Gemini 3.5 Flash Falls Flat: Great Benchmarks, Terrible Real-World Performance, and a Buggy CLI
Gemini 3.5 Flash Falls Flat: Great Ben…
Gemini 3.5 Flash aces benchmarks but fails real-world coding, with 20x price hikes and no self-correction.
Google I/O's Gemini 3.5 Flash delivers impressive benchmark scores but reveals serious issues: pricing jumped 3-20x over predecessors, token consumption is 3.3x that of GPT-5.5, and it was the only model unable to complete a game rewriting task in real-world coding tests. The root cause appears to be Google's failure to master reinforcement learning fundamentals, leaving the model unable to self-check or self-correct — exposing a massive gap between benchmark performance and practical capability.
A Reality Check After Google I/O: Gemini 3.5 Flash's True Performance
Google I/O just wrapped up, with Gemini 3.5 Flash unveiled as a flagship release boasting impressive benchmark numbers. However, after getting early access, well-known tech creator Theo delivered a starkly different verdict — the model performed terribly in real-world coding tasks, its companion CLI tool was riddled with bugs, and Google Cloud managed to ban a major customer on the same day. Even more disheartening, Google's talented open-source teams were sidelined in favor of a closed-source product whose demo couldn't even hide its plagiarism.
Gemini 3.5 Flash: Great Benchmarks, but a 20x Price Hike
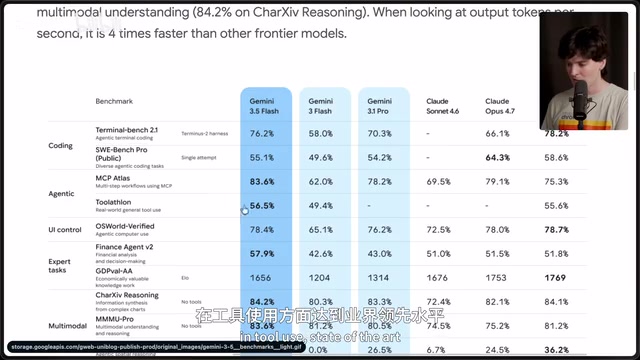
On paper, Gemini 3.5 Flash looks impressive. It outperforms Gemini 3.1 Pro on nearly every benchmark, scores just behind GPT-5.5 on Terminal Bench, and achieves state-of-the-art results across multiple dimensions including Toolathon, financial agents, and reasoning. Artificial Analysis's intelligence index shows it leading the pack in speed-to-performance ratio, with a generation speed approaching 300 tokens/second.
It's worth noting that AI benchmark systems have systemic limitations. Current mainstream evaluations like MMLU, HumanEval, and Terminal Bench essentially measure a model's "test-taking ability" on specific datasets, not real-world engineering capability. The industry calls this "Benchmark Overfitting" — models score high through targeted training on test sets without corresponding improvements in generalization. While third-party evaluators like Artificial Analysis incorporate dimensions like speed and cost, they still struggle to capture a critical ability: whether a model can self-correct during complex, multi-step real-world tasks. This is precisely why Gemini 3.5 Flash can surpass Gemini 3.1 Pro on paper yet completely fail in practical coding tests — the latter demands execution loops, error awareness, and iterative repair, all of which are blind spots in current benchmarks.
But Google deliberately hid a key detail on the release page: pricing. Not a single dollar sign anywhere. The reason is simple — they tripled the price. 3.5 Flash is priced at $1.50/million input tokens and $9/million output tokens. Compared to the previous 3 Flash at $0.50 input and $3 output, that's a 3x increase. Compared to Theo's favorite, 2.0 Flash ($0.10 input, $0.40 output), the increase exceeds 20x.
Even worse is the token efficiency problem. Token Efficiency is a critical metric for evaluating the actual cost of reasoning models, yet it's deliberately downplayed in most marketing materials. The core difference between reasoning models and standard language models is that the former generates extensive "Chain-of-Thought" content before delivering a final answer, and these intermediate reasoning steps all count toward token consumption. As a reasoning model, 3.5 Flash consumed approximately 72 million tokens in Artificial Analysis's benchmarks, while OpenAI's GPT-5.5 Medium used only 22 million — less than a third. This 3.3x gap means that even with lower unit pricing, the total bill could be higher. This reveals a core trade-off in reasoning model design: longer chains of thought typically yield more accurate answers but also higher latency and cost. A well-designed reasoning model needs to learn "thinking in moderation" — converging quickly on simple tasks while going deep on complex ones. 3.5 Flash has become the fourth most expensive model in these benchmarks, costing nearly twice as much as 3.1 Pro in practice.
What good is speed? If a model is 2x faster but generates 4x the tokens, the task actually takes longer to complete. Poor token efficiency isn't just a cost issue — it signals a fundamental inability to know when to stop thinking.
Real-World AI Coding Test: The Only Model That Failed
Theo ran a practical test using his in-development game Fish Slop: he gave each model the original source code and asked it to rewrite the codebase to be more stable and cleaner. The result was shocking — Gemini 3.5 Flash was the only model among all those tested that couldn't get the game running.
The code it produced was broken out of the box, and it never self-checked or ran validation. When Theo asked it to fix the issues, the "fixed" version was even worse: ugly halo effects appeared on screen, fish were too large to interact with, the feeding mechanism didn't work, the aging mechanism didn't work, newly generated images were low quality, and some didn't even have transparency set correctly.
By contrast, GPT-5.5 not only completed the same task flawlessly — Theo even asked it to convert the game to 3D, and it delivered. For a supposedly state-of-the-art model to turn in work like this, Theo called it "a genuine embarrassment."
The core issue appears to be that Google still hasn't cracked RL (Reinforcement Learning) — the model doesn't know how to check its own work, doesn't know how to self-correct, and just burns tokens aimlessly. This points to a critical technical divide in today's AI coding assistants. Traditional LLM training relies on supervised fine-tuning (SFT), where models learn "what to output given an input" but lack the ability to verify whether their output is correct. OpenAI's extensive use of RLHF (Reinforcement Learning from Human Feedback) and RLEF (Reinforcement Learning from Execution Feedback) in their o-series models taught models a meta-ability: run code, observe results, and adjust strategy based on error signals. This "think-execute-verify" loop (also known as an Agent Loop or ReAct framework) is the key to GPT-5.5's ability to complete complex game rewriting tasks. The description of Gemini 3.5 Flash "just burning tokens aimlessly" is a textbook symptom of lacking execution feedback training — the model hasn't internalized the need to verify whether its generated code actually runs.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.