Gemini 3 Flash In-Depth Review: Comprehensive Testing of Coding, Multimodal, and Writing Capabilities
Gemini 3 Flash surprisingly outperforms the flagship Pro version across multiple benchmarks.
Google's lightweight Gemini 3 Flash model unexpectedly surpasses its flagship Gemini 3 Pro in multiple benchmarks including AICI AGI 2, MMMU Pro, and SWE-Bench Verified. This is attributed to Knowledge Distillation and Test-Time Compute Scaling mechanisms. In hands-on testing, Flash delivers impressive results in frontend code generation and Cursor programming workflows, though some gaps remain versus Pro on fine-grained tasks. Overall, Flash offers near or superior Pro-level capabilities at a lower price point.
Google's newly released Gemini 3 Flash has caused quite a stir in the AI community — a model positioned as lightweight has actually outperformed its own flagship Pro version in multiple benchmark tests. What's going on here? This article provides a comprehensive test and in-depth analysis of Gemini 3 Flash across multiple dimensions including coding, multimodal understanding, and writing.

Benchmark Scores: Gemini 3 Flash's Surprising Upset Over Pro
According to Google's officially published data, Gemini 3 Flash's performance across several key benchmarks is quite surprising:
- AICI AGI 2 Benchmark: Flash scored higher than Gemini 3 Pro
- MMMU Pro Benchmark: Also surpassed Gemini 3 Pro
- SWE-Bench Verified (Coding Benchmark): Flash achieved 78%, exceeding Pro's 76.2%
In other words, Flash has overtaken Pro across three core dimensions: reasoning, multimodal understanding, and coding ability.
Why can a lightweight model outperform the flagship version? This involves Knowledge Distillation technology. Knowledge Distillation was proposed by Hinton et al. in 2015, with the core idea being that a small model (student) learns the output distribution of a large model (teacher), rather than directly learning from raw labels. This allows the smaller model to inherit the reasoning capabilities and generalization properties of the larger model despite having significantly fewer parameters. The Flash series has fewer parameters compared to the Pro series, but through distillation from Pro or the even larger Ultra model, it can actually surpass the teacher model on specific tasks — this is known as the "student surpassing the teacher" phenomenon in machine learning, which typically occurs when distillation data quality is extremely high, or when the student model has lower overfitting on specific tasks. From 1.5 to 2.0, 2.5, and now 3.0, the capability improvements of the Flash series have far exceeded expectations.
Regarding pricing, Gemini 3 Flash is somewhat more expensive than the previous 2.5 Flash, but still significantly cheaper than the Pro version.
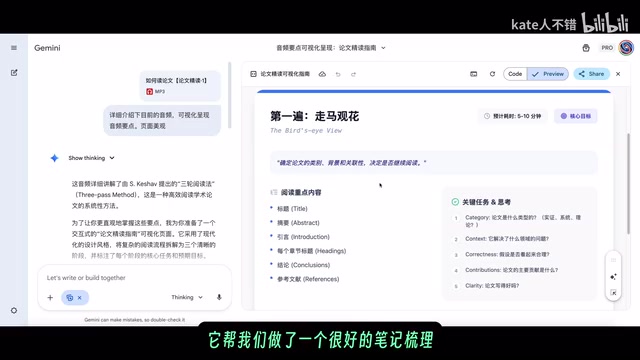
About the benchmarks themselves: SWE-Bench Verified is a code capability evaluation benchmark proposed by Princeton University in 2023, specifically designed to measure an AI model's ability to solve real GitHub Issues. Unlike traditional code completion or algorithm problems, SWE-Bench requires models to read real open-source project codebases, understand bug reports, and generate patches that pass unit tests. The Verified version is a human-curated subset ensuring test case quality, containing 500 tasks total, and is considered the closest existing benchmark to real software engineering scenarios. A 78% pass rate means the model can independently solve nearly three-quarters of real engineering problems — a figure that was almost unimaginable in early 2024, when the strongest models scored only in the 10%-20% range. MMMU Pro is a high-difficulty benchmark specifically designed to evaluate multimodal large models, covering 11 disciplinary areas including art, business, science, medicine, and engineering. Human experts average about 55%-65% on this benchmark, so Flash's ability to surpass Pro here indicates that its vision-language joint reasoning capability has reached a remarkably high level.
Gemini 3 Flash also supports 4 thinking levels, making it more flexible than the Pro version. This is essentially an engineering implementation of Test-Time Compute Scaling — a concept stemming from the industry shift triggered by OpenAI's o1 series: investing more computation during inference (letting the model "think longer") can significantly improve performance, especially on tasks requiring multi-step reasoning like mathematics and logical reasoning. Higher thinking levels mean longer internal reasoning chains generated by the model, more tokens consumed, and higher latency, but accuracy improves accordingly. At the highest thinking level, it can intelligently adjust thinking depth; when handling everyday tasks, it reduces token consumption by an average of 30% compared to 2.5 Pro. A user on Hacker News stated plainly that this is their "new favorite," for simple reasons: it's fast and has broad world knowledge coverage.
Coding Capability Testing: Impressive Results Paired with Cursor
Frontend Page Generation Test
In testing, Gemini 3 Flash demonstrated quite impressive frontend code generation capabilities. When generating a "New Weird" style webpage, even using just Fast mode, the page design was quite aesthetically pleasing.
An interesting detail: In Flash's generated "Sheep Barbershop" page, the ceiling fan rotation animation at the top was very smooth, and hovering over elements triggered tooltips — an interaction detail that many models hadn't handled before. However, a slight disappointment was the absence of a "sheep barber" character on the page.
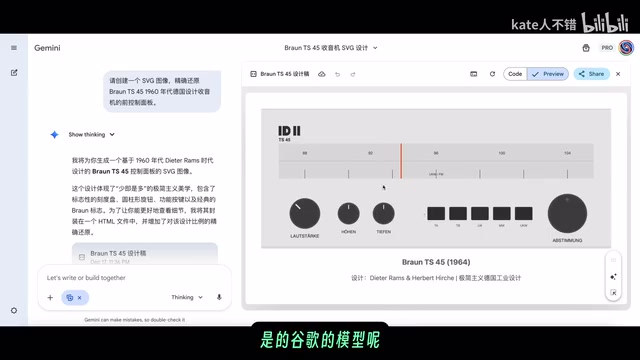
When generating SVGs of a radio front control panel, Flash showed some missing details compared to Gemini 3 Pro. This demonstrates that while Flash surpasses Pro in benchmark tests, gaps still exist in certain fine-grained tasks.
Programming Performance in Cursor
Cursor is an AI-native code editor deeply modified from VS Code. Its Plan mode (also called Agent mode) represents the current best practice paradigm for AI-assisted programming: first having the model analyze requirements and formulate a step-by-step plan, then executing progressively with verification after each step. This "chain-of-thought + tool calling" workflow is essentially an engineering implementation of the ReAct (Reasoning + Acting) framework. Compared to generating code all at once in a chat box, Plan mode decomposes complex tasks into verifiable subtasks, allowing the model to read files, run code, and view error outputs during execution, forming a closed feedback loop, while also giving users the opportunity to intervene and correct at critical junctures.
Using Cursor's Plan mode with Gemini 3 Flash, multiple complex projects were tested:
- DNA 3D Visualization: Quite impressive results with fast generation speed
- Periodic Table: The overall page was slightly inferior to Gemini 3 Pro, but supported intuitive comparison of any two elements
- Terracotta Warriors Dancing: Clicking "Awaken the Qin Dynasty Dance King"
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.