Deep Dive into Qwen3.7 Max: One-Tenth the Cost of GPT, Purpose-Built for AI Agents
Deep Dive into Qwen3.7 Max: One-Tenth …
Alibaba's Qwen3.7 Max redefines LLM competition with ultra-low cost and marathon endurance for AI agents.
Alibaba's Qwen3.7 Max is positioned as an AI Agent, not a traditional chatbot. It achieves 56% performance improvement at just $1.30, far outperforming Claude Opus 4's $12/28% ratio with crushing cost-performance dominance. It supports 35 hours of continuous execution with 1,200 tool calls and demonstrates strong front-end development capabilities. However, it lacks multimodal abilities, has inconsistent aesthetics, and is highly dependent on prompt quality. This model signals LLM competition shifting from "comparing intelligence" to "comparing endurance and cost."
Not a Chatbot, But a "Cyber Foreman"
Alibaba's latest release, Qwen3.7 Max, takes a fundamentally different positioning from traditional large language models — it's not designed for casual conversation, but targets the most commercially valuable segment: AI Agents.
What does "AI Agent" mean in plain language? You no longer need to interact with AI round by round. Instead, you hand it an entire complex project. Like a tireless "cyber foreman," it autonomously calls tools, writes code, debugs, fixes errors, and delivers end-to-end results. For everyday users, this means building a small tool, writing an automation workflow, or creating an internal system no longer requires waiting in a development queue — let the AI scaffold and prototype it first, at virtually zero cost.
AI Agent Technical Background: AI Agents possess autonomous planning, tool-calling, and multi-step execution capabilities. Their underlying architecture is typically based on the "ReAct" framework (Reasoning + Acting), where the model reasons before acting at each step, forming a closed loop of "think → call tool → observe result → think again." Typical tool calls include: code executors, web search, file read/write, and API endpoints. OpenAI's Function Calling, Anthropic's Tool Use, and Alibaba's Qwen Tool are all concrete implementations of this paradigm. The commercial value of Agents lies in their ability to directly convert human "intent" into "results," skipping tedious manual steps in between — which is why all major players are positioning Agent capabilities as their core competitive advantage for the next phase.
This shift in positioning carries profound implications. In the past, we evaluated LLMs by asking "who's smarter." The question Qwen3.7 Max aims to answer is: Who can get the job done more cheaply, more persistently, and more reliably?
Qwen3.7 Max Cost Dominance: $1.30 vs $12
What truly takes your breath away is the crushing cost advantage Qwen3.7 Max demonstrates.
In a long-cycle agent programming task, researchers had models continuously iterate and improve a robotics program over 10 rounds. Here are the results:
| Model | Performance Gain | Cost |
|---|---|---|
| Qwen3.7 Max | 56% | ~$1.30 |
| Claude Opus 4 | 28% | ~$12 |
| GPT-5 | 7% | Undisclosed (estimated higher) |
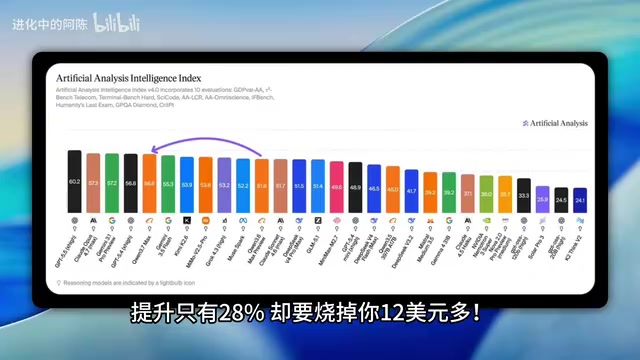
A 56% improvement for just $1.30, while Claude Opus 4 spent nearly 10x the price for only half the improvement. GPT-5 managed a mere 7% gain. This isn't simply "a bit cheaper" — it's an order-of-magnitude cost difference.
LLM Cost Structure and Token Economics: LLMs are billed by Tokens — in Chinese, roughly 1.5 characters equals 1 token; in English, approximately 4 characters equals 1 token. In Agent scenarios, each tool-calling round generates massive input/output token consumption — the model must read conversation history, tool return results, system prompts, etc., causing context length to grow exponentially as tasks progress. Taking Claude Opus 4 as an example, its pricing is approximately $15/million input tokens and $75/million output tokens, while Qwen3.7 Max's pricing is significantly lower. In real workflows with 100+ continuous iterations, token consumption can reach millions, and pricing differences get amplified many times over, ultimately creating an order-of-magnitude cost gap.
Why does cost matter so much? Because in real business scenarios, an AI agent doesn't just run one round and stop. When you integrate AI into your company's workflow, a single task might require 100 or 1,000 iterations. No matter how smart the model is, if every round burns money, average teams will go bankrupt. Cost is the make-or-break line for agent deployment.
35 Hours of Continuous Execution: Endurance Is the Real Superpower
Beyond being cheap, Qwen3.7 Max's other killer feature is its ultra-long endurance.
Official test data shows it can sustain up to 35 hours of autonomous execution, continuously calling 1,200 tools without losing context after two steps or hallucinating halfway through. This means while you're sleeping, this sub-dollar "digital worker" is still fixing bugs, running tests, and optimizing code for you.
Long-Context Attention Decay: "Attention decay" is an inherent challenge of current Transformer-based LLMs. Research shows that models have the highest forgetting rate for information positioned in the middle of the context — a phenomenon known as the "Lost in the Middle" effect. For Agent tasks requiring continuous execution over dozens of hours, this is a fatal weakness: goals, constraints, and completed work states established early on may be "forgotten" after hundreds of conversation rounds, causing the model to repeat work or hallucinate. Qwen3.7 Max's claim of stable support for 35 hours and 1,200 tool calls implies targeted optimization in long-range attention retention and context compression techniques — practical value for Agent scenarios that far exceeds raw benchmark scores.
This endurance is quite remarkable among current LLMs. Many models suffer from "attention decay" in long-context tasks — earlier instructions gradually fade, and output quality drops sharply. Qwen3.7 Max has clearly been optimized specifically for this, making it better suited as a long-running automation node.
Front-End Development: Not Just Writing Code, But Understanding Interaction Logic
Qwen3.7 Max's performance in front-end development is equally impressive. It can not only generate web prototypes but even hand-craft a complete desktop system interface with bottom menus, calculators, drawing boards, and other functional modules.

What's even more noteworthy is its understanding of physics logic and interaction feedback. In a fish-raising simulation demo, it precisely controlled each fish's movement data and position, achieving natural interaction effects where fish swarm toward food after it's dropped — complete with UI controls and real-time rendering at a remarkably professional design level.
This demonstrates that Qwen3.7 Max isn't mechanically stitching together code snippets, but attempting to understand real-world spatial relationships and interaction feedback logic, capable of handling long-process front-end design while maintaining visual quality consistency.
Three Shortcomings You Can't Ignore: Where Qwen3.7 Max Falls Short
Of course, Qwen3.7 Max currently has unavoidable weaknesses:
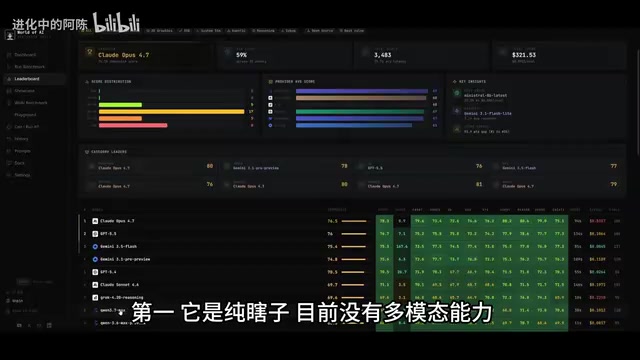
First, no multimodal capabilities. Currently it's "blind" — it cannot process images or video. In an era where multimodal is becoming mainstream, this is a significant functional gap.
Industry Context for Missing Multimodal Capabilities: Multimodal capability refers to an LLM's ability to simultaneously process text, images, audio, video, and other data types. GPT-4V, Claude 3 series, and Gemini 1.5 Pro have all achieved mixed image-text input. In practical development scenarios, lacking multimodal means: inability to describe UI requirements via screenshots, inability to analyze design mockups for implementation, and inability to process technical documents containing charts. Alibaba's Qwen-VL series already has multimodal capabilities; Qwen3.7 Max's decision to temporarily forgo multimodal as a version focused on Agent performance represents a "specialization for performance" trade-off. However, as multimodal becomes an industry standard, this gap is expected to be filled in subsequent versions.
Second, occasional aesthetic failures. Despite strong coding abilities, the web designs it generates sometimes look "painfully outdated," with inconsistent visual aesthetics.
Third, extreme dependence on prompt quality. Give it a vague, lazy instruction and it'll give you sloppy output; give it detailed rules and interaction logic, and it becomes a top-tier engineering assistant. This means the user's prompt engineering skill directly determines the ceiling of output quality.
The Essence of Prompt Engineering: Prompt engineering refers to the technical practice of maximizing LLM output quality through carefully designed input instructions, including: role definition (System Prompt), few-shot examples (Few-shot Learning), chain-of-thought guidance (Chain-of-Thought), constraint declarations, and output format specifications. In Agent scenarios, a good System Prompt needs to clearly define task boundaries, tool usage rules, error handling strategies, and output standards. Research shows that the same model can exhibit 30%-50% performance variation under different prompts. This explains why Qwen3.7 Max is highly sensitive to prompt quality: the stronger the model's capabilities, the more significant the impact of prompts on "unlocking its ceiling."
In short, don't treat it like a magic wand — treat it as an obedient, cheap workhorse that can rework things repeatedly — get the positioning right, and its value is maximized.
LLM Competition Enters the "Endurance Race" Phase
The emergence of Qwen3.7 Max signals that LLM competition is entering a new phase.
Over the past two years, the industry focused on "who's smarter" — comparing benchmark scores, reasoning ability, and knowledge breadth. But as top models' intelligence levels converge, the factors that truly determine commercial value become endurance, price, and execution stability.
Requests like "build me a demo" or "write an automation script" are being completely repriced. Chatty AI is certainly useful, but what truly restructures business moats is AI workers that are cheap, tireless, and can grind tasks to completion.
Alibaba's betting logic on this path is clear: once the cheap, high-concurrency agent route proves viable, the rules of the LLM competition will be fundamentally rewritten. For domestic developers and SMEs, Qwen3.7 Max may be one of the most cost-effective AI productivity tool choices currently available.
Key Takeaways
- Qwen3.7 Max targets the AI Agent track, supporting 35 hours of continuous autonomous execution and 1,200 tool calls with exceptional endurance
- In agent programming tasks, Qwen3.7 Max achieved 56% performance improvement at $1.30, while Claude Opus 4 spent $12 for only 28% — a crushing cost-performance advantage
- Outstanding front-end development capabilities with understanding of physics logic and interaction feedback, generating complete functional desktop system interfaces
- Three current hard limitations: no multimodal capability, inconsistent aesthetics, and high dependence on prompt quality
- LLM competition is shifting from "comparing IQ" to a new phase of "comparing endurance, price, and execution stability"
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.