchmark focuses on: Codeforces is the world's most authoritative competitive programming platform, with a rating system based on thousands of algorithmic contest problems that precisely measures a model's reasoning ability in data structures, dynamic programming, graph theory, and other complex algorithms; Pass@k is a statistical metric where Pass@1 represents the probability of passing tests on a single generation attempt, while Pass@4 allows 4 attempts and better reflects the model's potential capability ceiling; SWE-Bench (Software Engineering Benchmark) is closer to real engineering scenarios, requiring models to solve Issues from actual GitHub repositories, covering code comprehension, bug localization, patch generation, and other complete software engineering workflows—it's considered the benchmark that best reflects actual development capabilities.
- Pass@1 Codeforces: o1 and o1 pro scores are very close
- Codeforces Rating: o1's score is far below o3-mini-high
- Pass@4 Pass Rate: o1 pro significantly outperforms o1 (pass rate when testing the same problem 4 times)
- SWE-Bench Score: o1 scores much higher than o3-mini medium, but slightly lower than o3-mini-high
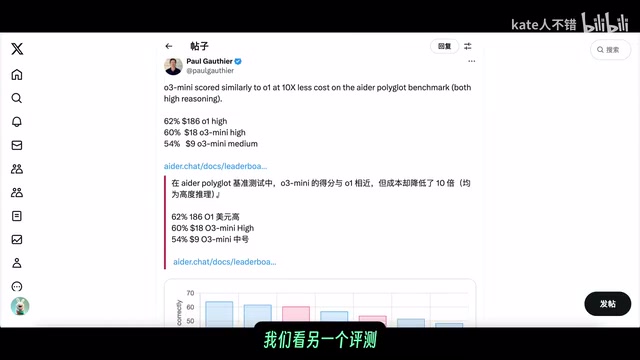
In the AID benchmark test, o1 high (corresponding to o1 pro) scored above 60 in coding capability, outperforming o3-mini-high, though the two are very close. These data points provide important reference for Deep Research's analysis.
Deep Research's Overall Assessment of the Three Models
Positioning Differences Among the Three Models
Deep Research provided clear positioning for the three models:
- o3-mini-high: Despite its smaller size, reinforced reasoning training gives it intelligence approaching o1 on engineering tasks requiring reasoning
- o1 pro: Due to greater computational investment, it may provide more thorough solutions
- Web Development: All three are competent; for clear, singular tasks, all can deliver high-quality solutions
The reason o3-mini-high achieves reasoning capability close to o1 with a smaller model size lies in OpenAI's Reinforcement Learning for Reasoning paradigm. Unlike traditional supervised fine-tuning, this approach lets the model learn "how to think" through extensive trial and error, rather than directly learning "what the answer is." During inference, the model generates an internal "Chain of Thought," performing multi-step self-verification before producing a final answer. The "high" suffix indicates a higher compute budget during inference, allowing the model to perform longer chain-of-thought reasoning—this is the fundamental reason why the same model shows significantly different performance under different configurations.
The key conclusion: for multi-step complex tasks, o1 pro performs better; in database scenarios, o1 pro is more likely to discover potential optimization points in code or queries due to executing more thinking steps.
Code Generation Quality Comparison
Deep Research's quantitative ranking: o1 pro ≈ o3-mini-high > o1
Regarding maintainability, o1 pro may write more robust code when facing complex requirements, while o3-mini-high tends to complete tasks in a concise and intuitive manner—but the difference is minimal.
Code Optimization Capability
o3-mini-high has mastered optimization algorithms and can write efficient solutions when needed. The overall ranking: o1 pro > o1 ≈ o3-mini-high
Error Rate and Reliability Analysis

Deep Research offered a very practical suggestion in its error rate analysis: to be safe, developers should break down requirements clearly or verify model outputs step by step, reducing logical errors caused by reasoning deviation.
Overall assessment:
- o1 pro: Most reliable
- o1: Close behind
- o3-mini-high: Despite its small size, reliability approaches o1
Deep Insights from Real Coding Examples
The "Double-Edged Sword" Effect of o1

Deep Research cited an interesting case: o1 scored lower than Claude 3.5 on a particular task. The report analyzed that this highlights o1's "double-edged sword" characteristic—deep reasoning makes it excel at well-defined tasks, but its robustness with complex instructions needs improvement.
This phenomenon has a deeper technical explanation in AI reliability research, essentially reflecting the tension between Over-reasoning and Instruction Following. When strong reasoning models receive complex instructions, they construct an internal "problem model." Once this model deviates in the initial stage, subsequent reasoning steps actually proceed along the wrong path with extremely high "confidence," forming what's called "reasoning inertia"—once a detail is missed, the reasoning process may not self-correct but instead firmly proceeds in the wrong direction. In contrast, models like Claude 3.5 adopt more conservative generation strategies, tending to seek clarification rather than making autonomous inferences when uncertain. While individually weaker in certain capabilities, sometimes less reasoning actually avoids pitfalls.
Key Takeaway: When asking a model to generate a large complex application in one go, it's best to explicitly list requirements and confirm model outputs one by one, or break the task into multiple conversation turns. This is also why the industry increasingly values "Prompt Engineering"—for strong reasoning models, clear, atomic instructions leverage their potential better than vague high-level descriptions, while compensating for possible oversights with complex instructions.
o3-mini-high's Impressive Performance
In the community-popular Python script test of 100 colored balls bouncing inside a sphere, o3-mini-high's solution perfectly met every requirement in the prompt. Additionally, on classic algorithm problems, o3-mini produced concise and clever solutions that ran much faster than code written by standard GPT.
Code Debugging and Error Fixing Capability Comparison

Deep Research pointed out that in real software engineering, writing code is just the first step—debugging and fixing errors are equally critical:
- o1: Can effectively locate problems and provide correct fixes
- o3-mini-high: Fixed 39% of errors; if allowed to invoke internal tools (running code, viewing error messages), the success rate jumped to 61%
Behind this leap is the power of the Code Execution Feedback Loop. When models are allowed to invoke tools, they no longer rely solely on static code analysis to identify problems—instead, they obtain runtime information (such as stack traces, variable states) through actual execution, then adjust their fix strategies accordingly. This "execute-observe-correct" closed-loop pattern is called a "Code Agent" and closely mirrors how human programmers debug. Currently, mainstream AI coding tools like GitHub Copilot and Cursor are actively integrating this capability, which is considered the core competitive advantage of next-generation AI programming assistants.
The report specifically emphasized: security-related errors sometimes don't show up in simple test cases, and models may not easily detect them. Human-model collaboration remains crucial—humans provide high-level guidance, models execute specific debugging steps, and together they can minimize error rates.
Final Conclusions and Model Selection Recommendations
Based on authoritative benchmarks and case analysis, Deep Research provided a quantitative summary:
| Dimension | Ranking |
|---|---|
| Overall Coding Capability | o1 pro > o1 ≈ o3-mini-high |
| Code Generation Quality | o1 pro > o1 ≈ o3-mini-high |
| Optimization & Tuning | o1 pro is best |
| Error Rate | o1 pro most reliable > o1 > o3-mini-high |
Selection recommendations for different scenarios:
- o3-mini-high: Wins on speed and cost, suitable for high-frequency coding Q&A and general development tasks
- o1: Provides more comprehensive reasoning support, more robust on complex tasks
- o1 pro: For professional scenarios with extremely high accuracy requirements
Evaluation of the Deep Research Feature
This case fully demonstrates Deep Research's value—it's not simple information aggregation, but rather the ability to cross-analyze multiple data sources and offer deep insights. For example, the "double-edged sword" effect analysis and human-AI collaborative debugging suggestions are all valuable perspectives that stimulate developer thinking.
Although some information wasn't fully retrieved (such as certain specific scores), completing such an in-depth technical comparison report in 9 minutes is itself a milestone experience in AI-assisted research.
Key Takeaways
- Deep Research completed a systematic comparison of o1, o1 pro, and o3-mini-high coding capabilities in 9 minutes
- o1 pro performs best in multi-step complex tasks, code quality, and error rates, but at the highest cost
- o3-mini-high achieves coding capability close to o1 as a small model, with significant advantages in speed and cost
- o1 exhibits a "double-edged sword" effect: deep reasoning excels at well-defined tasks but needs improved robustness with complex instructions
- Deep Research's core value lies in offering useful analysis and insights, not simple information retrieval
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.