OpenAI Codex Deep Dive: How Does the Async AI Coding Agent Actually Perform?
OpenAI Codex Deep Dive: How Does the A…
OpenAI Codex cloud coding agent tested: completes 30% of Kanban tasks, signaling a programming paradigm shift.
OpenAI's Codex is a cloud-based async AI coding agent that processes multiple tasks in parallel and automatically generates Pull Requests. An AI entrepreneur tested it on a production codebase serving 50,000 users and found Codex accurately locates files, understands component dependencies, and can complete roughly 30% of Kanban tasks. While the percentage seems modest, the zero-risk, high-reward nature makes it extremely valuable. Currently available only to Pro/Team/Enterprise users and still in Research Preview.
Article
OpenAI's latest release, Codex, is positioned as the most powerful AI coding agent to date. Unlike local coding tools such as Cursor and Windsurf, it's an asynchronous software engineering agent running in the cloud—you can dispatch 50 tasks simultaneously, go grab a coffee, and come back to find the code already written. Sounds great in theory, but how does it actually perform? An AI entrepreneur put it through rigorous testing using their production-grade codebase serving 50,000 users.
What Is Codex: A Cloud-Based Async Coding Agent
Codex is OpenAI's cloud-based software engineering agent, currently available as a Research Preview integrated into ChatGPT. Unlike coding tools such as Cursor and Windsurf that run locally, Codex operates entirely in OpenAI's cloud environment, meaning it doesn't consume your local resources—you can even initiate tasks from your phone.
Notably, Codex adopts the Asynchronous Agent paradigm—a fundamental departure from traditional AI coding tools. Traditional tools (like early GitHub Copilot) use a synchronous model: you type, it responds immediately, and you wait for results. An async agent allows users to submit tasks and walk away immediately. The agent independently completes work in the background—reading code, running tests, submitting PRs, and more—then notifies users to review when done. This experience is closer to "hiring a remote engineer" than "using a code completion tool."
Its core capabilities include:
- Parallel GitHub Pull Request drafting: Can handle multiple tasks simultaneously
- Autonomous codebase navigation: Finding bugs, reviewing code, suggesting improvements
- Running lint and tests: Ensuring generated code passes basic validation
- Asynchronous workflow: You dispatch tasks and don't need to wait—it completes work in the background
Codex is powered by a brand-new AI model—Codex One. This is a model specifically fine-tuned by OpenAI for software engineering tasks. Its predecessor was the original Codex released in 2021 (fine-tuned from GPT-3, which served as the underlying engine for GitHub Copilot). The new Codex One is optimized on top of the O3 reasoning model, with enhanced capabilities for codebase navigation, multi-file context understanding, and test execution. Compared to general-purpose reasoning models, the advantage of a specialized engineering model lies not just in marginal accuracy improvements, but in its native understanding of software engineering workflows (Git operations, lint checks, dependency management).
In terms of benchmarks, Codex One slightly outperforms O3 High on SWE-bench. SWE-bench is a software engineering benchmark proposed by Princeton University researchers in 2023, specifically designed to evaluate AI models' ability to solve real GitHub Issues—unlike traditional code completion tests, it requires models to locate bugs in real open-source codebases (such as Django, Flask, NumPy), understand context, and generate patches that pass unit tests. It's widely regarded as the most realistic AI coding evaluation standard for real-world software engineering scenarios. Codex One achieves 75% accuracy on OpenAI's internal software engineering tasks, compared to 70% for O3 High. The numerical improvement isn't massive, but the real breakthrough lies in the paradigm shift in interaction.
Real-World Testing: From Kanban Board to Pull Request
The tester connected their startup Vectl's production-grade codebase (Python backend + Next.js frontend, serving over 50,000 users) to Codex and tested it with real Kanban board tasks.
Task 1: Search Result Sorting Issue
The first real task came from a bug on the Kanban board: search results sometimes appeared to be sorted in reverse, with the most relevant results showing at the bottom instead of the top.
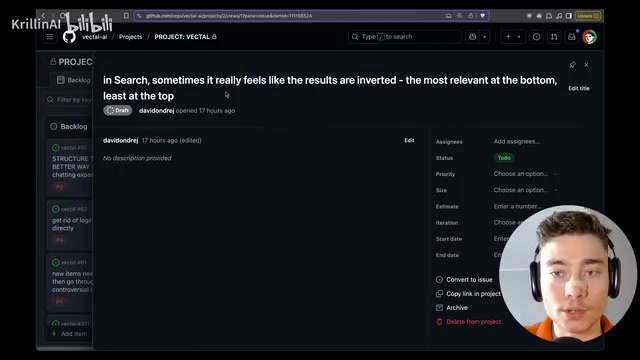
The tester provided a clear prompt: describing the problem (incorrect search result ordering), the location (search functionality), and expected behavior (most relevant results should appear at the top). Codex completed its analysis in 2 minutes and 18 seconds, but the result was somewhat controversial—it assumed a rank field existed in the data, which the tester wasn't sure about.
Interestingly, when the tester provided feedback questioning the existence of the rank field, Codex re-analyzed the codebase and discovered that the SQL search function did indeed return a computed rank field. This demonstrates Codex's contextual understanding and self-correction capability. The task was ultimately pushed as a GitHub Pull Request.
A Pull Request (PR) is a core mechanism for collaborative development in modern software teams, introduced and popularized by GitHub in 2008. The workflow involves developers completing code changes on an independent branch, then submitting a "merge request" to the main branch. Team members review the code (Code Review), discuss, and test it before merging into the main codebase. Codex generating PRs rather than directly modifying code is a crucial design choice—it integrates AI output into a human-supervised workflow, ensuring every line of AI-generated code undergoes human review, effectively reducing the risks of AI coding.
Task 2: Optimizing Reminder Generation Randomness
The second task was improving the prompt for the notes-to-reminders feature—the current system always set reminders to every 7 days, which was too predictable. The tester asked Codex to rewrite the relevant prompt to choose more specific numbers (like every 13 days, every 19 days, every 31 days).
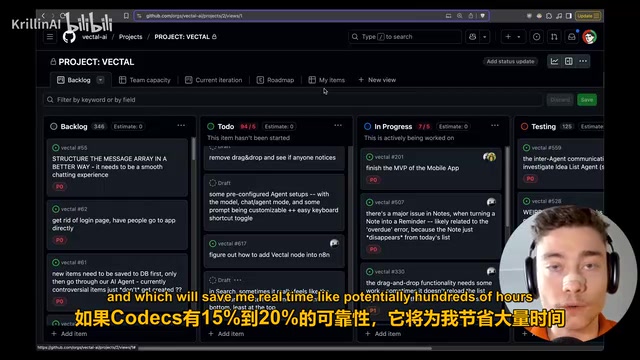
Codex found the correct prompt file (generate_occurrence_pattern.message.md) in about 2.5 minutes and made the modifications as instructed. The tester confirmed the changes were correct and pushed it directly as a PR. While this task wasn't complex, Codex's ability to accurately locate the file and make correct modifications was impressive.
Task 3: Frontend UI Conditional Styling
The third task was changing the input box border color based on chat mode (Agent mode vs. Chat mode). Codex not only modified the UI component file but also simultaneously modified three related dependency files to pass the chatMode parameter, demonstrating its understanding of component dependency relationships.
However, the lint test failed—because the next command was missing in OpenAI's cloud environment. The tester attributed this to an OpenAI environment configuration issue rather than a problem with the code itself.
agents.md: Codex's System Prompt
A key configuration detail is the agents.md file. Similar to Cursor's .cursorrules file, agents.md is Codex's global system prompt, placed in the repository root directory to control the AI agent's behavior.
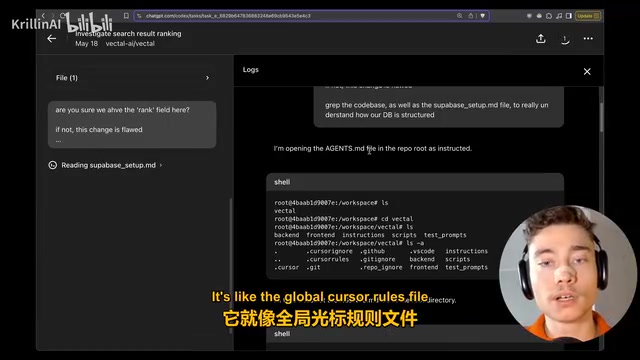
The design philosophy of agents.md originates from "System Prompt" engineering practices. In the working mechanism of large language models, a system prompt is a pre-set instruction set placed before the user conversation begins, defining the AI's behavioral boundaries, output style, and domain constraints. Cursor's .cursorrules, GitHub Copilot's custom instructions, and Codex's agents.md are all productized implementations of this mechanism. Research shows that well-designed system prompts can improve AI output quality by 20-40%, which is why "Prompt Engineer" has become an independent professional skill in the AI era.
The tester copied their carefully optimized 418-line Cursor rules file directly as agents.md—a practice worth emulating. Good system prompts can significantly improve AI agent performance, which is why prompt engineering skills are becoming increasingly important in the AI coding era.
Honest Assessment: 30% Task Completion Rate Is Still Highly Valuable
The tester offered a very pragmatic evaluation: Codex can complete roughly 30% of tasks on the Kanban board. This number might seem low at first glance, but consider it from another angle—if there are 346 to-do items on the board, 30% means over 100 tasks can be completed automatically, potentially saving hundreds of hours of development time.
More importantly, the cost of dispatching tasks is essentially zero. The worst-case scenario is that the code doesn't pass tests or doesn't meet quality standards—then you simply don't merge it. But if it succeeds, it's free productivity. This zero-risk, high-reward characteristic makes Codex an extremely attractive tool.
Current Limitations and Pricing
Several limitations to note:
- Only available to Pro ($200/month), Team, and Enterprise users—not accessible to Free and Plus users
- Money-saving tip: The Team plan only requires inviting one person, at $60/month per person for Codex access
- Environment issues: Package management in the cloud environment isn't robust enough; lint tests frequently fail due to missing dependencies
- Research Preview stage: Many bugs; not suitable for critical production tasks
- Task granularity: Suited for small to medium tasks; cannot handle large-scale refactoring of entire backends
A Shift in the Programming Paradigm
Codex represents not just a new tool, but a fundamental shift in how programming work is done. From "programmers writing code line by line" to "tech leads managing AI agent teams," the developer's role is transforming from executor to decision-maker and reviewer.
The key to this transformation: you no longer need to complete every task yourself. Instead, you need the ability to clearly describe problems (prompt engineering), the ability to judge code quality (Code Review), and architectural design capability (systems thinking). The barrier to coding is lowering, but the demand for engineering thinking is actually increasing.
For entrepreneurs and small teams, Codex may be one of the most noteworthy productivity tools available today. Even if it can only complete 30% of tasks, that means your development speed increases by nearly 50%—and this is just the Research Preview stage.
Key Takeaways
- OpenAI Codex is a cloud-based async AI coding agent that can process multiple programming tasks in parallel, typically completing each in 2-4 minutes
- In real-world testing with a production codebase serving 50,000 users, Codex accurately locates files, understands component dependencies, and is estimated to complete about 30% of Kanban tasks
- The agents.md file serves as Codex's system prompt, similar to Cursor's rules file—strong prompt engineering skills can significantly improve agent performance
- Currently only available to Pro ($200/month), Team, and Enterprise users; the Team plan offers the best value ($60/month/person)
- Codex represents a paradigm shift from "writing code line by line" to "managing AI agent teams," with developers transitioning from executors to decision-makers and reviewers
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.