O3 vs Gemini 2.5 Pro vs Claude 3.7: Real-World AI Coding Ability Comparison
O3 vs Gemini 2.5 Pro vs Claude 3.7: Re…
O3, Gemini 2.5 Pro, and Claude 3.7 coding comparison — each excels differently with no absolute winner.
Through four progressively difficult tasks — snake battle, RL training pipeline, solar system simulator, and soccer game — this test compares the coding abilities of top AI models including O3, Gemini 2.5 Pro, and Claude 3.7. Results show each model has distinct strengths: O3 delivers stable and reliable code, Claude 3.7 perfectly implements RL tasks in one shot, Gemini 2.5 Pro excels at complex system design, while Mini-series models show clear limitations on complex tasks.
Testing Background and Methodology
With the successive releases of top-tier AI models like OpenAI O3, Gemini 2.5 Pro, and Claude 3.7, a core question has emerged: Who is the best coding AI? This test conducted a comprehensive comparison of these models through multiple Python game development tasks of increasing difficulty.
The models tested include: O3, O4 Mini, O3 Mini, Gemini 2.5 Pro, and Claude 3.7. All models received identical prompts and were compared under the same conditions. Tasks progressed from simple autonomous game development, to reinforcement learning training pipelines, a solar system simulator, and finally a complex soccer game system.
Model Architecture Background: The technical approaches of today's top AI coding models differ significantly. OpenAI's O-series models (O3, O4 Mini) employ a "Chain-of-Thought Reasoning" mechanism, performing multi-step internal reasoning before generating code, giving them a natural advantage in logical rigor. Gemini 2.5 Pro is built on Google DeepMind's multimodal architecture with an ultra-long context window of up to 1 million tokens, capable of handling extremely complex code structures in a single conversation. Claude 3.7 comes from Anthropic, whose training process emphasizes "Constitutional AI" principles, excelling in code safety and one-shot task completion rates. These three companies represent the most cutting-edge technical approaches in AI today, and the differences in their model capabilities reflect distinct training philosophies and architectural choices.
Round 1: Autonomous Snake Battle Game
Task Requirements
The first task appears simple but is deceptively challenging: create a fully autonomous snake game in a single Python script where two snakes compete against each other, with a complete scoring system — +1 point per second survived, +10 for eating an apple, and +50 for eating the opponent snake.
Model Performance
Claude 3.7 went first, with both snakes running perfectly, correct scoring system, and excellent graphics. The only minor flaw was slightly hard-to-read blue text, but it ultimately crashed due to a type error.
Gemini 2.5 Pro performed outstandingly — perfectly following instructions, displaying per-round scores and cumulative scores, with a brief summary at the end. Overall stability was excellent.
O4 Mini had a nice design style, but had issues with snake-to-snake collision handling — the algorithm didn't account for collision detection between snakes.
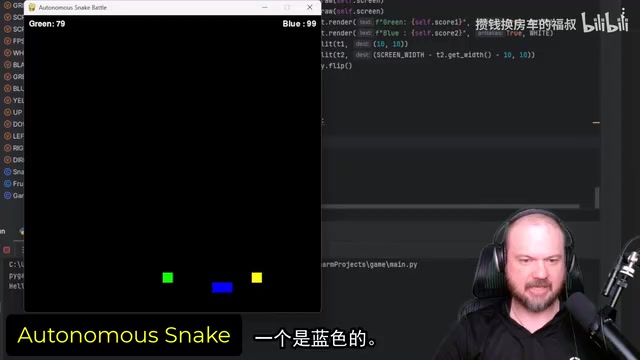
O3 showcased the advantages of a full-size model — it wrote snake-to-snake collision logic into the code, snakes rarely collided accidentally, and it ran without any crashes. The tester commented: "O3 and Gemini 2.5 Pro scored roughly the same, these two probably performed the best."
Round 2: Reinforcement Learning Training Pipeline
Difficulty Escalation
The second round significantly increased complexity: models were asked to create a script supporting multiple run modes — normal game mode, reinforcement learning training mode using PyTorch, and an evaluation mode using the trained model for battles. An obstacle system that adds two obstacles per second was also required.
Reinforcement Learning and PyTorch Technical Explanation: Reinforcement Learning (RL) is one of the core paradigms of machine learning. Its fundamental idea is to have an agent continuously optimize its decision-making strategy through interaction with an environment, guided by reward signals. In the snake scenario, the AI snake acts as the agent, game state (snake positions, food positions, obstacles) serves as the observation space, movement directions as the action space, and score changes as reward signals. PyTorch is a deep learning framework developed by Facebook, known for its dynamic computation graphs and Pythonic API, and is the most mainstream RL implementation tool in both academia and industry. A complete RL training pipeline typically includes: environment wrapping (Gym interface), neural network policy network, experience replay buffer, and optimization algorithms like DQN or PPO. Correctly implementing this entire system in one shot requires the model to have deep understanding of RL engineering practices, not just conceptual knowledge.
Key Results
O4 Mini and O3 Mini both failed to run the script successfully, encountering basic errors like undefined default values.
O3 also ran into problems and couldn't work properly after multiple attempts.
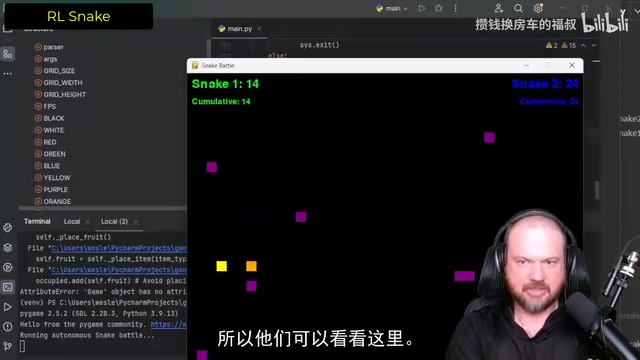
Claude 3.7 perfectly solved all problems in a single attempt. It successfully implemented:
- Four different run modes (normal game, training, snake 1 with AI, snake 2 with AI)
- Properly functioning obstacle system
- Complete reinforcement learning training pipeline
- After training for 500 episodes, the AI snake significantly outperformed the scripted snake
The test data was impressive: the trained AI snake scored over 3,000 points while the regular scripted snake only managed 370. After switching roles, the AI snake still won overwhelmingly (80:30), proving the neural network training was genuinely effective.
Claude 3.7 was the clear winner of this round, perfectly implementing all features in a single attempt.
Round 3: Solar System Simulator
Task Description
Create a solar system simulator that allows players to launch probes from outside the galaxy, utilizing planetary gravity for slingshot effects to hit two fixed targets.
Physics of Gravitational Slingshot: Gravitational slingshot, also known as "gravity assist" or "planetary flyby," is an orbital mechanics technique widely used in real space missions. Its physical essence is that when a probe flies past a planet, it leverages the planet's gravitational field and orbital momentum to change speed and direction without consuming fuel — NASA's Voyager probes used this principle to explore the outer planets of the solar system. At the code implementation level, simulating gravitational slingshot requires correctly implementing the universal gravitation formula (F=GMm/r²) and using numerical integration methods (such as fourth-order Runge-Kutta or simplified Euler integration) to update the probe's velocity and position vectors frame by frame. This places high demands on the AI model's physics modeling capabilities — requiring not just formula understanding but also correct handling of engineering details like coordinate system transformations and time step selection.
Model Comparison
O3 performed well, successfully implementing the basic gravitational slingshot mechanism where the probe's trajectory was influenced by planetary gravity. While not perfect, the core gameplay was viable.
Gemini 2.5 Pro created a visually large simulator, but had interaction logic issues — the click-to-launch function didn't work properly and required multiple debugging attempts.
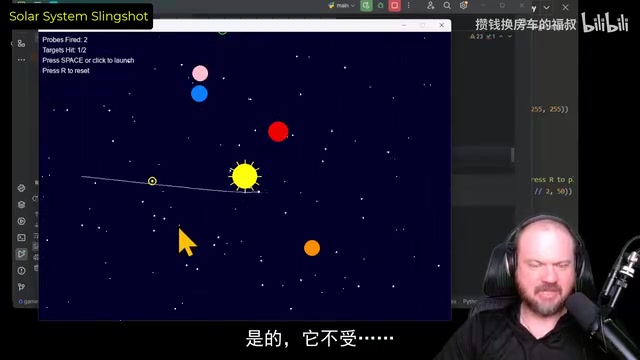
Claude 3.7 had nice graphics, but the probe wasn't affected by any gravitational fields — the core physics simulation mechanism was missing. This issue reveals a noteworthy phenomenon: even top-tier models can produce "code that runs but has incorrect physics logic" in scenarios requiring precise numerical integration and physics formulas working together.
O3 Mini crashed multiple times.
O3 performed best in this round — while not perfect, it correctly implemented the most core features.
Round 4: Autonomous Soccer Game System
The Ultimate Challenge
The final task was to create a three-on-three autonomous soccer game including: player statistics, experience point system, level progression, tackling mechanics, snowball effects, goal animations (screen shake), scoreboard, and other complex systems.
Final Verdict
O3 implemented basic functionality including the level system and experience points, but players clustered together making them hard to distinguish, and the starting positions for red and blue teams were unfair.
Gemini 2.5 Pro earned an extra star rating — successfully implementing attribute systems for strength, speed, and accuracy, with player attributes improving upon leveling up, and game speed increasing over time. The tester commented: "Absolutely deserves an extra star, amazing."
Claude 3.7 crashed after running for a while due to a ball-distance-related bug, but ran smoothly before the crash.
Comprehensive Evaluation and Final Conclusions
| Model | Snake | RL | Solar System | Soccer | Overall |
|---|---|---|---|---|---|
| O3 | ★★★★★ | ★★☆ | ★★★★ | ★★★ | Excellent |
| Gemini 2.5 Pro | ★★★★★ | ★★★ | ★★★ | ★★★★★+ | Excellent |
| Claude 3.7 | ★★★★ | ★★★★★ | ★★★ | ★★★★ | Excellent |
| O4 Mini | ★★★★ | ★☆ | - | - | Average |
| O3 Mini | ★★★★ | ★☆ | ★☆ | - | Average |
Key Findings
-
No absolute winner: Each model has strengths and weaknesses across different tasks. O3 excels in code stability and collision logic, Gemini impresses in complex system design, and Claude is unmatched in one-shot completion of complex tasks.
-
Claude 3.7 dominated the reinforcement learning task, perfectly implementing a complete system with PyTorch training pipeline in a single attempt — particularly important for developers needing machine learning integration.
-
Gemini 2.5 Pro is hard to beat in game mechanics design, especially excelling in tasks requiring complex attribute systems and dynamic balancing.
-
Mini models show a clear gap: O4 Mini and O3 Mini frequently failed on complex tasks, proving that model scale remains crucial for programming tasks. This phenomenon aligns closely with "Scaling Laws" in AI — first systematically proposed by OpenAI in 2020, this theory shows that increasing model parameters improves performance in predictable ways, especially in complex programming tasks requiring long-range dependency reasoning, multi-module coordination, and error self-checking, where compact architectures often cannot sustain sufficient reasoning capacity to handle engineering-level challenges.
Selection Recommendations
- Need stable, reliable code output: Choose O3
- Involving machine learning and training pipelines: Choose Claude 3.7
- Complex game systems and interaction design: Choose Gemini 2.5 Pro
- Simple scripts and rapid prototyping: Mini models can handle it
This AI coding showdown has no absolute winner, but each model demonstrated its unique strengths. Developers should choose the most suitable AI coding assistant based on their specific project requirements.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.