Running Qwen3.6-27B Locally on Mac: 4 Solutions Benchmarked
Running Qwen3.6-27B Locally on Mac: 4 …
MTP-LX is the best way to run Qwen3.6-27B on Mac, hitting 43.6 tok/s at 4bit quantization.
This article benchmarks four solutions for running Qwen3.6-27B locally on Mac: the official website, Anthros GGUF, Anthros MLX+Diflash, and MTP-LX. Testing shows the MTP-LX 4bit solution leads at 43.6 tok/s—nearly double other options—while maintaining acceptable output quality for coding, writing, and reasoning tasks. It's easy to install and is currently the optimal choice for Mac users, with the only limitation being no image recognition support yet.
Introduction: The Challenge of Running a 27B Model Locally
Since its release last month, Qwen3.6-27B has attracted widespread attention thanks to its flagship positioning and excellent coding capabilities. Its core selling point is challenging the performance of the previous-generation 397B MOE flagship model with only 27B parameters, surpassing it on multiple benchmarks including SWE Bench Verified, SWE Bench Pro, and Terminal Bench 2.0.
What is MOE architecture? Mixture of Experts (MOE) is a sparse activation architecture: the model has a massive number of parameters, but only activates a small subset of "expert" sub-networks during each inference pass. Although a 397B MOE model has enormous total parameters, its actually activated parameters may only be in the tens of billions, making inference costs far lower than a dense model of equivalent size. As a dense model, Qwen3.6-27B challenges the performance of a 397B MOE with its full 27B parameters, demonstrating significant advances in model architecture and training efficiency.
What is SWE-Bench? SWE-Bench (Software Engineering Benchmark) is an authoritative benchmark specifically designed to evaluate LLMs' ability to solve real-world software engineering problems. It extracts tasks from real GitHub Issues, requiring models to read codebases, understand problem descriptions, and generate patches that pass unit tests. SWE-Bench Verified is a human-verified high-quality subset, while SWE-Bench Pro further increases task difficulty. Compared to traditional code completion tests, SWE-Bench is much closer to developers' actual workflows, which is why the industry considers it the gold standard for measuring coding ability.
However, for Mac users, running a 27B model locally presents two major pain points: generally slow speeds and too many options causing decision paralysis. From LM Studio and Ollama to OMLX, Diflash MLX, and MTP-LX, performance varies dramatically across different backends. This article provides hands-on benchmarks comparing 4 solutions on speed and quality to help you find the optimal choice.
Speed Comparison of Four Solutions
Here are the four solutions tested for running Qwen3.6-27B on Mac:
| Solution | Quantization | Generation Speed | Notes |
|---|---|---|---|
| Qwen Official Website | Full precision | Best quality | Requires internet |
| Anthros UD Q5 GGUF | 5bit | ~18 tok/s | Noticeable fan noise |
| Anthros MLX 6bit + Diflash | 6bit | ~22 tok/s | Medium speed |
| MTP-LX | 4bit | ~40+ tok/s | Double the speed |
Understanding Quantization and tok/s Model Quantization is a technique that compresses neural network weights from high-precision floating-point numbers (such as FP32, BF16) to low-bit integer representations. 4bit quantization means each weight is stored using only 4 binary bits, compressing model size by approximately 75% compared to 16bit precision, significantly reducing memory usage and inference latency. Quantization inevitably introduces precision loss, but modern quantization algorithms (such as GPTQ, AWQ, and GGUF's K-quant series) use calibration datasets and error compensation mechanisms to keep quality loss within acceptable bounds.
tok/s (tokens per second) is the core metric for measuring inference speed. For Chinese users, one Chinese character typically corresponds to 1-2 tokens; for English, one word is approximately 1-1.5 tokens. Human reading speed is roughly 5-8 tok/s, so 20+ tok/s already approaches the subjective experience of "real-time streaming output." 40+ tok/s means the model outputs far faster than humans can read, with users experiencing virtually no waiting.
Architectural Differences Between MLX and GGUF MLX is Apple's machine learning framework designed specifically for Apple Silicon chips, fully leveraging the advantages of the M-series chips' Unified Memory Architecture (UMA)—where CPU and GPU share the same memory pool, eliminating the data transfer overhead of traditional GPU inference. GGUF (GPT-Generated Unified Format) is the universal model format for the llama.cpp ecosystem, offering strong cross-platform compatibility but less optimization on Apple Silicon compared to native MLX. This explains why MLX solutions (22 tok/s) are generally faster than GGUF solutions (18 tok/s) in the table, while the deeply optimized MTP-LX pushes performance even further.
The most surprising finding: the 4bit MTP-LX solution achieved 43.6 tok/s, nearly doubling the 6bit MLX + Diflash solution, while output quality remained impressive.
Coding Capability Tests: Cross-Scenario Comparison
3D Scenes and Game Generation
Using the MTP-LX 4bit version, one content creator successfully generated a richly detailed 3D game scene containing buildings, cars, plazas, trees, roads, and billboards—with stunning results.
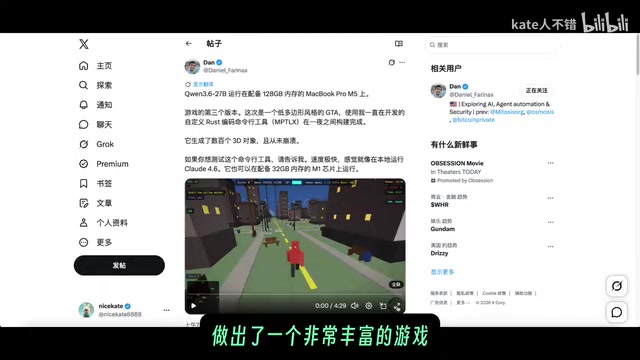
In comparison, the official website version generated a "boatmen pulling a boat" scene where the boat clipped through a mountain with obvious logic issues, and some plants floated in mid-air. The Anthros UD Q5 version produced a noticeably inferior intersection simulation.
Gift Wrapping Smart Assistant
This test scenario effectively highlights the differences between solutions:
- Official website version: Nice styling with bow design, but the 3D preview had a cube/rectangular prism confusion bug, and wrapping paper pattern areas showed blank spaces
- Anthros Q5 version: Decent 3D preview, but missing functionality after switching shapes; the wrapping step guide was a highlight
- MTP-LX 4bit version: Most polished UI design, clicking different gifts shows corresponding previews on the right, occasion switching works properly, with only slight separation between gift box and wrapping paper
Warehouse Sorting Simulation System
All versions had various issues with the robotic arm simulation task—object clipping, rough mechanical arm details, and unreasonable box placement. But considering this is just a 4bit quantized 27B model generating these results locally at 40 tok/s, it already exceeds expectations.
CSS Art Generation
The MTP-LX version excelled at generating "Sheep Barbershop" CSS art: a duck with a bow on its head, a barber giving a sheep a haircut, a checkered cape, a deep red sofa—multiple objects with precise positioning and fine details. The only shortcoming was the window overlapping with the door.

MTP-LX Installation and Configuration Guide
The MTP-LX installation process is quite straightforward:
- Installation: Complete the base installation via
brew install - Initialization: Run
mtplx startto enter the interactive command interface - Model selection: For first-time use, the default speed model (4bit version) is recommended; for higher quality, download the author's published high-quality version
- Mode selection: Use the default mode
- Access methods: Supports Web UI, OpenCode, and various other chat interfaces

Once configured, MTP-LX is automatically recognized by Open WebUI with no additional setup required. Regarding parameter tuning, Qwen officially recommends temperature 0.6 for coding tasks and temperature 1.0 for general tasks.
What Temperature Means Temperature is a hyperparameter that controls the randomness of language model output. Lower temperature (approaching 0) makes the model favor the highest-probability tokens, producing more deterministic and conservative output; higher temperature flattens the sampling distribution, producing more diverse and creative output but with higher error risk. Coding tasks require precision, hence the recommended lower value of 0.6; creative writing or general conversation benefits from a higher 1.0 for more natural, fluent expression.
Notably, well-known developer Ivan tested MTP-LX version 0.3.5 and achieved 93.3% accuracy on a math benchmark within 5 minutes and 30 seconds, validating that output quality remains reliable under 4bit quantization.
Writing and Reasoning Capabilities
Beyond coding, the MTP-LX 4bit version's performance on other tasks is also noteworthy:
Writing ability: When asked to rewrite "He was very sad" into a visually evocative sentence, it produced "He curled up in the corner, buried his face in the crook of his arm, shoulders heaving silently"—concise and powerful, without the heavy AI flavor. A resignation letter reading "Return the keys, don't look back on sunny mornings, take your final bow facing forward into the wind—turns out turning around can be this light" was also quite elegant.
Reasoning ability: Faced with a financial planning problem ("monthly income of 7,000 RMB, first-tier city, save 600,000 in four years"), the model thought for 11 minutes and delivered a detailed plan. GPT-5.5 Thinking scored it 55/100, while GPT-5.5 Pro scored 82/100 on the same problem—there's clearly a gap with top-tier models, but for a locally-run 27B model, this is already commendable.
Hallucination test: When asked about "Li Bai winning second place in the 1998 New York Marathon" (an absurd claim), the model correctly identified the historical timeline contradiction and did not hallucinate.
The Hallucination Problem LLM "hallucination" refers to models generating content that appears plausible but is actually incorrect or fabricated—one of the major shortcomings of current LLMs. The root cause is that models are fundamentally probabilistic text prediction systems, not true knowledge retrieval systems. Testing a model's ability to identify absurd premises is an important dimension for evaluating its factual reliability. Qwen3.6-27B performed well on this test, indicating good alignment on factual consistency during training.

Conclusion and Recommendations
After comprehensive comparison of four solutions, MTP-LX is currently the best choice for running Qwen3.6-27B on Mac:
- Clear speed advantage: Achieves 40+ tok/s at 4bit quantization, nearly double other solutions
- Acceptable quality: Despite being 4bit, output quality for coding, writing, and reasoning tasks all falls within reasonable bounds
- Easy installation: Deployment requires just a few commands, with automatic Open WebUI compatibility
The current limitation is that MTP-LX does not yet support image recognition capabilities. If you need visual understanding, you may need to consider other solutions. But for pure text and coding tasks, the MTP-LX + Qwen3.6-27B combination already delivers a remarkably smooth local AI experience on Mac.
For Mac users, having a 27B parameter model run smoothly at 40+ tok/s was almost unimaginable a year ago. Apple Silicon's Unified Memory Architecture (UMA) means large model inference is no longer constrained by discrete VRAM capacity, while continued optimization of native frameworks like MLX further unlocks hardware potential. Local AI usability is improving rapidly and deserves the attention and experimentation of every developer.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.