Five AI Models Tested for Game Development: Which Is Best for Zero-Experience Coding?
Five AI Models Tested for Game Develop…
Head-to-head test: Claude Sonnet 3.7 leads in zero-experience AI game programming among five top models
A Bilibili creator tested five AI models (DeepSeek R1, Claude Sonnet 3.7, ChatGPT o3 Mini, Grok 3, Qwen 2.5 Max) by having them generate browser-based Snake games with added ball-bouncing mechanics. Claude Sonnet 3.7 stood out with correct functionality and autonomous UI enhancements. DeepSeek and ChatGPT performed adequately. Qwen and Grok 3 failed to correctly implement ball movement. The test proves zero-experience users can already create simple web games with AI assistance.
Introduction: The Era of Game Development with Zero Experience Has Arrived
Major AI models have made remarkable strides in reasoning and programming capabilities. Can someone with absolutely no game development experience create an indie game at zero cost using AI? A Bilibili content creator named Jiuling answered this question with a head-to-head comparison test.
This test selected five top-tier AI models: DeepSeek R1, Claude Sonnet 3.7, ChatGPT o3 Mini, Grok 3, and Qwen 2.5 Max. Using identical prompts, each model was asked to generate a runnable browser-based Snake game, followed by custom gameplay additions to test each model's comprehension and programming ability.
Test Method: A Minimalist Approach with Notepad + Browser
The testing approach was extremely simple — have AI generate HTML web game code, paste the code into Notepad, save it as an .html file, and open it directly in a browser to run.
HTML (HyperText Markup Language) is the foundational technology for building web pages. Combined with CSS (Cascading Style Sheets) and JavaScript (scripting language), it can deliver complete interactive applications in a browser. Web games are an ideal vehicle for AI programming tests because they require no development environment, compiler, or game engine — all modern browsers have built-in JavaScript runtimes and Canvas/SVG rendering capabilities. This means a single .html file is a complete executable program, dramatically lowering the barrier to verifying AI code output. This approach requires virtually zero technical skill from the user, making it perfect for testing AI's "out-of-the-box" capabilities.
The prompt design was straightforward: generate a Snake game that works on both PC and mobile. Interestingly, AI outputs vary each time — some models' first-generated code wouldn't run directly and required multiple attempts. For example, DeepSeek failed on its first try, and Claude Sonnet 3.7 only succeeded on its second attempt after enabling thinking mode.
This output inconsistency has a technical explanation: large language models use probability-based sampling strategies during text generation, where hyperparameters like temperature and top-p (nucleus sampling) determine the degree of randomness in output. Even with identical prompts, the token sequence sampled by the model may differ each time. In code generation scenarios, this randomness can lead to differences in variable naming, logical structure, or even functional completeness, making multiple attempts a reasonable usage strategy.
Basic Snake Game Test Results
For the classic Snake game's core functionality, all five models successfully implemented the basic gameplay, with varying UI designs. However, since Snake is such a classic game with abundant existing code online, models may have directly referenced existing solutions, making it difficult to reveal true differences in reasoning ability.
Advanced Challenge: Understanding and Implementing Custom Ball-Bouncing Mechanics
To truly differentiate the models, a custom requirement was added:
After the game starts, a ball is launched from the boundary every 5 seconds. The ball persists in the game and bounces off boundaries upon contact. If the snake's head is hit by any ball, the game ends.
This requirement tests AI's understanding of complex game logic — not only must it implement ball generation and physics-based bouncing, but it must also handle collision detection while keeping the original Snake gameplay intact.
From a programming perspective, the ball-bouncing mechanism is basic physics simulation. The core logic involves: maintaining position coordinates (x, y) and velocity vectors (vx, vy) for ball objects, updating positions each frame (x += vx, y += vy); when a ball reaches a boundary, the corresponding velocity component is negated (e.g., vx = -vx when hitting left/right boundaries). Collision detection requires calculating the distance between the snake head coordinates and all ball coordinates each frame to determine if it falls below a collision threshold. While this requirement is entry-level for human programmers, it demands that AI simultaneously understand and correctly combine four independent logic modules: "timed generation," "continuous motion," "boundary bouncing," and "collision detection" — making it an effective test of AI reasoning ability.
Detailed Performance of Each AI Model
DeepSeek R1: Adequate, Functional
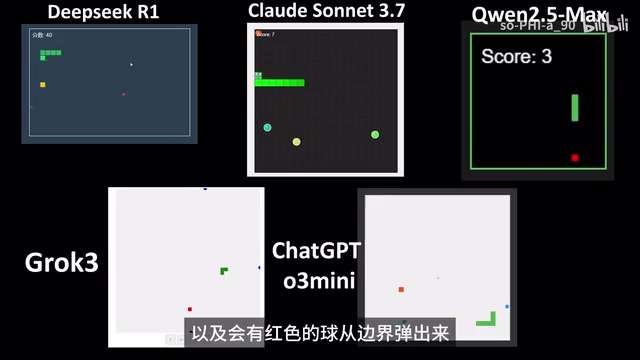
DeepSeek successfully implemented the core requirements — the snake eats yellow food dots while red balls launch from boundaries and continuously bounce. It basically fulfills the game design concept, but the overall presentation is plain with no additional visual design.
Claude Sonnet 3.7: The Biggest Surprise, Outstanding Design Sense
This was the standout performer in this test. Claude Sonnet 3.7 is a mid-to-high-end model from Anthropic, belonging to the "Sonnet" tier of the Claude 3 series (between the lightweight Haiku and flagship Opus). The model excels at code generation tasks, partly because Anthropic specifically optimized code comprehension and generation during training, while its RLHF (Reinforcement Learning from Human Feedback) process emphasizes output completeness and practicality.
The overall work showed very high completion quality: colorful gradient balls, gradient-colored snake head design, polished UI — these details were entirely absent from the prompt and were the model's own creative additions. It not only understood the game logic but proactively optimized the aesthetics. The "thinking mode" (Extended Thinking) mentioned is a distinctive Claude feature that allows the model to perform longer internal reasoning chains before generating the final answer, similar to an internalized version of Chain-of-Thought prompting, which helps with complex multi-step programming tasks.
Qwen 2.5 Max: Comprehension Error, Balls Don't Move
Qwen's model showed a clear comprehension error — while balls were generated at the boundaries, they didn't move at all. It failed to correctly understand the meaning of "launch" and "bounce," merely placing balls statically at boundary positions. From a technical standpoint, the model likely only implemented ball creation and positioning logic but omitted the critical steps of assigning initial velocity vectors to balls and continuously updating ball positions in the game loop.
Grok 3: Similar Comprehension Issues
Like Qwen, Grok 3 also produced blue balls that appeared at boundaries but didn't move. Both models showed deviations in understanding the "ball physics movement" requirement. This demonstrates that when facing tasks requiring translation of natural language descriptions into concrete physics simulation logic, different models exhibit significant differences in reasoning depth.
ChatGPT o3 Mini: Functionally Correct, Lacking Design Flair
Similar to DeepSeek R1's performance — correctly understood the game design concept and implemented functionality, but the visual presentation was basic with no additional design merit.
Comprehensive Programming Capability Assessment of Five AI Models
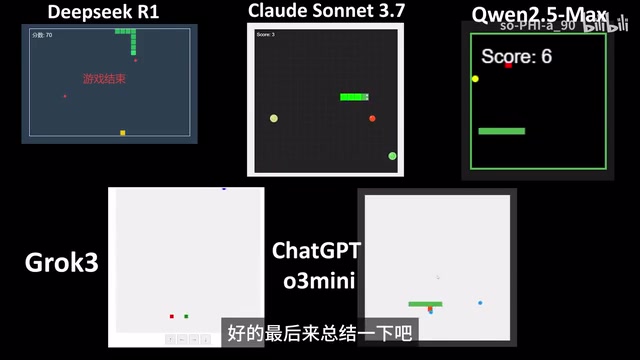
It's worth noting that AI results vary with each run, and what's shown here isn't necessarily each model's best performance. However, after multiple uses and comparisons, the following conclusions can be drawn:
AI Programming Capability Tier Ranking
| Tier | Model | Performance |
|---|---|---|
| First Tier | Claude Sonnet 3.7 | Accurate comprehension + Strong programming + Autonomous design sense |
| Second Tier | DeepSeek R1, ChatGPT o3 Mini | Functionally correct, adequate |
| Third Tier | Qwen, Grok 3 | Comprehension deviations, core features incompletely implemented |
Why Did Claude Sonnet 3.7 Stand Out?
- Comprehension: Accurately grasped the meaning of all game mechanics
- Programming ability: High code quality, stable execution
- Design extension: Proactively optimized UI and visual details without being asked
- Overall experience: Best suited for zero-experience users doing game or software prototyping
Practical Tips for Zero-Experience AI Game Development
For zero-experience users wanting to try AI game creation:
- Claude Sonnet 3.7 is the top choice for the best overall experience
- If the first-generated code doesn't run, don't give up — try multiple times or switch between Chinese and English instructions
- Start with simple games (like Snake) and gradually add custom requirements
- Some AI platforms have built-in web preview features (like Claude's Artifacts), which can save the step of manually saving files
Industry Trends and Future Outlook for AI-Assisted Development
AI-assisted programming is undergoing a paradigm shift from "code completion" to "complete application generation." Tools like GitHub Copilot and Cursor have already proven that AI can significantly boost professional developers' efficiency, while the scenario tested in this article represents another direction — enabling non-technical users to obtain runnable software directly through natural language. Currently, this capability is mainly limited to frontend web applications and simple scripts, because these programs have unified runtime environments (browsers), minimal dependencies, and immediate feedback. For complex applications requiring databases, network communication, and multi-file architectures, AI still struggles to generate complete, usable code in one shot and typically requires human intervention for debugging and integration.
This test proves that AI-assisted game development has moved from concept to practical reality. While currently limited to simple web games, as model capabilities continue to improve, the possibility of zero-experience users creating more complex games (such as tower defense or auto-battlers) is rapidly opening up.
Key Takeaways
- Claude Sonnet 3.7 performed best in the zero-experience game creation test, delivering correct functionality while autonomously optimizing UI design
- Qwen and Grok 3 showed deviations in understanding the custom ball-bouncing mechanism, failing to fully implement the requirements
- DeepSeek R1 and ChatGPT o3 Mini performed adequately, correctly implementing features but lacking design flair
- Zero-experience users can generate runnable web games through AI using only Notepad and a browser
- AI-generated code has inherent instability and may require multiple attempts or switching between Chinese and English instructions to run successfully
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.