Google Gemma 4 Hands-On Review: Offline on Smartphones + Ollama Deployment Tutorial

Google Gemma 4 open-source models enable local on-phone AI with privacy and performance balanced.
Google released the Gemma 4 series of open-source models (1B to 31B parameters) that achieve full-scenario local deployment from phones to workstations through quantization and MOE architecture. Real-world tests show small models still struggle with common sense reasoning but excel at tool-type tasks like document recognition and code completion, all while running completely locally to protect data privacy. The article includes a complete Ollama + Claude Code deployment tutorial.
Google's recently released Gemma 4 series of open-source models is nothing short of an engineering marvel — essentially "fitting a supercomputer brain into a phone." Ranging from the lightweight 2B-parameter version to the flagship 31B, it covers every scenario from smartphones to workstations. A Chinese tech YouTuber conducted a real-world comparison test across three phones and provided a complete Ollama + Claude Code deployment tutorial. Let's take a look at how this model actually performs.
Gemma 4's Technical Background and Position in the Open-Source Ecosystem
Google's Gemma series derives from its internal Gemini large model technology stack, sharing the same research breakthroughs and training methodologies but released at smaller parameter scales under an open-source license. This strategy has established Google's strong influence in the open-source AI community, putting it in direct competition with Meta's LLaMA series. The timing of Gemma 4's release coincides with the explosion of on-device AI demand — chipmakers like Qualcomm and MediaTek have been integrating dedicated NPUs (Neural Processing Units) into mobile SoCs, providing the hardware foundation for local large model inference. It's precisely this simultaneous maturation of software and hardware ecosystems that has turned "running large models on phones" from concept into reality.
Gemma 4's Four Models Cover Every Scenario
The Gemma 4 series launched four models, precisely targeting users with different hardware capabilities:
1B/2B (Nano-tier): The lightest versions — runnable on phones and even Raspberry Pi, with built-in speech recognition. After quantization, they require only 4GB of VRAM. This is a true "pocket AI." The "quantization" mentioned here is a critical model compression technique — original models typically store parameter weights in FP32 (32-bit floating point) or FP16 (16-bit floating point), while quantization reduces this to INT8 (8-bit integer) or even INT4 (4-bit integer) precision. This sacrifices a small amount of inference accuracy but can reduce model size and VRAM usage by 4-8x while significantly boosting inference speed. Common quantization formats include GPTQ, AWQ, and GGUF, with GGUF being the default format used by Ollama, optimized specifically for CPU and hybrid inference scenarios.
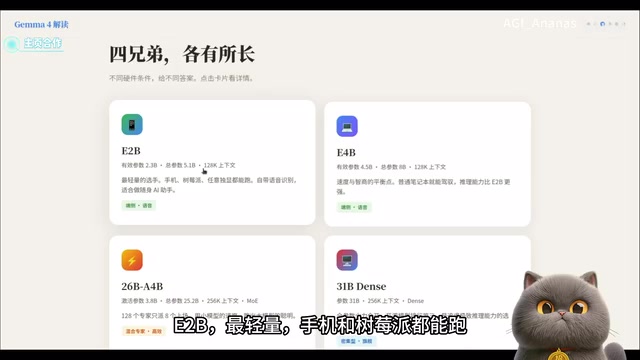
4B (Quadro-tier): The sweet spot for laptops, striking a balance between speed and capability.
26B (MOE Mixture of Experts architecture): Total parameters of 25B, but only 3.8B parameters are activated per inference — doing big-model work at small-model cost, offering exceptional value.
31B (Dense flagship): Full-parameter inference, ranking third on open-source model leaderboards, suitable for users with high-end GPUs.
Dense vs MOE: The Key Concept for Understanding Gemma 4
To understand the Gemma 4 series, there's one core concept you must grasp — the difference between Dense and MOE (Mixture of Experts).
In Dense mode, all parameters participate in computation during every inference pass. 31B means 31 billion operations, no shortcuts. The advantage is stable results; the downside is slower speed and higher VRAM consumption.
MOE mode works completely differently. The model contains 128 internal "experts," but only 8 are deployed for each inference while the rest stand by. This means that although the total parameter count is large, the actual computational load is drastically reduced.
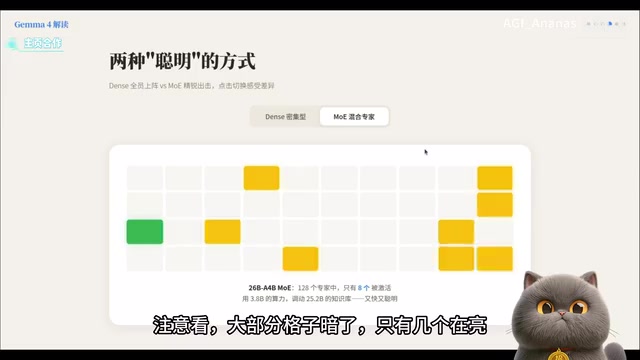
The image above intuitively demonstrates how MOE works: most "cells" are in a darkened state, with only a few lit up — this is the essence of the Mixture of Experts architecture. Fewer computational resources yield inference capabilities approaching those of much larger models.
Deep Dive into MOE Architecture
The Mixture of Experts architecture was first proposed by Hinton et al. in 1991, but it wasn't until Google's Switch Transformer in 2022 and Mistral AI's subsequent release of Mixtral that it entered mainstream applications. The core components of MOE include two parts: multiple expert networks (typically the feed-forward neural network layers in Transformers) and a gating network (Router/Gating Network). The gating network determines which experts should process each input token based on its semantic features.
The mathematical advantage of this design is that the model's total parameter count (which determines the upper bound of knowledge capacity) can be made very large, while the actual computation per forward pass (FLOPs) is only proportional to the number of activated experts. Gemma 4's 26B MOE model has 128 experts but activates only 8 at a time, meaning its inference computational cost is equivalent to a 3.8B Dense model, yet it possesses knowledge reserves and generalization capabilities approaching a 25B model. This explains why MOE models have an overwhelming advantage in the "cost-performance" dimension.
However, MOE architecture also has its challenges: expert load balancing (avoiding some experts being overused while others sit idle), training stability, and the overall model size remaining large (although inference is fast, all expert weights need to be loaded into memory). Gemma 4's engineering optimizations in these areas represent current industry best practices.
Three-Phone Real-World Test: Local Offline Performance
The test ran Gemma 4's 1/2B models on three phones in a completely offline environment, covering three classic problems: a gas station logic problem, a brain teaser, and a character frequency counting problem.
The test results revealed two key findings:
-
Common sense reasoning remains a weakness for small models: On questions requiring common sense reasoning, small-parameter models still perform inadequately — a universal issue across all lightweight models today. The fundamental reason is that common sense reasoning requires models to build implicit knowledge representations of the real world during training, and this capability is highly correlated with parameter count — fewer parameters mean less world knowledge can be encoded. Current mainstream academic approaches include: Retrieval-Augmented Generation (RAG) to supplement small models with external knowledge, distilling reasoning capabilities from large models into small ones, and using Chain-of-Thought prompting to guide small models through step-by-step reasoning.
-
Hardware differences are significant: Among the three phones, the iQOO 15 ran fastest, demonstrating that a chip's AI computing power has a massive impact on local inference experience. NPUs in modern mobile SoCs (such as Qualcomm's Hexagon, MediaTek's APU, and Samsung's Exynos NPU) are specifically hardware-accelerated for matrix operations and low-precision inference, with INT8 performance reaching tens of TOPS (Tera Operations Per Second) — this is the hardware foundation enabling smooth local large model operation. Architectural differences between NPUs directly determine the upper limit of inference speed.
Gemma 4's Capability Boundaries: Proper Positioning as a Tool-Type AI
Gemma 4's strengths are very clear: document recognition, invoice parsing, code completion, long-document Q&A, and Agent automation tasks. More importantly, all of this runs locally — your data never needs to be uploaded to someone else's server, which is hugely significant for privacy-sensitive scenarios.

The privacy value of locally deployed large models goes beyond simply "not uploading data." In enterprise scenarios, this involves compliance requirements under GDPR (EU General Data Protection Regulation), China's Data Security Law, and Personal Information Protection Law. Many industries (such as healthcare, finance, and legal) have sensitive data that simply cannot leave the local network environment. On-device AI enables these regulated industries to enjoy the productivity gains of large models without facing complex compliance challenges like cross-border data transfers and third-party data processing agreements. Additionally, local inference eliminates network latency and API service outage risks, ensuring business continuity.
But its weaknesses must also be acknowledged:
- Can it replace Claude or GPT? Clearly not. Cloud-based large models (like GPT-4, Claude 3.5) typically have parameter scales in the hundreds of billions or even trillions, and have undergone extensive RLHF (Reinforcement Learning from Human Feedback) alignment training, far exceeding current open-source lightweight models in complex reasoning, creative writing, and multi-turn dialogue.
- High-quality writing? Barely passable, but don't set expectations too high.
- Large-scale code refactoring? Still far from capable at current levels.
To summarize in the YouTuber's own words: "Gemma 4 is an exceptionally excellent local tool-type AI. Use it as an efficient tool and it won't disappoint you; use it as an all-knowing brain and you'll be very disappointed." This positioning is spot-on.
Hands-On Tutorial: Deploying Gemma 4 with Ollama + Claude Code
Mobile Deployment
For mobile users, it's simplest — just go to Google's AI Edge Gallery to download and use it directly, no additional configuration needed.
Desktop: One-Click Gemma 4 Deployment with Ollama
Desktop deployment via Ollama is equally convenient. Ollama is an open-source local large model runtime framework that wraps the llama.cpp inference engine underneath, providing a Docker-like model management experience. Users don't need to manually handle model format conversion, memory mapping, or GPU scheduling. Ollama supports GGUF format models and can automatically detect the system's GPU (NVIDIA CUDA, AMD ROCm, Apple Metal) to perform optimal model layer allocation — when GPU VRAM is insufficient, it automatically offloads some model layers to CPU memory (the so-called offloading strategy), trading a small amount of speed for runnability. Its built-in HTTP API server is compatible with the OpenAI API format, allowing virtually any application that supports the OpenAI interface to seamlessly switch to local models.
Here are the complete deployment steps:
Step 1: Download and Run the Model
Make sure Ollama is installed on your computer, then execute:
ollama run gemma4:e4b
Wait for the model download to complete — approximately 9.6GB total. Once downloaded successfully, you can test Q&A directly in the terminal.
Step 2: Configure Claude Code to Call the Local Model
Claude Code is Anthropic's command-line AI programming assistant, originally relying on cloud-based Claude models. Configuring it to call a local Ollama model essentially leverages Claude Code's excellent interactive interface and tool-calling framework (such as file read/write, command execution, etc.) while replacing the inference backend with a locally running open-source model. This architectural separation (decoupling the frontend interaction layer from the backend inference layer) is an important design trend in current AI toolchains, allowing users to flexibly switch between different model backends based on task complexity, privacy requirements, and cost budgets.
Specific configuration steps:
- Copy the model ID
- Clone the project repository and enter the project directory
- Run the installation command to download dependencies
- Enter the guided setup interface and select color mode
- Select the "Local Ollama model" option
- Paste the model ID and press Enter to confirm
Once configured, you can directly call the local Gemma 4 model for Q&A within Claude Code. The first request takes about 38 seconds for model loading (the model needs to be loaded from disk into GPU VRAM), but subsequent responses will be faster since the model stays in memory until it times out.
Switching models: Logged-in users can type /logout to exit, then run the configuration command to re-select a model.
Conclusion: Gemma 4's Value and Limitations
The release of the Gemma 4 series marks an important step forward for open-source models in the "on-device deployment" direction. Running a large model with just 4GB of VRAM was unimaginable a year ago.
For everyday users, Gemma 4's greatest value lies in privacy protection and zero-cost usage — no API key needed, no network connection required, no worries about data leaks. For developers, the engineering implementation of MOE architecture provides a referenceable paradigm for future lightweight models. From a broader perspective, Gemma 4 represents an important milestone in AI democratization: when powerful AI capabilities are no longer monopolized by a few cloud service providers but can run on everyone's devices, the innovation space for the entire AI application ecosystem will be vastly expanded.
Of course, we must also rationally acknowledge its limitations. Small models' shortcomings in common sense reasoning, complex writing, and large-scale code engineering are difficult to fully overcome through architectural optimization alone in the short term — improving these capabilities fundamentally depends on larger parameter scales and richer training data. Choosing the right scenarios and using the right tools is the key to maximizing Gemma 4's value.
The model weights are now available for download on Hugging Face and Kaggle — interested readers can get started immediately.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.