Kimi K2.6 Open-Source Hands-On: How Strong Is Its Orchestration of 300 Concurrent Agents?

Kimi K2.6 achieves open-source best-in-class Agent orchestration with its trillion-parameter MoE architecture.
Kimi K2.6 uses a trillion-parameter MoE architecture (with only 32B activated parameters) to achieve a core breakthrough in Agent orchestration, simultaneously coordinating 300 sub-Agents for 4,000-step complex tasks and leading GPT-5.4 by nearly 8 points on the Agent Swarm benchmark. It demonstrates strong real-world coding ability, with deployment thresholds as low as 2x RTX 4090s for LoRA fine-tuning. However, it still trails top closed-source models in pure reasoning and visual understanding.
Kimi K2.6 Model Architecture: A Committed Practitioner of the MoE Approach
From an architectural standpoint, K2.6 continues the MoE (Mixture of Experts) approach: total parameters reach the trillion scale, but only 32B parameters are actually activated during inference, with a context window supporting 256K tokens. More importantly, it natively supports image and video inputs, offering multimodal processing capabilities.
About the MoE Architecture: Mixture of Experts (MoE) is an architectural paradigm that splits a large neural network into multiple "expert" sub-networks. During inference, a Gating Network dynamically selects only a few experts to participate in computation based on the input, rather than activating all parameters. This design can be traced back to research by Jacobs et al. in 1991, but it truly exploded in the large language model space around 2022, with Google's Switch Transformer and GLaM as representative examples. K2.6's trillion total parameters with 32B activated parameters means each inference call uses only about 3% of the parameters. The inference cost is comparable to a 32B dense model, but the model's knowledge capacity and generalization ability approach that of a hundred-billion-scale dense model.
This "large parameters, small activation" design philosophy strikes a good balance between inference efficiency and model capability. For teams that need to deploy on limited hardware, 32B activated parameters means inference costs are far lower than a dense model of equivalent capability.
Agent Orchestration: K2.6's True Core Breakthrough
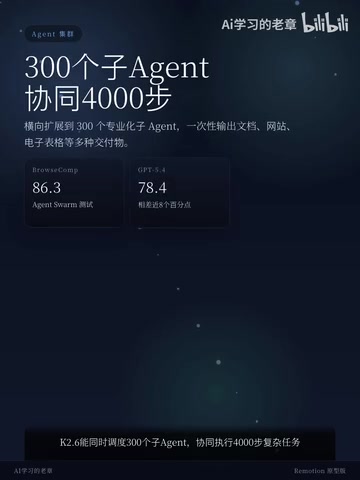
K2.6's most noteworthy capability is Agent orchestration. It can simultaneously coordinate 300 sub-Agents, decomposing a large task into hundreds of parallel subtasks—document processing, web scraping, spreadsheet analysis—all handled in one go.
Understanding Multi-Agent Collaboration: An AI Agent is an AI system capable of perceiving its environment, formulating plans, and autonomously executing a series of actions to achieve objectives, distinguishing it from traditional single-turn Q&A models. In a Multi-Agent Orchestration architecture, a "master Agent" handles task decomposition and scheduling, breaking large tasks into subtasks distributed to multiple "worker Agents" for parallel execution, then aggregating results—highly similar to microservice architecture in software engineering and the MapReduce paradigm in parallel computing. Stably orchestrating 300 concurrent sub-Agents while maintaining task chains of 4,000+ steps places extremely high demands on the model's tool-calling accuracy, context management, error recovery, and state tracking capabilities. This is why multi-Agent orchestration is considered one of the core metrics for evaluating next-generation AI systems.
In the authoritative Rios Comp Agent Swarm test, K2.6 scored 86.3, while GPT-5.4 scored only 78.4—a gap of nearly 8 percentage points. In AI benchmark evaluation systems, this is a considerable margin, indicating that K2.6 has achieved a genuine leading advantage in multi-Agent collaboration scenarios.
Compared to its predecessor K2.5, the improvement is even more striking:
- LCP Mark: Surged from 29.5 to 55.9, nearly doubling
- Apex Agents: Improved by 2.4x
These numbers indicate that Moonshot AI invested heavily in targeted optimization for Agent tool calling, rather than simply scaling up model size.
Coding and Real-World Performance: Not Just Good Benchmark Scores
Coding capability is equally impressive. In the Terminal Bench 2.0 test, K2.6 scored 66.7, slightly edging out both GPT-5.4 and Claude Opus 4.6.

Even more convincing are two real-world case studies:
Case 1: Building an Inference Engine from Scratch
K2.6 used the Zig language to write an inference engine from scratch on a Mac, taking 12 hours and over 4,000 tool calls to optimize throughput from 15 tokens/s to 193 tokens/s—20% faster than LM Studio.
About the Zig Language: Zig is a systems-level programming language initiated by Andrew Kelley in 2016, positioned as a modern replacement for C. It emphasizes explicit memory control, no hidden control flow, compile-time computation, and extreme performance predictability, with no garbage collection and no implicit exceptions. Zig is gaining attention in the AI inference engine space because it can generate highly optimized machine code while offering cleaner syntax and a safer memory model than C++. K2.6's choice to build an inference engine from scratch in Zig was deliberate—completing the entire engineering loop from writing to debugging to performance optimization within 12 hours, boosting throughput from 15 tokens/s to 193 tokens/s, demonstrates that K2.6 not only understands algorithmic logic but also possesses engineering intuition for low-level system optimization. This is a capability boundary that the vast majority of current AI models cannot reach.
Case 2: Refactoring a Financial Matching Engine
K2.6 autonomously refactored an 8-year-old legacy financial matching engine, modifying 4,000 lines of code and directly improving throughput by 185%.

These two cases demonstrate not simple code completion, but end-to-end engineering execution—understanding requirements, decomposing tasks, calling tools, and iterative optimization, all completed autonomously.
Deployment Threshold: Fine-Tuning with Just 2x RTX 4090s, Accessible for Small Teams
There's good news on the deployment front as well. The KTransformers framework supports hybrid CPU-GPU inference—8x L20 GPUs plus an Intel CPU can get it running.
Even more exciting is the LoRA fine-tuning threshold: just 2x RTX 4090s are sufficient, achieving a training throughput of 44.55 tokens/s.
LoRA Fine-Tuning Explained: LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning (PEFT) method proposed by Microsoft Research in 2021. Its core insight is that when fine-tuning large pretrained models, the weight matrix updates exhibit low-rank properties, so the weight changes can be approximated by the product of two small matrices rather than updating all parameters. For example, with a 4096×4096 weight matrix, full fine-tuning requires updating approximately 16.7 million parameters, while LoRA at rank 16 only needs to update about 130,000 parameters—reducing memory usage by over 99%. This enables fine-tuning tasks that previously required dozens of A100s to be accomplished on consumer-grade GPUs (like the RTX 4090), allowing small and medium teams to adapt models on their own data for domain-specific vertical applications.

For small and medium teams, this hardware threshold is entirely acceptable. Two RTX 4090s cost approximately 30,000-40,000 RMB (around $4,000-5,500 USD), and compared to full training schemes that require dozens of A100s, LoRA fine-tuning gives more teams the opportunity to build vertical applications on top of K2.6.
Limitations: An Objective Look at K2.6's Gaps
Of course, K2.6 has clear shortcomings that need to be acknowledged:
- Pure Reasoning Tasks: In pure reasoning scenarios without Agent orchestration, K2.6 still lags behind closed-source models like GPT-5.4 and Gemini
- Visual Understanding: While it supports multimodal input, its visual understanding capability still falls short of top-tier models
- Deployment Cost: Full deployment of trillion-parameter models remains expensive. While hybrid inference solutions lower the barrier, computational requirements are still non-trivial
- License Terms: K2.6 uses a Modified MIT License; commercial users need to carefully review the restrictions in the license terms
About the Modified MIT License: The MIT License is one of the most permissive licenses in the open-source world, allowing commercial use, modification, and distribution, with the only requirement being to retain the copyright notice. However, "Modified MIT License" means additional restrictions are appended to the standard MIT terms, with specifics varying by project. Enterprise users should pay close attention before commercial use: whether there are user scale limitations, whether certain uses are prohibited (e.g., military, surveillance), whether attribution or open-sourcing of derivative model weights is required, etc. These terms directly affect enterprise compliance risk assessment and are an essential legal due diligence step before commercial deployment.
Conclusion: Kimi K2.6 Is the Open-Source Benchmark for the Agent Track
Overall, Kimi K2.6's positioning is crystal clear—it doesn't aim to surpass closed-source models across all dimensions, but rather achieves open-source best-in-class in the specific track of Agent orchestration and tool calling. 300 concurrent Agents, 4,000-step complex task execution, and nearly doubled improvements across version iterations all point to one conclusion: If you're building AI Agent-related products, K2.6 is currently the most worthy open-source option to seriously evaluate.
Moonshot AI's strategy of focusing on Agent capabilities rather than pursuing across-the-board superiority is pragmatic and smart given the current competitive landscape between open-source and closed-source models. After all, for most real-world application scenarios, "getting things done" matters more than "being smarter."
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.