GPT-5.1 vs Claude Sonnet 4.5 Hands-On Comparison: Coding, Writing, and Creativity Benchmarked

Multi-dimensional testing shows Claude Sonnet 4.5 outperforms GPT-5.1 in most scenarios.
A Bilibili creator ran a comprehensive head-to-head test of GPT-5.1 and Claude Sonnet 4.5 across long-form text generation, classical Chinese poetry, front-end coding, and more. Claude led clearly in most categories, while GPT-5.1 showed a unique edge only in browser automation tasks. Overall, GPT-5.1 has improved over its predecessor but still falls short of Claude.
OpenAI has released the GPT-5.1 series, claiming it's 2x faster than GPT-5 on simple tasks, delivers 2x deeper performance on complex tasks, and reduces hallucinations by 56%. But how does it actually perform? A Bilibili creator ran a comprehensive multi-dimensional test pitting GPT-5.1 against Claude Sonnet 4.5 — and the results were quite surprising.
GPT-5.1 is OpenAI's iterative update built on GPT-5, continuing the recent release strategy of rapid minor-version iterations on top of major versions. The "2x faster on simple tasks" claim primarily refers to reduced inference latency, typically achieved through optimization techniques like model distillation and Speculative Decoding. The "2x deeper on complex tasks" involves enhanced Chain-of-Thought reasoning capabilities. As for the "56% fewer hallucinations" — hallucination is a core challenge in the large language model space, referring to content that sounds plausible but is factually incorrect or entirely fabricated. OpenAI typically mitigates this through Reinforcement Learning from Human Feedback (RLHF), Retrieval-Augmented Generation (RAG), and higher-quality training data. On the other side, Claude Sonnet 4.5 comes from Anthropic, founded by former OpenAI research VP Dario Amodei, and the company's models are known for their safety focus and strong long-context processing capabilities.
Long-Form Text Generation: Claude Leads by a Wide Margin
Both models were asked to generate a 10,000-character study report based on an open-source project. The results: Claude Sonnet 4.5 produced over 51,000 total characters (12,000+ Chinese characters), while GPT-5.1 managed only 31,000+ total characters (6,900 Chinese characters). Claude's long-form output was nearly double that of GPT-5.1.
Long-form generation capability is constrained by a model's context window size and maximum output token limit. Claude Sonnet 4.5 supports up to a 200K token context window and maintains strong coherence in long outputs, thanks to Anthropic's dedicated optimization for long-sequence data during training. Long-form generation also faces the "attention decay" problem — as generated content grows longer, the model's attention to earlier context diminishes, causing quality degradation or repetition in later sections. Claude performs more consistently here, likely due to attention mechanism optimizations such as sliding window attention. While GPT-5.1 also supports a large context window, its single-output token limit appears to be more conservative.
In a test generating a 1,000-word WeChat public account article, Claude's word count was closer to the target with an accessible writing style. GPT-5.1 leaned more technical — suitable for developers but with a higher barrier for general audiences.
Classical Chinese Poetry: Claude Captures Better Imagery
When asked to compose a Song Dynasty ci poem in the "Wang Hai Chao" (望海潮) meter about the transition from autumn to winter, Claude Sonnet 4.5's work was praised as "near perfect" — "霜染曾临,风吹落叶,西窗又见秋蝉" (Frost once visited, wind blows fallen leaves, autumn cicadas seen again by the western window) — with classic imagery and strict adherence to tonal patterns.
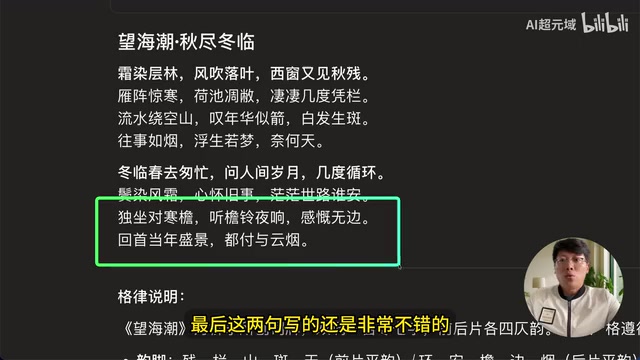
"Wang Hai Chao" is a ci meter created by the Northern Song poet Liu Yong. It's a long-form slow ci (慢词) totaling 107 characters, divided into upper and lower stanzas, with strict requirements for tonal patterns and rhyme schemes. AI-generated classical poetry faces multiple challenges: first, metrical constraints requiring the model to maintain semantic coherence while following tonal rules; second, imagery selection, where classical poetry demands seasonal consistency, emotional resonance, and cultural connotation in its imagery; and finally, avoiding repetition — while the two stanzas share a symmetric structure, they require varied diction, placing high demands on the model's vocabulary diversity control.
GPT-5.1 also followed the meter but had several issues: using "新黄" (xin huang, typically referring to the tender yellow of spring bamboo shoots) to describe an autumn-winter scene was a mismatch that revealed the model's weakness in cultural-semantic understanding. The upper and lower stanzas contained repeated words, and some lines read awkwardly. Claude's advantage here likely stems from richer classical Chinese literature in its training corpus.
Front-End Coding Tests: Claude Delivers Better Visual Results
SVG Animation Generation
Both models were asked to generate an SVG animation of a cat and dog walking on grass. SVG (Scalable Vector Graphics) is an XML-based 2D vector graphics format that can be rendered directly in browsers with animation support. Unlike raster images, SVG describes graphics through mathematical formulas, enabling lossless scaling. Having AI generate SVG animations tests a model's combined "code + visual understanding" ability — the model must understand the target visual effect and then precisely describe shapes and motion trajectories using SVG elements like path, circle, and animate. These tasks demand extremely high spatial reasoning ability, since the model can't actually "see" the output and relies entirely on mathematical understanding of coordinate systems and geometric relationships.
Results showed that Claude's cat and dog were clearly distinguishable with realistic wing-flapping birds, while GPT-5.1's animals were hard to tell apart as cat or dog.

UI Dashboard and Page Reproduction
In dashboard generation and screenshot reproduction tests, Claude's color schemes, layouts, and reproduction accuracy were noticeably superior to GPT-5.1. GPT-5.1 used a clashing dark black color scheme, resulting in a less polished overall look.
3D Rubik's Cube Game Development
Neither model nailed this comprehensive test — Claude's cube couldn't be scrambled, and GPT-5.1 couldn't even render the cube. A 3D Rubik's Cube involves WebGL rendering, 3D rotation matrix calculations, user interaction event handling, and other complex technology stacks working in concert — making it a ceiling-level challenge for current AI code generation.
Bubble Sort Visualization Animation
Both models were asked to create a duck-themed bubble sort animation. Both successfully implemented the core functionality. Claude's ducks were drawn slightly too large but sorted correctly, while GPT-5.1's ducks lacked clear size differentiation.

Browser Automation: GPT-5.1 Shows a Unique Edge
In an Atlas browser test for an Agent automation task (visit a blog → extract an article → rewrite it → publish to X), GPT-5.1 completed the task in 1 minute and 5 seconds, faster than GPT-5.0. This represents a distinctive capability advantage for GPT-5.1.
Atlas is a browser environment designed specifically for AI Agents, enabling large language models to directly manipulate web elements to complete complex task workflows. Browser automation Agents represent one of the cutting-edge directions in AI applications, with core technologies including: computer vision recognition (understanding page layout and element positions), DOM tree parsing (understanding webpage structure), action planning (decomposing complex tasks into atomic operations like clicking, typing, and scrolling), and error recovery (adaptive handling of pop-ups or exceptions). OpenAI invested early in this area — its Operator product and CUA (Computer Use Agent) capabilities have gone through multiple iterations, which explains GPT-5.1's unique advantage in browser automation tasks. While Anthropic has also released a Computer Use feature, it still lags behind in fluidity and speed for actual browser manipulation.
Test Summary: Which One Should You Use?
Based on this multi-dimensional hands-on evaluation, Claude Sonnet 4.5 still outperforms GPT-5.1 in most scenarios, particularly in long-form text generation, literary creation, and front-end UI generation. GPT-5.1 has indeed improved over GPT-5.0, but it hasn't yet closed the gap with Claude.
One thing you might have missed: Claude's knowledge base is updated through January 2025, while GPT-5.1 only goes up to June 2024 — a disadvantage in time-sensitive scenarios. A large language model's "Knowledge Cutoff" refers to the latest date covered by its training data, meaning GPT-5.1 knows nothing about events, technologies, or API documentation released after the second half of 2024. In practice, this gap is significant: when asking about the latest programming framework versions, recent industry developments, or newly released product information, GPT-5.1 may provide outdated or even incorrect answers. While OpenAI can partially compensate through web search functionality, the quality and accuracy of integrated search results still aren't as reliable as built-in model knowledge.
For everyday writing and front-end development, Claude Sonnet 4.5 remains the better choice. For specific tasks like browser automation, GPT-5.1 has its own unique strengths.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.