Llama 3.3 70B In-Depth Review: Testing the Strongest Open-Source LLM with 13 Questions
Llama 3.3 70B In-Depth Review: Testing…
Meta's Llama 3.3 70B matches 405B-level performance with just 70B parameters, becoming the strongest open-source LLM.
Meta quietly released Llama 3.3 70B, achieving performance comparable to the previous 405-billion-parameter Llama 3.1 405B with only 70 billion parameters. Optimized through SFT and RLHF training, the model passed 12 out of 13 tests covering logic, math, and programming, outperforming the Qwen 2.5 series. Fully open-source and free, with support for local deployment and function calling, it dramatically lowers the barrier to high-quality AI and signals the rapidly closing gap between open-source and closed-source models.
While everyone was focused on OpenAI's consecutive launch events, Meta quietly released the Llama 3.3 70B model. With only 70 billion parameters, this model claims to rival the performance of the previous 405-billion-parameter Llama 3.1 405B. After comprehensive testing with 13 questions covering logical reasoning, mathematical computation, and programming ability, the results are impressive — it may well be the strongest open-source large language model available today.
OpenAI's Launch Disappoints, Meta Seizes the Moment
During the same period as the Llama 3.3 release, OpenAI was conducting its highly anticipated consecutive launch events. However, the reviewer was quite disappointed with OpenAI's showing: the full O1 model released on day one performed unremarkably, and even more unacceptable was the O1 Pro mode — a $200/month subscription fee for what amounts to "a rather mediocre reasoning model." The reviewer stated bluntly: "When DeepSeek R1 and QWQ are both free, who would pay for this?" To make matters worse, the new full O1 version doesn't even have API access available yet.
In contrast, Meta's Llama 3.3 70B is not only fully open-source but also freely available on multiple platforms including Hugging Face and Ollama, and can even be deployed locally. This stark contrast has once again given the open-source community hope.
Open-Source Deployment Ecosystem Background: Hugging Face is currently the world's largest AI model hosting platform, offering model weight downloads, online inference APIs, and dataset sharing services — often called the "GitHub of AI." Ollama is an open-source tool designed specifically for local deployment that uses model quantization (e.g., compressing 32-bit floating-point numbers to 4-bit integers) to enable consumer-grade GPUs or even CPUs to run multi-billion parameter models. Taking Llama 3.3 70B as an example, after 4-bit quantization, the model size is approximately 40GB and can run smoothly on a Mac Studio with 64GB of memory or a single professional GPU with 48GB of VRAM. This local deployment capability holds extremely high value for enterprises and individual users sensitive to data privacy.
Llama 3.3 70B Technical Analysis: The Secret to Punching Above Its Weight
Llama 3.3 70B is essentially a fine-tuned version of the previous Llama 3.1 70B, employing an optimized Transformer architecture and trained through Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) — similar to the training methodology used for Athene Phi 2.
Transformer Architecture and Parameter Scale: Since Google introduced the Transformer architecture in 2017, it has become the foundation of virtually all modern large language models. Its core is the Self-Attention mechanism, which allows the model to attend to all other tokens in the input sequence when processing each word. Parameter scale (e.g., 70B representing 70 billion trainable parameters) generally correlates positively with model capability, but not linearly. Recent research has shown that through higher-quality training data, more optimized training strategies, and more refined post-training alignment, smaller models can completely outperform larger but lower-quality trained models on practical tasks — Llama 3.3 70B is a prime example of this trend.
SFT and RLHF Technical Principles: Supervised Fine-Tuning (SFT) refers to secondary training on a pre-trained large model using high-quality labeled datasets to make model behavior better align with specific task requirements. Reinforcement Learning from Human Feedback (RLHF) goes further: by collecting human preference ratings on model outputs, a "reward model" is trained, and then reinforcement learning algorithms (such as PPO) optimize the main model to produce outputs more aligned with human expectations. This technical combination was first systematically described by OpenAI in the InstructGPT paper and is the core technical foundation enabling ChatGPT's natural conversational abilities. The quality of the post-training phase often determines a model's practical usability more than pre-training parameter scale.
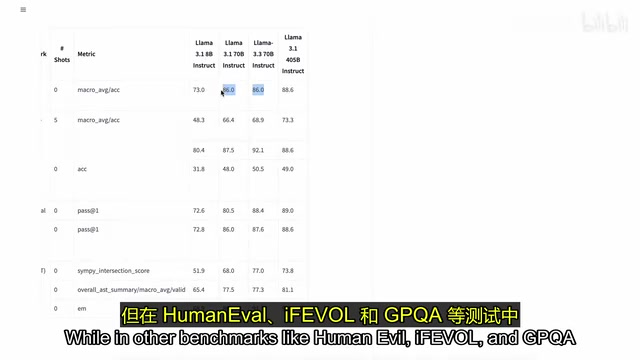
Looking at benchmarks, Llama 3.3's improvement on MMLU isn't particularly dramatic, but it demonstrates significant improvements on HumanEval, iFEVOL, and GPQA benchmarks.
Key Benchmark Explanations: The LLM evaluation field has multiple standardized benchmarks, each with different focuses: MMLU (Massive Multitask Language Understanding) covers multiple-choice questions across 57 subjects, testing a model's broad knowledge base; HumanEval is a code generation benchmark designed by OpenAI containing 164 programming problems, judged by whether code passes unit tests; GPQA (Graduate-Level Google-Proof Q&A) focuses on PhD-level scientific reasoning questions that even domain experts would struggle to answer through web searches, serving as a high-difficulty benchmark for measuring deep reasoning ability. iFEVOL (Instruction Following Evaluation) specifically tests a model's ability to follow complex instructions. Using these benchmarks in combination provides a relatively comprehensive multi-dimensional evaluation of model capabilities.
Additionally, the model supports Function Calling, which is crucial for building AI Agents and tool chain integration.
Function Calling and AI Agents: Function Calling refers to a large language model's ability to recognize user intent and output parameters needed to call external tools or APIs in a structured format (typically JSON), rather than merely generating natural language text. This capability was first systematically introduced by OpenAI in GPT-3.5/4 and is key infrastructure for building AI Agents. An AI Agent is an AI system capable of autonomous planning, tool invocation, and multi-step task execution — such as automatically searching the web, executing code, or querying databases. Supporting Function Calling means Llama 3.3 70B can seamlessly integrate into mainstream Agent frameworks like LangChain and LlamaIndex, significantly expanding its application scenarios in production environments.
You might not have noticed, but Meta didn't write a dedicated blog post for this release — they merely linked to the Hugging Face page on Twitter. This low-key release approach creates an interesting contrast with the model's powerful performance. The model is now available on platforms including Together AI, Hyperbolic, and GLHF, where users can try it for free.
Comprehensive 13-Question Test: Logic, Math, and Programming Verified
The reviewer designed 13 test questions covering multiple dimensions for a systematic evaluation of Llama 3.3 70B. Here's the detailed performance across each category:
Logical Reasoning and Language Understanding Tests
Question 1: Country Name Reasoning — Name a country ending in "LIA" and its capital. The model answered correctly. Pass.
Question 2: Phonetic Rhyming Reasoning — "What number rhymes with a word describing a tall plant?" The answer should be 3 (three rhymes with tree). The model answered correctly. Pass.
Question 3: Scenario Logic Reasoning — Given activity descriptions for five people A through E, determine what C is doing. The model deduced that C is playing table tennis with E, a reasonable inference. Pass.
Question 4: Complex Vocabulary Constraints — Find an 11-letter Latin-origin English adjective satisfying multiple conditions. The model failed to answer correctly — this was the only failure.
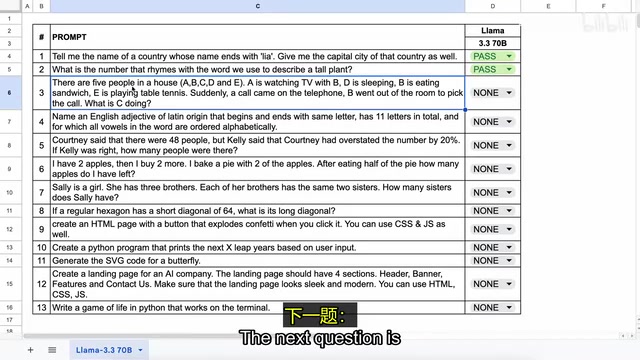
Mathematical Computation Tests
Question 5: Percentage Calculation — Courtney says there are 48 people, Kelly says Courtney over-reported by 20%. How many people are there actually? The model correctly calculated 40.
Question 6: Word Problem Reasoning — A multi-step problem involving buying, baking with, and eating apples. The model correctly answered 2 remaining apples.
Question 7: Sibling Relationship Reasoning — Kelly has three brothers, each brother has the same two sisters. How many sisters does Sally have? The model correctly answered 1.
Question 8: Geometry Calculation — A regular hexagon has a short diagonal of 64; find the long diagonal. The model correctly gave the answer of 73.9.
Programming and Code Generation Tests
Programming tests were where Llama 3.3 truly shined, passing all 5 programming questions:
- HTML Confetti Explosion Effect: Created a webpage with a button-triggered confetti animation that worked well
- Python Leap Year Detection: Correctly determined leap years based on user input
- SVG Butterfly Generation: The generated SVG code actually rendered a butterfly shape
- AI Company Landing Page: A modern page with Header, Banner, Features, and Contact Us sections with excellent visual design
- Terminal Game of Life: A Python implementation of Conway's Game of Life that ran correctly in the terminal
Conway's Game of Life Background: Conway's Game of Life is a cellular automaton designed by British mathematician John Horton Conway in 1970 and is a classic algorithm problem in computer science. Its rules are extremely simple: in a two-dimensional grid, each cell determines whether it survives to the next generation based on the state of its 8 neighbors — living cells die if they have too few or too many neighbors, and dead cells come alive if they have exactly 3 living neighbors. Despite its simple rules, the Game of Life can produce extremely complex emergent behavior and has even been proven to be Turing complete. In AI programming ability tests, the Game of Life is a classic problem because it requires the model to correctly understand 2D array operations, boundary condition handling, and terminal rendering logic, effectively testing the overall quality of code generation.
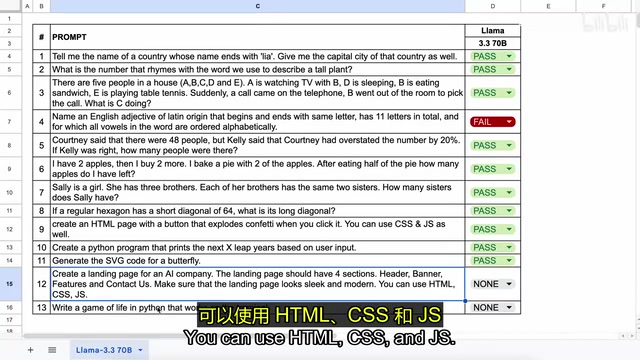
Final score: 12 out of 13 questions passed, failing only on the complex vocabulary constraint question.
Horizontal Comparison: Llama 3.3 vs Qwen 2.5 vs GPT-4O
The reviewer explicitly stated that Llama 3.3 70B is "far superior to" the previous Llama 3.1 70B, and even surpasses the Qwen 2.5 series in personal usage experience. They believe post-training is the key factor — the Athene team previously achieved better results with similar post-training on Qwen models, and this time Meta did it themselves, naturally producing even better results.
The reviewer also made a bold prediction: if Meta applies the same fine-tuning optimization to the 405B version, its performance could surpass GPT-4O and approach Claude's level. This means the gap between open-source and closed-source models is narrowing at an unprecedented pace.
Llama 3.3's Far-Reaching Impact on the Open-Source AI Ecosystem
From a broader perspective, the release of Llama 3.3 70B carries multiple significances:
Dramatically Reduced Inference Costs: The 70B parameter count means far lower inference costs and hardware requirements than 405B, while delivering comparable performance. This enables more developers and SMEs to deploy high-quality AI models. In cloud inference scenarios, the per-inference cost of a 70B model is typically about one-fifth that of a 405B model — highly significant for high-concurrency production environments.
Lower Local Deployment Barriers: Through tools like Ollama, users can run this model on consumer-grade hardware, making data privacy and offline usage no longer a luxury. The maturation of quantization technology makes running 70B-class models on ordinary PCs possible, further breaking down hardware barriers to AI capabilities.
Reshaping the Open-Source vs Closed-Source Landscape: When a free, open-source 70B model can match or even surpass closed-source services costing hundreds of dollars on most tasks, the sustainability of business models deserves reconsideration. The rapid iteration pace of open-source models — enabled by contributions from the global developer community — is creating an innovation speed advantage that closed-source commercial models find difficult to match.
The emergence of Llama 3.3 70B marks a new phase for open-source large language models. As the reviewer stated: "Qwen's leading position has been shaken, and Llama has truly returned to the core of competition." For the entire AI community, this is undoubtedly a moment worth celebrating — true competition drives true progress.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.