NVIDIA Halos Explained: Full-Stack Functional Safety System Architecture for Physical AI Robots
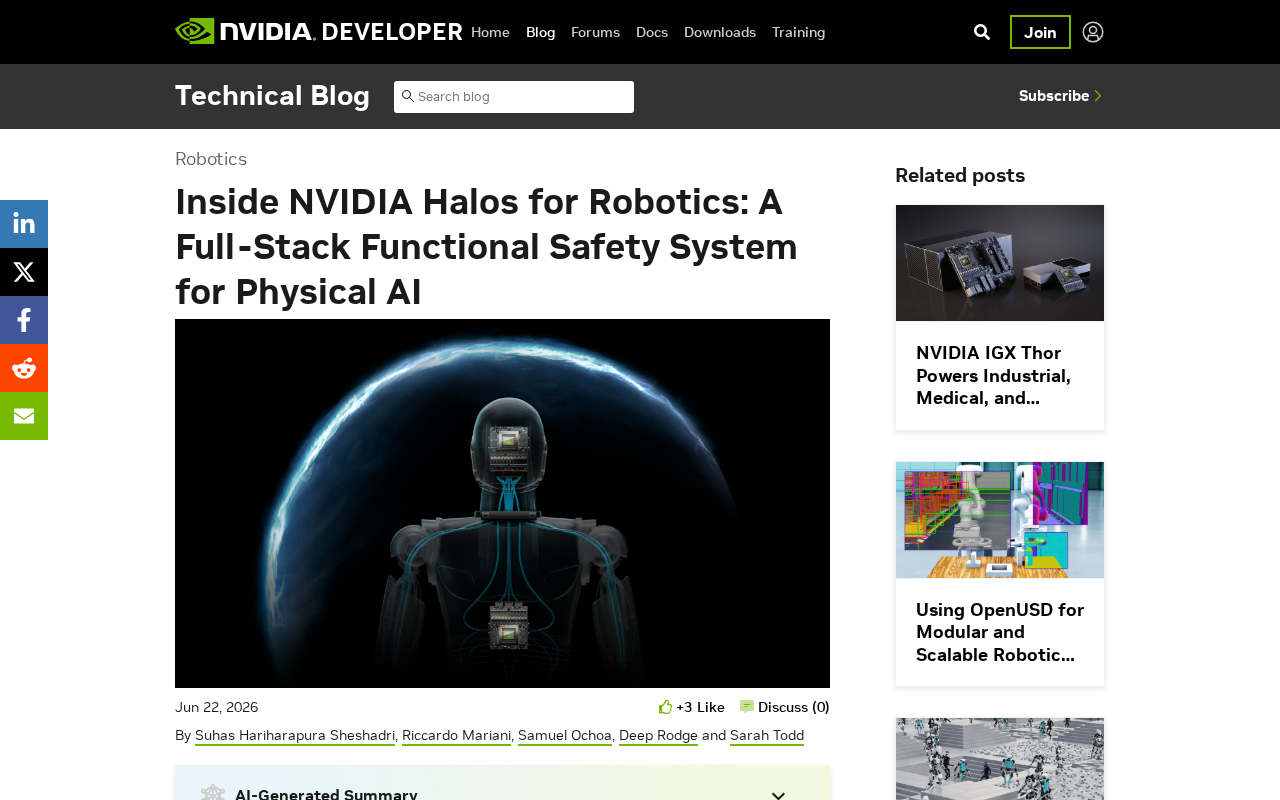
NVIDIA Halos provides a full-stack functional safety system that wraps AI uncertainty in deterministic safety envelopes for robots.
NVIDIA Halos for Robotics is a full-stack functional safety system designed to enable safe deployment of physical AI robots. It combines hardware-level redundant computing with safety processors, a software layer featuring safety runtime, behavior monitors, and safe state managers, plus a complete certification toolchain. Rather than making AI models themselves certifiable, Halos builds an independent safety envelope around AI behavior, leveraging NVIDIA's autonomous driving safety expertise to address the fundamental tension between probabilistic AI and deterministic safety standards.
Physical AI—autonomous robots working alongside humans in factories, warehouses, hospitals, and homes—is arriving faster than expected. However, as robots move from controlled environments into the open world, safety becomes the biggest bottleneck. NVIDIA's Halos for Robotics was created precisely to address this core challenge as a full-stack functional safety system.
The Safety Dilemma of the Physical AI Era
Traditional robot safety solutions are built on deterministic rules: preset boundaries, fixed paths, and emergency stop buttons. These methods work well on enclosed industrial production lines, but they fall short when facing the new paradigm of physical AI—deep learning-based perception, large model-driven decision-making, and autonomous navigation in complex environments.
The core contradiction lies in this: AI model behavior is inherently probabilistic, while functional safety standards (such as ISO 13849, IEC 61508) demand deterministic guarantees. How can we provide verifiable, certifiable safety assurance while preserving AI's flexibility? This is precisely the question NVIDIA Halos aims to answer.
To understand the depth of this contradiction, one must grasp the underlying logic of these safety standards. ISO 13849 focuses on safety-related parts of control systems in mechanical safety, defining five performance levels from PLa to PLe. IEC 61508 is a generic standard for electrical/electronic/programmable electronic safety-related systems, introducing a tiered system of SIL (Safety Integrity Levels) 1-4. The core assumption of these standards is that system behavior is predictable and enumerable—every possible failure mode can be identified and assigned corresponding safety measures. However, the decision-making process of deep learning models is essentially a high-dimensional nonlinear mapping whose behavioral space is virtually inexhaustible, making traditional Failure Mode and Effects Analysis (FMEA) methods difficult to apply directly. It is precisely this fundamental paradigm conflict that gave rise to new safety architectures like Halos.
NVIDIA Halos Full-Stack Architecture Design
Hardware Layer: Safety-Rated Redundant Computing Platform
NVIDIA Halos is not merely a software solution—it builds the safety system starting from the chip level. Based on NVIDIA's GPUs and dedicated safety processors, Halos implements a redundant computing architecture at the hardware level. This means that even if the primary computing unit fails, the safety monitoring module can still operate independently, ensuring the robot enters a safe state.
Redundant computing architectures have a long history in safety-critical systems. The most classic form is Triple Modular Redundancy (TMR), which masks single-point failures through majority voting among three independent computing units. The heterogeneous redundancy NVIDIA employs in Halos is more sophisticated: the primary computing channel (GPU) handles high-performance AI inference, while an independent safety processor (typically based on lockstep CPU architecture) runs deterministic safety monitoring logic. The two monitor each other through hardware-level watchdog mechanisms. Lockstep CPUs refer to two identical processor cores executing the same instructions, where any inconsistency in computation results immediately triggers fault detection. This architecture can achieve extremely high diagnostic coverage (typically >99%), meeting the most stringent safety integrity level requirements.
This design philosophy draws from mature experience in the autonomous driving domain—NVIDIA's functional safety certification capabilities accumulated on the DRIVE platform are now migrating to the broader robotics field. Since its launch in 2015, the NVIDIA DRIVE platform has undergone multiple generations of evolution, with the DRIVE AGX Orin platform achieving ISO 26262 ASIL-D certification—the highest level in automotive functional safety standards, requiring system random hardware failure probability below 10^-8/hour. To obtain this certification, NVIDIA invested hundreds of person-years of engineering effort, including complete safety lifecycle management, systematic fault analysis, and verification testing covering billions of fault scenarios. These accumulated safety design patterns, verification methodologies, and certification experience form the solid technical foundation for Halos's migration to the general robotics domain.
Software Layer: Safety Runtime and Behavior Monitoring Framework
The Halos software stack contains several key components:
- Safety Runtime: Provides deterministic execution guarantees for AI inference, ensuring critical safety tasks complete within strict time constraints
- Behavior Monitor: Monitors AI model outputs in real-time, detects anomalous decisions, and triggers safety interventions when necessary
- Safe State Manager: Defines and manages the robot's degradation strategies under various failure scenarios
The elegance of this architecture lies in the fact that it doesn't attempt to make the AI model itself "safety-certifiable" (which is nearly impossible under current technological conditions). Instead, it builds an independent Safety Envelope outside the AI model, using deterministic safety logic to constrain probabilistic AI behavior.
The concept of a safety envelope originates from the flight envelope in aerospace, which defines the safe operating boundaries of an aircraft across various parameter combinations. In robotics, the safety envelope defines the allowable operating region for a robot in a multi-dimensional parameter space including speed, torque, acceleration, and distance from humans. The core advantage of this approach is "separation of concerns"—the AI system is responsible for finding optimal behavior within the envelope, while the safety system only needs to ensure behavior doesn't cross envelope boundaries. This is similar to a sandbox mechanism in operating systems: you don't need to prove that the program inside the sandbox is safe; you only need to ensure the sandbox itself is unbreakable. This architectural design allows AI models to iterate and upgrade rapidly, while safety certification only needs to target the envelope layer, significantly reducing certification complexity and cycle time.
Toolchain: A Complete Closed Loop from Development to Certification
Halos also provides a supporting development toolchain, including safety analysis tools, fault injection testing frameworks, and documentation generation tools compliant with functional safety standards. This significantly lowers the barrier and cost for robot manufacturers to obtain safety certification.
Why Is Halos Launching Now?
The Explosive Growth of Humanoid Robots
The humanoid robot sector is experiencing an unprecedented investment boom. From Figure and Agility to China's UBTECH and Unitree Robotics, numerous companies are pushing humanoid robots toward commercialization. But the prerequisite for commercialization is safety certification—no factory is willing to deploy a humanoid robot that cannot pass safety review.
Safety certification for humanoid robots faces unique challenges. Unlike industrial robotic arms fixed on production lines, humanoid robots have high degrees of freedom (typically 30-50 joints), move in unstructured environments, and share workspace with humans. Currently applicable standards mainly include ISO/TS 15066 (collaborative robot safety) and the in-development IEEE 2851 (robot safety design standard), but these standards have not yet fully covered AI-driven autonomous decision-making scenarios. Regulatory bodies in various countries (such as the EU's AI Act and the US NIST AI Risk Management Framework) are also accelerating the development of relevant regulations. During this standards vacuum, the safety framework provided by Halos could become a de facto standard, influencing the direction of future formal standards.
The launch of Halos fills this critical gap perfectly, providing standardized safety infrastructure for the entire industry.
Technology Migration from Autonomous Driving to General Robotics
NVIDIA has been deeply invested in autonomous driving for years, and the DRIVE platform has obtained multiple functional safety certifications. Halos is essentially generalizing these proven safety technologies and methodologies to broader robotic application scenarios. This technology reuse strategy both reduces R&D risk and accelerates product maturity.
Industry Impact and Future Outlook
The release of Halos marks a further deepening of NVIDIA's positioning in the physical AI space, evolving from "computing power supplier" to "full-stack platform provider." By controlling the critical element of safety, NVIDIA is poised to occupy a more central position in the robotics industry chain.
For robot developers, Halos's value lies in transforming functional safety from "a difficult problem you need to build from scratch" into "an out-of-the-box platform capability." This is similar to how AWS abstracted infrastructure in the cloud computing era—developers can focus on upper-layer application innovation while entrusting safety infrastructure to the platform.
However, attention must also be paid to the potential ecosystem lock-in risk. When the safety system is deeply bound to NVIDIA hardware, robot manufacturers' technology choices may become constrained. In the chip domain, NVIDIA has already established a powerful developer lock-in effect through the CUDA ecosystem—over 4 million CUDA developers worldwide and thousands of optimized libraries constitute technical assets that are difficult to migrate. Halos extends this lock-in from the computing layer to the safety layer: once a robot manufacturer completes safety certification based on Halos, switching to another platform means undergoing a recertification process that takes years and costs millions of dollars. This "certification lock-in" is more robust than mere technical lock-in because safety certification involves deep interaction with regulatory bodies, making migration costs extremely high. How to strike a balance between standardization and openness will be a challenge Halos must face in its long-term development.
Conclusion
For large-scale deployment of physical AI, safety is an unavoidable threshold. NVIDIA Halos systematically addresses this problem in a full-stack manner—from chips to software to toolchains. It is not just a technology product but represents a pragmatic approach: rather than making AI itself perfectly safe, it uses engineered safety architecture to wrap and constrain AI's uncertainty. This is perhaps the most viable path for physical AI to achieve large-scale deployment.
Related articles

Sakana AI Releases Fugu Ultra: How Model Orchestration Achieves Frontier AI Performance
Sakana AI releases Fugu Ultra, achieving frontier AI performance through autonomous model orchestration. Deep dive into its technology, strategic implications, and impact on global AI competition.

Illusion Code In-Depth Review: 34+ Tools and 7 Agents Working in Harmony as an AI Coding Assistant
In-depth review of Illusion Code CLI AI coding assistant: 34+ core tools, 7 specialized Agents, three permission modes, and Chinese ecosystem support, compared with Claude Code, Codex, and OpenCode.
AI Scientist: A Deep Dive into Sakana AI's Automated Research Framework
Deep dive into Sakana AI's open-source AI Scientist project: how LLMs automate the full research pipeline from hypothesis generation and experiment execution to paper writing, including architecture, workflow, and limitations.