Gemini 3.1 Pro vs Claude Opus 4.6: Five Real-World Tests to Determine the Winner
Gemini 3.1 Pro roughly matches Claude Opus 4.6 in testing — major reasoning gains but slightly weaker on creative tasks.
Through five hands-on tests covering SVG generation, interactive components, website building, and complex reasoning, Gemini 3.1 Pro achieves a qualitative leap in reasoning ability, reaching parity with Claude Opus 4.6, but still falls slightly short on creative tasks. Given its price at less than half of Opus and its million-token context window, a "Model Routing" tiered strategy is recommended: use Gemini for daily tasks and Opus for complex scenarios, balancing quality and cost.
Google just released Gemini 3.1 Pro, claiming it significantly outperforms Claude on most benchmarks at half the price. But benchmarks and real-world performance are often two different stories.
It's worth noting that AI benchmarks have inherent limitations. Standard test suites like MMLU, HumanEval, and MATH may produce inflated scores due to "Benchmark Contamination" — where models have indirectly encountered test data during training. More importantly, benchmarks are designed to measure specific capabilities and cannot fully reflect a model's comprehensive performance in real workflows. This is precisely why the hands-on testing in this article offers more practical value than official numbers.
This article is based on a detailed hands-on evaluation by an overseas content creator, comparing Gemini 3.1 Pro and Claude Opus 4.6 head-to-head across five real-world scenarios — from SVG graphic generation and interactive components to website building and complex reasoning — to determine which is currently the strongest large language model.
What's New in Gemini 3.1 Pro
Compared to its predecessor Gemini 3 Pro, version 3.1 achieves significant improvements across several key dimensions. The most critical change is a substantial enhancement in deep reasoning and complex problem-solving capabilities, which Google describes as "smarter and more powerful underlying decision-making ability."
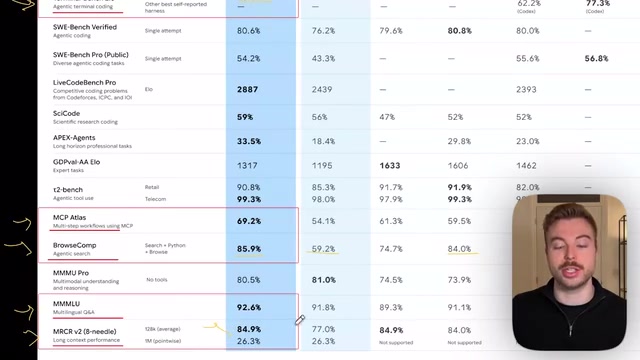
According to official benchmark data:
- Advanced Reasoning: Gemini 3.1 Pro scores 77%, while Opus 4.6 scores 68%
- Scientific Knowledge: Gemini 3.1 Pro rises to 94, Opus 4.6 at 91
- Agentic Coding: Gemini 68 vs Opus 65
- Agentic Search: Jumps from Gemini 3's 59.2% to 85%, roughly on par with Opus 4.6
- Long Context Reasoning: Reaches Opus 4.6's level, with an exclusive million-token context window
Another noteworthy update is the refinement of thinking levels. Thinking levels essentially provide dynamic control over the model's Chain-of-Thought depth — during inference, the model generates intermediate reasoning steps that consume significant tokens and computational resources. Gemini 3 only offered low and high settings, while 3.1 Pro adds a medium option, allowing users to flexibly adjust reasoning depth based on task complexity: use low for simple tasks to save costs, and high for complex reasoning to ensure accuracy. This design philosophy mirrors Anthropic's "Extended Thinking" mode and represents an important evolution in LLM reasoning efficiency.
Additionally, Gemini 3.1 Pro is priced at less than half of Opus, which is a highly attractive cost advantage for enterprise users. LLM APIs typically charge per token — for example, processing 100 million tokens per month, the price difference between the two could amount to tens of thousands of dollars. This is why "tiered usage strategies" are gaining increasing attention in enterprise scenarios.
Test 1: Dynamic SVG Graphic Generation
The first test asked models to generate a complex dynamic SVG scene: a solitary figure walking across a wasteland at dusk, incorporating fog effects, distant rolling hills, an ominous manor on the horizon, a swaying lantern glow, and gentle cloud movement among other detailed elements.
SVG (Scalable Vector Graphics) is an XML-based graphics format that defines shapes through mathematical descriptions rather than pixels. The challenge of having LLMs generate complex SVGs lies in the model needing to translate natural language descriptions into precise coordinates, paths, animation parameters, and other code, while simultaneously "visualizing" the final rendered result in its mind. This requires the synergy of spatial reasoning, code generation, and creative understanding — making it an excellent scenario for testing a model's comprehensive capabilities.
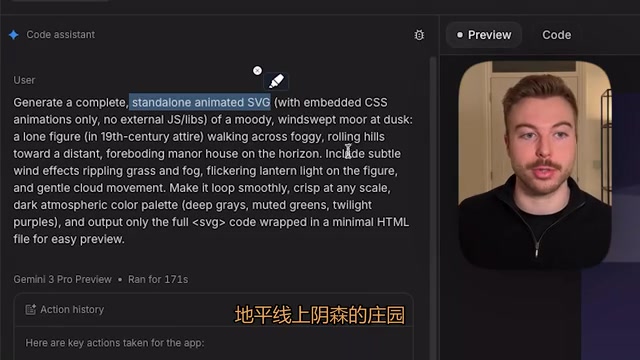
Gemini 3's output was quite rudimentary — it included most of the information but omitted the human figure, and the house was oddly floating. The evaluator gave it roughly a five out of ten. Gemini 3.1 Pro produced quality similar to its predecessor; the lantern had a glowing effect but overall fell short of expectations.
Claude Opus 4.6 performed noticeably better: the background featured a moon and stars, the figure appeared in the scene, fog effects were more pronounced, the manor actually looked like a manor situated on a hill, and the grass had dynamic effects. While layout imperfections remained, the overall completeness far exceeded both Gemini versions.
The key takeaway from this test is that it requires the model to truly understand a large amount of descriptive information, decompose the meaning of each element, and integrate them into a cohesive presentation — Opus 4.6 demonstrated stronger capability in this type of "comprehension + creation" composite task.
Test 2: Interactive Toggle Component
The second test asked models to create a toggleable dynamic SVG switch, smoothly demonstrating light/dark mode switching in a minimalist UI style.
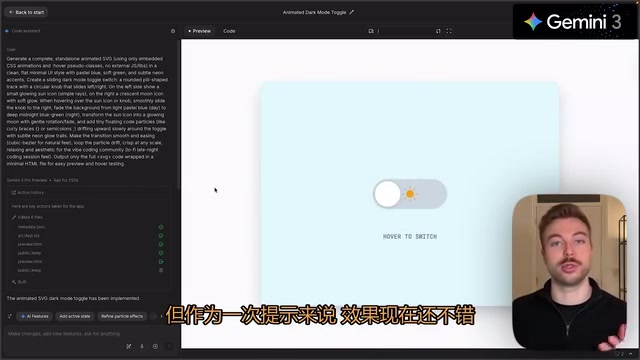
Gemini 3's toggle worked correctly, the light mode positioning was reasonable, and code elements all displayed properly, though it struggled slightly with the light mode. Gemini 3.1 Pro encountered an awkward situation — likely due to heavy concurrent testing by users, the model attempted to run for 30 minutes without producing a preview, and the evaluator ultimately had to manually copy the code to CodePen for testing. The toggle effect was indeed better than the previous version, but the moon wasn't centered, leaving room for improvement.
Opus 4.6 actually had the worst daytime effect of the three, requiring the toggle to be turned off to see the sun. However, the evaluator particularly liked its generated star elements and programming interface elements, rating it slightly better than Gemini 3.1 Pro but not as good as Gemini 3.
This test exposed Gemini 3.1 Pro's response speed issues at launch — an experience shortcoming that cannot be ignored in actual workflows. Response delays caused by server load during a new model's initial launch period are common in the LLM industry and typically improve as infrastructure scales up.
Test 3: Website Page Building
The third test used the same prompt to generate a career highlights website page for an F1 driver.
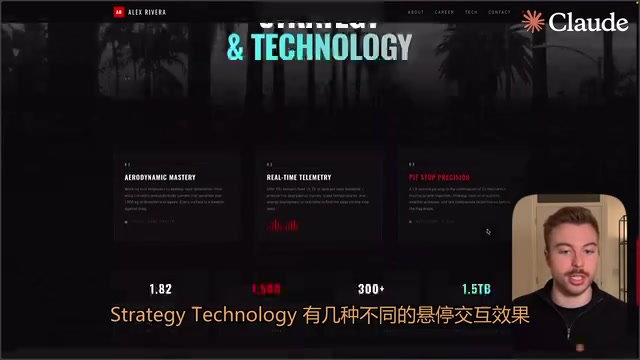
Gemini 3 and 3.1 Pro performed very similarly, with decent overall results showing similar images and key points. The evaluator didn't notice any significant differences between the two. Gemini 3 has always been stable in website generation, and the new version didn't bring a notable breakthrough in this dimension.
Opus 4.6 was rated the best of the three — it used Pexels images as backgrounds, applied glow effects on text for a premium feel, included car backgrounds and Strategy/Technology modules, and featured multiple hover interaction effects. In terms of web UI design aesthetics and attention to detail, Opus 4.6 demonstrated a clear advantage.
Test 4: Complex Reasoning Ability
The final test targeted Gemini 3.1 Pro's biggest selling point — advanced reasoning capability. The test required models to analyze a 3×3 grid (using R/B/G/Y and spaces to represent different colors), infer hidden transformation rules, explain the reasoning process step by step, then apply the rules to generate the correct output.
This type of abstract rule inference task fundamentally tests a model's Inductive Reasoning ability — extracting universal patterns from limited samples and applying them to new situations. This differs fundamentally from knowledge-retrieval Q&A and better reflects a model's true "intelligence" level.
The results of this test best illustrate the generational difference:
- Gemini 3: Got it wrong, failed to infer the correct transformation rule
- Gemini 3.1 Pro: Got it right, successfully reasoned and generated the correct output
- Claude Opus 4.6: Also got it right
This represents the most obvious "leap" from Gemini 3 to 3.1 Pro. In advanced reasoning and complex problem-solving, 3.1 Pro has indeed reached parity with Opus 4.6, validating the progress Google demonstrated in its benchmarks.
Overall Assessment and Tiered Usage Recommendations
Across all five tests, Gemini 3.1 Pro has made significant progress, but its overall performance is roughly on par with or slightly behind Opus 4.6. Specifically:
| Test Category | Winner |
|---|---|
| SVG Graphic Generation | Claude Opus 4.6 |
| Interactive Component | Gemini 3 (Opus 4.6 second) |
| Website Building | Claude Opus 4.6 |
| Complex Reasoning | Tie (Gemini 3.1 Pro ≈ Opus 4.6) |
From a practical standpoint, the evaluator offered a pragmatic usage strategy: Run Gemini 3.1 Pro as a more cost-effective backend model for routine tasks, and reserve Opus 4.6 for more complex scenarios. This "Model Routing" engineering practice is gradually becoming widespread in enterprises — automatically selecting models at different price points based on task complexity, keeping the proportion of high-cost model calls within a reasonable range, thereby significantly reducing overall API spending while maintaining quality. Given that Gemini 3.1 Pro costs less than half of Opus, this tiered usage strategy makes tremendous sense in enterprise scenarios.
One detail worth mentioning: Gemini 3.1 Pro is still in its early rollout phase, and the slow response speed issue will likely improve as servers scale up. The million-token context window is another differentiating advantage that cannot be overlooked — 1M tokens equals approximately 750,000 English words, roughly the length of the entire Harry Potter series. This means you can analyze an entire codebase, a complete set of legal contracts, or large research reports in one go, without the information fragmentation caused by segmented processing. Its application potential in research scenarios like Notebook LM represents a unique advantage that Claude currently cannot match.
The competition among large language models is entering a white-hot phase, and the upcoming showdown between Opus 5 and Gemini 4 will be even more exciting. For users, the most important thing isn't picking sides, but choosing the most suitable tool based on the specific characteristics of each task.
Key Takeaways
- Gemini 3.1 Pro surpasses Opus 4.6 on benchmarks including advanced reasoning (77% vs 68%) and scientific knowledge (94 vs 91), at less than half the price
- In creative tasks like SVG graphic generation and website building, Claude Opus 4.6 still performs better, demonstrating stronger spatial reasoning and creative integration
- In complex reasoning tests, Gemini 3.1 Pro achieved a qualitative leap from 3.0 to 3.1, with inductive reasoning reaching parity with Opus 4.6
- Gemini 3.1 Pro adds three thinking levels and a million-token context window (~750,000 English words), offering unique advantages in research and analysis scenarios
- Practical recommendation: Adopt a "Model Routing" strategy — use Gemini 3.1 Pro as a cost-effective daily model and reserve Opus 4.6 for complex tasks to achieve the optimal balance between quality and cost
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.