Gemini 2.5 Pro 0605 Hands-On Comparison with o3 and Claude Opus 4: Full Evaluation Across Coding, Reasoning, and Writing
Gemini 2.5 Pro 0605 Hands-On Compariso…
Gemini 2.5 Pro 0605 excels at visual coding but still trails o3 in reasoning and writing.
Google's new Gemini 2.5 Pro 0605 shows significant improvements in frontend code generation and visual effects, but falls short of o3 in logical reasoning rigor (tending to force definitive answers) and creative writing literary quality. In real-world engineering development, it suffers from outdated knowledge and stability issues, requiring multi-model collaboration. Its clear pricing advantage makes it ideal for budget-conscious developers. The current AI landscape confirms: no universal champion, only kings of their domain.
Google recently released Gemini 2.5 Pro 0605, claiming superior performance across multiple benchmarks including reasoning, scientific problems, and coding. This article provides a detailed head-to-head comparison of the new Gemini 2.5 Pro against OpenAI o3, Claude Opus 4, and other models across multiple dimensions including code generation, logical reasoning, creative writing, and real-world application development.
Coding Ability: Significant Improvement in Visual Output
The new Gemini 2.5 Pro's most visible improvement is in coding. Google specifically highlighted the model's high scores on Web Dev Arena — a specialized evaluation platform by LMSYS (Large Model Systems Organization) that uses a "blind battle" mechanism: users submit frontend development requirements, the platform simultaneously calls two anonymous models to generate interfaces, and users vote based solely on visual results. Final rankings are determined through an Elo rating system. This approach avoids users' subjective brand preferences and is considered more reflective of real user experience value than traditional static benchmarks. Evaluating frontend code generation is inherently complex because it tests not only syntactic correctness but also CSS layout precision, animation curve calculations, WebGL/Canvas rendering logic, and cross-browser compatibility.

Across multiple visual coding tests, the new Gemini performed impressively:
- 24-hour ring clock (SVG): The new version produces more refined results than the old version, with more aesthetically pleasing gradients — white for daytime on the outer ring and deep blue for nighttime on the inner ring
- 3D Menger Sponge (P5.js): Supports click-to-add-detail and scroll-to-zoom, with excellent internal gradient effects. P5.js and Three.js represent two different tech stacks — 2D creative coding and 3D graphics rendering respectively — and models need to understand underlying graphics principles to generate high-quality interactive effects
- Infinite starfield warp: Responsive mouse interaction, clicking generates supernovae, overall effect superior to o3's output
- Claw machine (Three.js): Significant improvement over the old version with highly realistic push-rod simulation, vastly outperforming the crude outputs from Qwen3 235B and Claude 3.5 Haiku
However, on SWE-Bench, Claude Opus 4 still scores highest, with the new Gemini 2.5 Pro and o3 very close to each other. SWE-Bench (Software Engineering Benchmark), published by a Princeton University research team, collects real Issue reports and corresponding Pull Request patches from GitHub, requiring models to automatically locate bugs and generate fix code that passes tests given a code repository context. Unlike toy problems like "write a sorting algorithm," it demands cross-file understanding, dependency tracking, test-driven development, and other engineering capabilities — it's considered the gold standard for measuring whether a model "can truly replace a junior engineer." In a test cloning the Vercel interface, Opus 4 also produced noticeably better results than Gemini, with richer content closer to a real product.
Logical Reasoning: Gemini Still Has Clear Weaknesses
In a logic puzzle about three startup teams competing for project funding, the two models gave starkly different answers.
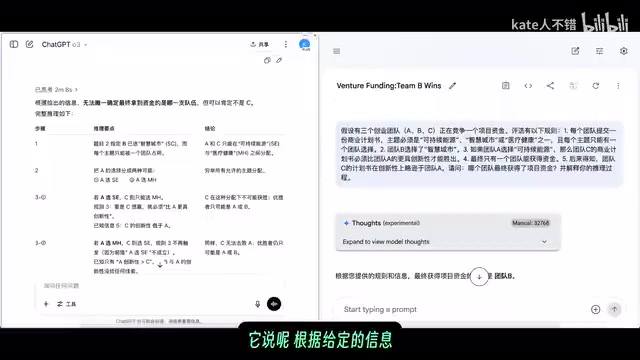
o3 thought for two minutes before providing a rigorous analysis: based on the given information, it's impossible to uniquely determine which team ultimately receives funding, but Team C can be eliminated. It divided Team A's choices into two possibilities, concluding that "based solely on the problem statement, we can only eliminate C — we cannot assert whether it's A or B." This ability to "acknowledge uncertainty" is called "Calibration" in AI safety — a model's confidence should match its actual accuracy rate. o3 belongs to the "Reasoning Model" series, whose core feature is performing extensive internal "chain-of-thought" computation before generating a final answer, making it more likely to identify "insufficient conditions" in logic problems with incomplete information and report them honestly.
Gemini 2.5 Pro treated this as a logic puzzle that "must have one uniquely determined answer." Unable to determine whether A or C would win, it defined Team B as "the outsider in the logical storm" and concluded B receives the funding. This reasoning process contains obvious logical leaps and lacks persuasiveness. This "Overconfidence" is a common problem in current large models — models are influenced by reward signals for "giving definitive answers" during training, sometimes sacrificing accuracy to satisfy the appearance of "looking useful."
From this problem, Gemini still has a significant gap compared to o3 in reasoning rigor. o3 can honestly acknowledge that the information is insufficient to reach a unique conclusion, while Gemini tends to force a "definitive" answer.
Creative Writing Comparison: o3's Literary Quality Stands Out
The writing test asked for a story about "the friendship between a lonely lighthouse keeper and a kitten," requiring two different styles.
o3's performance was more literary and poetic. For example, "the kitten blinked its large amber eyes" and "Ah Guang taught the kitten to count stars, and the kitten taught Ah Guang to listen to seashells sing" — full of vivid imagery. In the gothic style, sentences like "If even the sea entrusts this fragile life to him, then does this lighthouse intend for him to guard, or to judge?" carry tremendous tension.
Gemini's story was relatively straightforward — the lighthouse keeper discovers a wooden crate, opens it to find a kitten, with a simpler narrative structure. While the second style included interesting expressions like "I am the keeper of this eye, and also its only prisoner," the overall literary quality and emotional depth fell short of o3.
Information Retrieval and Table Processing
In an information retrieval strategy question about "how to quickly learn about a completely new niche biotechnology," the two models each had their strengths.
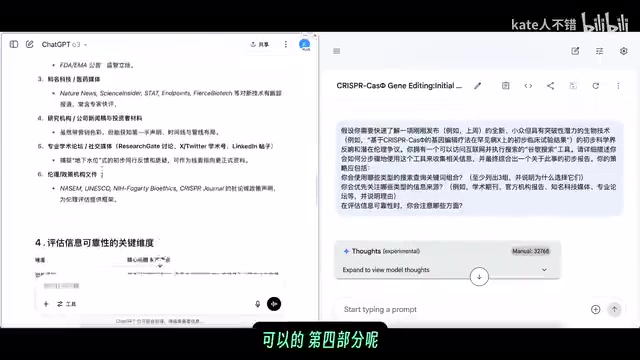
o3's response used a clear tabular structure, divided into five steps: clarify information needs, design search term combinations, prioritize information sources, evaluate information reliability dimensions, and compile a report. This structured output is highly practical for actual use.
Gemini's response was equally organized, including steps for positioning, gathering initial reactions, exploring ethical controversies, and comprehensive reporting, plus specific search keyword combinations and peer-reviewed journal recommendations.
In table recognition, the new Gemini performed satisfactorily with virtually no errors upon verification. Meanwhile, o3 in ChatGPT invoked Python tools to process the table — a complex and time-consuming process that ultimately produced some comprehension errors (such as incorrectly identifying dash marks for Gemini 2 Flash).
Real-World Application Development: Multi-Model Collaboration Is the Optimal Solution
When developing a 3D virtual exhibition hall application based on React Router v7, the test exposed several practical issues with Gemini 2.5 Pro.
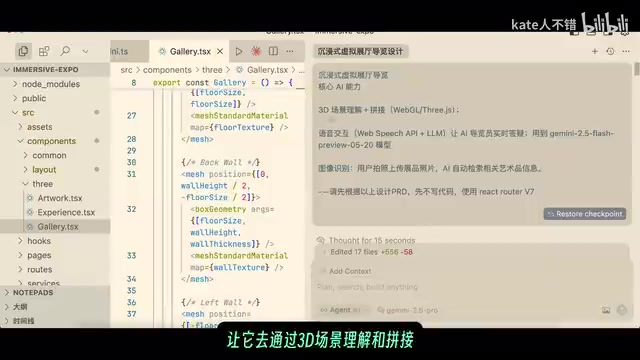
Problems encountered with Gemini:
- Incorrectly believed React Router v7 was in alpha (outdated knowledge base)
- Forgot previous prompt requirements during long conversations
- Numerous runtime errors; after multiple fixes, still suggested reinstalling Node
- Homepage wouldn't open at all when API key was missing
React Router v7 was officially released in late 2024 as a major version deeply integrating the Remix framework with React Router. Gemini's misjudgment of it as an "alpha version" exposes the systemic risk of Knowledge Cutoff dates in large models — most mainstream models have training data cutoffs from early to mid-2024, and for the rapidly iterating frontend ecosystem, this lag can lead to outdated or even incorrect technical advice. In actual engineering development, developers typically need to explicitly specify framework versions in prompts, or inject the latest documentation into context via RAG (Retrieval-Augmented Generation) to compensate for knowledge base timeliness deficiencies.
Ultimately, Claude Sonnet 4 had to take over, performing more stably in handling terminal errors, installing dependencies, and resolving version conflicts, successfully completing the application deployment after several rounds of fixes.
This demonstrates that in real-world engineering development, a single model often cannot perfectly complete complex tasks — multi-model collaboration may be the most pragmatic strategy today. "Multi-Model Orchestration" is becoming the mainstream paradigm in AI engineering practice, spawning orchestration frameworks like LangChain and LlamaIndex, as well as development tools like Cursor and Windsurf that embed multi-model scheduling within the IDE. From an architectural perspective, different models excel at different stages of the "plan-execute-verify" workflow: reasoning models (like o3) are suited for task decomposition and logical verification, code-specialized models (like the Claude Sonnet series) are suited for concrete implementation and debugging, while lower-cost models are suited for handling repetitive format conversion tasks.
Cost-Effectiveness: The Top Choice for Budget-Conscious Developers
A notable detail: the new Gemini 2.5 Pro maintains the same pricing as the old version, offering a clear price advantage over o3 and Claude Opus 4. For budget-conscious developers, Gemini 2.5 Pro already delivers quite impressive experiences in scenarios like coding visualization and table processing, making it an extremely competitive choice.
Conclusion: No Universal Champion, Only Kings of Their Domain
The new Gemini 2.5 Pro 0605 shows significant progress in frontend code generation and visual effects, particularly shining in Web Dev Arena-type scenarios. However, it falls short of o3 in reasoning rigor, has a gap in creative writing literary quality, and still needs stability improvements in real-world engineering development.
The competitive landscape of AI models is becoming increasingly clear: there is no universal champion, only kings of their domain. Anthropic, Google, and OpenAI have each launched their own Agent frameworks (Claude Computer Use, Gemini Function Calling, OpenAI Assistants API), all essentially implementing multi-model or multi-tool collaborative scheduling at the system level. This landscape is driving the entire industry from "choosing the best model" toward "designing the optimal model combination strategy" — selecting the right model combination is the key to improving efficiency.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.