Generic Agent: An Open-Source AI Agent That Uses Only One-Tenth the Tokens of Comparable Products
Generic Agent achieves 90% token reduction through context engineering for efficient AI Agent execution.
Generic Agent is an open-source AI Agent project whose core philosophy is maximizing the value of every token rather than context length. Through four key mechanisms—a minimalist 9-tool set, four-layer memory hierarchy, proactive context slimming, and experience reuse—it reduces token consumption from 220K to 23K between first and ninth execution of the same task, saving nearly 90%. It supports multi-platform operation including computer, browser, and Feishu, features autonomous action capabilities, is fully open-source, and is compatible with mainstream LLMs.
Introduction: How Much of Your AI Spending Is Being Wasted?
For the same simple "hello" message, some AI agents consume over 40,000 tokens while others need only 2,000—a staggering 20x difference. This isn't a gap in model capability; it's a gap in resource efficiency.
Tokens are the basic unit of measurement for how large language models process text—think of them as the smallest granules the model "reads" and "generates." A single Chinese character typically consumes 1-3 tokens, and the cost of each API call is directly tied to token consumption. Taking Claude 3.5 Sonnet as an example, input tokens cost approximately $3 per million tokens, while output costs $15. For enterprise applications that frequently call AI, a 20x difference in token consumption means a 20x difference in cost—directly determining whether an AI Agent solution is commercially sustainable.
The project we're introducing today, Generic Agent (GA for short), is an open-source AI Agent whose core philosophy isn't pursuing longer context lengths, but rather maximizing the value of every single token. Real-world testing shows that for the same task, token consumption drops from 220,000 on the first execution to just 23,000 by the ninth—a savings of nearly 90%.
GA's Ten Core Capabilities: Not Just Chat, But Real Work
Generic Agent isn't an AI that only knows how to chat—it's an intelligent assistant that can actually operate your computer, browser, and office software. An AI Agent refers to an AI system capable of perceiving its environment, making decisions, and taking actions, distinguishing it from traditional Q&A chatbots. Since AutoGPT ignited the Agent craze in 2023, the industry has undergone a paradigm shift from "giving AI more tools" to "helping AI use tools more efficiently." Early agents like AutoGPT and BabyAGI often fell into infinite loops and token explosions, while the new generation of agents has begun focusing on execution efficiency and task completion rates under resource constraints.
Specifically, GA possesses ten core capabilities:
- Computer Operation: Organize desktop files, search across all drives
- Browser Operation: Use your logged-in browser to search for information and browse web pages
- Preference Memory: Remember your habits so you don't have to repeat yourself
- Self-Evolution: Gets faster and cheaper the more you use it
- Parallel Execution: Spawn clones to handle multiple tasks simultaneously
- Scheduled Tasks: Set times for automatic execution
- Feishu Integration: Covers 22 functional modules including calendar, cloud documents, and multi-dimensional tables
- Full-Disk Search: Find the files you need in seconds
- Screen Understanding: Comprehend charts and content displayed on screen
- Multi-Platform Access: Supports WeChat, DingTalk, QQ, and other messaging tools
Autonomous Action Mode: Like Hiring a Reliable Intern
GA has two particularly noteworthy advanced modes:
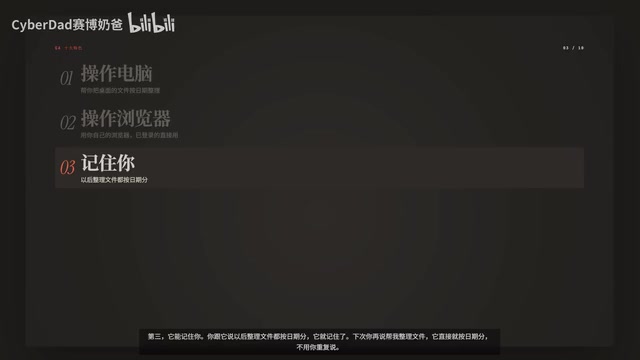
Task List Mode
You write GA a task list, then walk away. When GA detects you haven't returned for 30 minutes, it automatically picks tasks from the list and starts executing them. When you come back, it hands you a completion report.
Go Mode
Give GA an open-ended goal and a time budget, and it plans, executes, and iterates on its own. For example, "Spend three hours optimizing my blog's SEO"—when time's up, it automatically wraps up and outputs a summary report. It's like hiring hourly help—you leave to run errands, and when you come back, the house is already clean.
Technical Core: Maximizing Context Information Density
GA's most brilliant design lies in the shift from Prompt Engineering to Context Engineering. Context Engineering is a concept that emerged in 2024, popularized by figures like Shopify CEO Tobi Lütke. The difference from Prompt Engineering is this: Prompt Engineering focuses on "how to write a good instruction," while Context Engineering focuses on "how to manage all the information the AI can see throughout the entire interaction process." This includes system prompts, conversation history, tool return values, retrieved documents—everything that enters the context window. In Agent scenarios, a single complex task may involve dozens of rounds of tool calls; without context management, the window quickly fills with useless information.
GA doesn't just help you say things better—it ensures that every single character the AI sees throughout the entire conversation is useful.
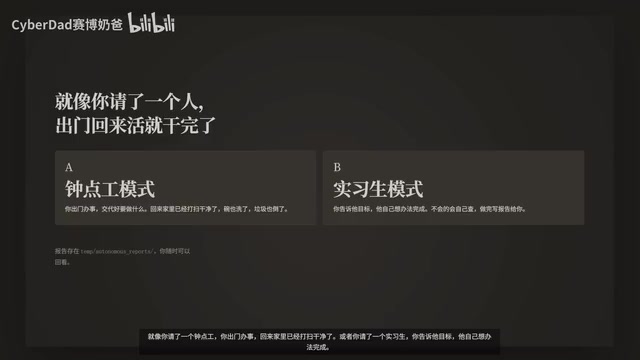
Here's an analogy: The AI's context window is like a desk—the surface area is fixed. Other AIs spread everything across the desk until it's full and hard to find anything. GA's approach is to only place what's most needed on the desk, storing everything else in drawers to be retrieved when necessary.
This is achieved through four key designs:
Strategy #1: Minimalist Tool Set—9 Tools Handle Everything
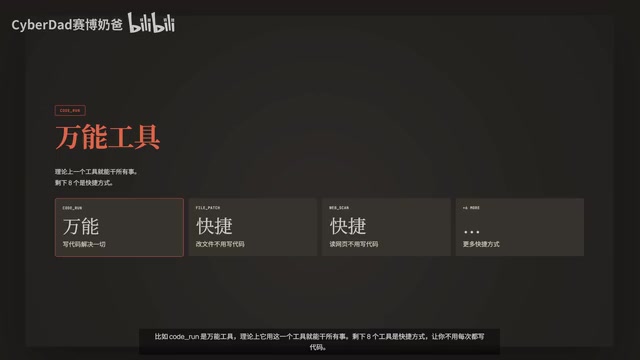
In the AI Agent field, tools (Tool/Function) are the interfaces through which agents interact with the external world. The industry has two design philosophies: one is the "specialized tools" approach, designing independent tools for each specific operation (like OpenAI's Function Calling ecosystem); the other is the "universal tools" approach, using a small number of highly abstract tools to cover all scenarios. GA chose the latter because: every additional tool requires the model to carry that tool's description in the context (typically 100-500 tokens). With 53 tools, descriptions alone could consume over 10,000 tokens, while 9 tools have minimal description overhead, leaving more context space for actual task execution.
Experiments prove that GA accomplishes with 9 tools what other systems need 53 tools to do, with a 100% task success rate and only one-third the token consumption of other systems.
Among these, Code Wrong is the universal tool—theoretically, this single tool can do everything. The remaining 8 are shortcuts so you don't have to write code every time. For example, File Patch requires exact matching—if it can't find a match or finds too many, it throws an error immediately rather than silently modifying the wrong location. Web Scan performs semantic compression, compressing tens of thousands of tokens of raw HTML down to a few thousand without losing any key information.
Strategy #2: Four-Layer Memory Hierarchy System
GA's four-layer memory hierarchy is essentially a RAG (Retrieval-Augmented Generation) architecture optimized for Agent scenarios. Traditional RAG stores all knowledge in a vector database for unified retrieval, but this approach cannot distinguish between the different retrieval needs of "facts" versus "procedures." GA separates memory by purpose, with each layer serving a different role:
- Layer 1: Directory Index Desk—Only a few dozen lines, never bloating regardless of how much experience accumulates. Similar to a library's index cards, helping the Agent quickly locate which layer contains the needed information
- Layer 2: Encyclopedia Section—Stores verified facts (such as server IPs, project versions) with an extremely high admission threshold. Similar to a peer-reviewed knowledge base, ensuring information accuracy
- Layer 3: Operations Manual Section—Stores reusable process SOPs. Similar to standard operating procedure documents, recording step sequences for completing specific tasks
- Core Principle: No Execution No Memory—Only experiences that have been verified through successful execution can be written to long-term memory. This principle ensures memory reliability, prevents LLM hallucinations from polluting the knowledge base, and is the key design that distinguishes GA's memory system from ordinary RAG
Strategy #3: Proactive Context Slimming
A large language model's context window is the maximum text length it can process at once, currently ranging from 128K to 200K tokens for mainstream models. However, research shows that even when the window is large enough, the model's attention to information in middle positions drops significantly (the "Lost in the Middle" phenomenon, identified in a 2023 Stanford paper). Therefore, GA's compression strategy isn't just about saving token costs—it's about improving the model's attention concentration on key information.
GA has a four-stage compression pipeline: tool return value compression → message compression → message eviction → anchor injection. Each cleanup doesn't trim to just under budget, but to 60% of budget, leaving 40% headroom to avoid frequent cleanup triggers. This strategy borrows from the watermark mechanism in operating system memory management—similar to the kswapd daemon in the Linux kernel, which begins reclaiming memory when usage reaches the high watermark rather than waiting until complete exhaustion triggers emergency reclamation, thereby avoiding performance jitter.
Strategy #4: Experience Reuse Mechanism
After completing a task, GA automatically writes the experience into an operations manual. Different but similar tasks can also reuse it. This mechanism is similar to human "procedural memory"—the first time you cook a dish, you need to repeatedly check the recipe, but after doing it several times, you can complete it from muscle memory. GA abstracts successful execution paths into reusable SOPs, calling them directly when encountering similar tasks next time, skipping the exploration and trial-and-error phases.
Experimental data: Across 8 different web tasks, the second execution saved 60% to 92% of tokens compared to the first.
Three Stages of Self-Evolution: 90% Reduction in Token Consumption
GA's evolution path is crystal clear:
| Stage | Execution # | Token Consumption | Time | Characteristics |
|---|---|---|---|---|
| Jungle Exploration | 1st | 220K | 7.5 min | Heavy reasoning and trial-and-error |
| Follow the Manual | 5th | 35K | 2.5 min | Execute according to SOP |
| Run the Script | 9th | 23K | 1.5 min | Directly invoke experience |
From the first to the ninth execution, token consumption drops by nearly 90%—this is the underlying logic behind Generic Agent's "cheaper the more you use it" promise. This evolution curve closely mirrors the "power law learning curve" of human skill acquisition—fastest progress at the beginning, gradually stabilizing over time. For high-frequency repetitive tasks (such as daily report generation or periodic data scraping), GA's cost advantage continues to amplify with increasing usage.
Real-World Use Cases
GA's application scenarios cover both daily work and life:
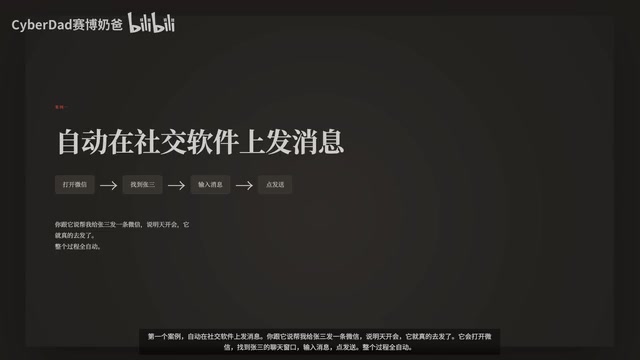
- Auto-Send Messages: Tell GA "Send a WeChat message to Zhang San saying there's a meeting tomorrow," and it will open WeChat, find the contact, type the message, and hit send—fully automated
- Browse Trending Content: Help you check trending Bilibili videos, summarize top comments, and even draft comments for your review
- Personality Analysis: Analyze your social media posts and generate a personality report
- Batch Downloads: Help you download Bilibili videos with batch operation support
Installation and Usage Guide
Generic Agent installation requires just three steps: Install Python → Download the project → Configure API Key.
It supports virtually all mainstream LLMs: Claude, GPT, DeepSeek, Zhipu, Minimax, Kimi, Doubao, and even local models. Local model support means you can run open-source models (such as Llama, Qwen, etc.) on your own computer through tools like Ollama, achieving completely offline usage where data never leaves your machine—balancing privacy security with zero API costs.
Project Links:
- GitHub: Search
else-defined/generic-agent - Tutorial:
data-whale-china/hello-generic-agent
Both projects are completely free and open-source.
Conclusion: A New AI Agent Paradigm for Doing More with Fewer Tokens
Generic Agent represents an important direction in AI Agent development: it's not about who has the longer context window, but who can do more with fewer tokens. Through its four core mechanisms—minimalist tool design, four-layer memory hierarchy, proactive context slimming, and experience reuse—it achieves the remarkable efficiency of consuming only one-tenth the tokens of comparable products.
From a broader perspective, GA's design philosophy reflects an important shift happening in the AI Agent field: from "brute-force compute" to "refined operations." Just as cloud computing evolved from initial "on-demand scaling" to FinOps (cloud financial operations), AI Agents are evolving from "can it be done" to "can it be done efficiently." In an era where LLM API prices haven't yet dropped to negligible levels, token efficiency may be the key factor determining whether an Agent solution can achieve large-scale deployment.
For individual users and enterprises sensitive to token costs, this may be one of the most worthwhile open-source AI Agent solutions to try right now. Give it a day, and it will evolve into your personalized assistant.
Key Takeaways
- Generic Agent achieves token consumption of just 1/10 of comparable AI Agents through maximized context information density design, saving nearly 90% from first to ninth execution of the same task
- Core technology includes four mechanisms: minimalist 9-tool set, four-layer memory hierarchy, proactive context slimming (four-stage compression pipeline), and experience reuse (No Execution No Memory principle)
- GA possesses autonomous action capabilities, supporting Task List Mode and Go Mode for unattended task execution with report generation
- Supports multi-platform operation including computer, browser, Feishu, WeChat, and more, covering ten core capabilities from file management to information search to scheduled tasks
- Completely open-source and free, supporting Claude, GPT, DeepSeek, and virtually all mainstream LLMs, with installation completed in just three steps
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.