返回播客列表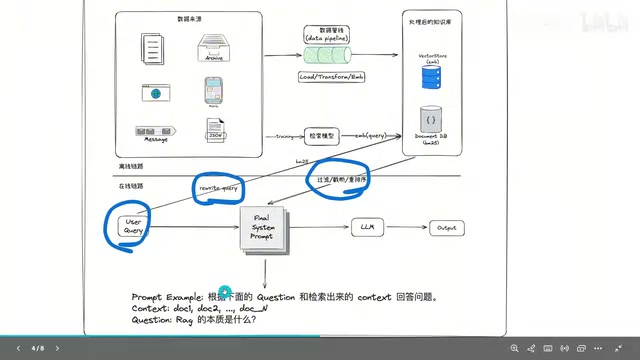
深度解读·6:42·对话
Agentic RAG完整指南:原理解析与代码实现
深入解析Agentic RAG与传统RAG的核心区别,详解工具调用、多步迭代、Query改写等关键机制,附LangChain和LangGraph代码实现,帮助开发者构建具备自主决策能力的智能检索增强生成系统。
收听播客对话
0:006:42
今天想聊一个特别实际的话题。如果你做过RAG系统——就是那种让大模型去查资料再回答问题的系统——你一定经历过那种崩溃时刻:用户问了个问题,系统检索回来一堆看似相关但完全没用的内容,模型就硬着头皮瞎编一个答案。或者更惨的,检索不到东西,直接回一句'我不知道',连重试都不会。
哈哈对,这个太真实了。我之前帮一个客户搭知识库问答系统,用户问'你们知识库里有哪些文档',系统直接懵了。因为传统RAG它只会去做向量相似度匹配嘛,你问它有哪些文档,它根本不知道怎么检索这个信息。这其实暴露了传统RAG一个根本性的问题——它就是一条固定的流水线,检索一次、生成一次、结束。没有任何灵活性。
对,我们先帮听众快速回顾一下传统RAG是怎么工作的。它其实分两个阶段,一个是离线准备,一个是在线查询。离线阶段就是把你的文档切成小块,用Embedding模型把每个小块变成向量,存到向量数据库里。在线阶段呢,用户一问问题,系统就把问题也变成向量,去数据库里找最相似的几个片段,塞给大模型,让它基于这些片段回答。
嗯,你说的这个流程其实还是比较基础的版本。稍微成熟一点的系统会做得更细,比如在线阶段会先做Query改写——用户的问题可能很口语化,不适合直接拿去检索。然后检索的时候会用双路检索,一路是BM25关键词匹配,一路是向量语义匹配,两者互补。最后还会用一个Reranker模型做精排,挑出真正最相关的片段。
这听起来已经挺完善了,但你刚才说的那些痛点还是存在?
对,因为不管你中间加了多少优化步骤,它本质上还是单向、一次性的。你看,如果第一轮检索没找到有用信息,系统不会说'哎,这次没找好,我换个关键词再试试'。它就直接把那些质量很差的片段塞给模型了。更别说那种需要多跳推理的复杂问题了——比如用户问'A公司去年营收比B公司高多少',你可能需要先查A公司的营收,再查B公司的,然后做计算。传统RAG一次检索根本搞不定。
所以Agentic RAG就是来解决这个问题的。这个名字里的Agentic,就是智能体的意思对吧?能不能用一句话说清楚它和传统RAG最本质的区别?
一句话的话就是:传统RAG是被动执行一条固定流水线,Agentic RAG是让大模型自己当指挥官,主动决定怎么检索。具体来说,它把所有检索相关的操作——语义搜索、列出文件、读取特定文档、获取元数据——全部封装成工具,然后告诉大模型'你有这些工具可以用,你自己决定什么时候用哪个'。
这个思路挺妙的。相当于从'给你一条路走到底'变成了'给你一个工具箱,你自己想办法'。
没错!而且它背后有一个很关键的机制叫ReAct循环——就是思考、行动、观察,然后再思考、再行动。模型会先想'这个问题我需要什么信息',然后调用一个工具去获取,拿到结果后评估'这个信息够不够,质量怎么样',不够的话就换个方式再来一轮。这个循环可以进行好多轮,直到模型觉得信息充分了才生成最终答案。
能不能举个具体的例子,让大家感受一下这个差异?
好,比如用户问了一个比较模糊的问题。传统RAG就直接拿这个模糊的问题去检索,可能检索结果很差,然后模型就硬生成一个不靠谱的答案。但Agentic RAG的处理过程可能是这样的:第一轮,模型用原始Query去搜索,发现相似度分数很低,它就会想'这个检索结果不行,可能是我的搜索词不够精准'。第二轮,它自己改写Query重新搜,这次命中了相关片段。第三轮,它发现检索到的片段信息不完整,因为答案刚好被切在了两个chunk的边界,于是它调用Read File工具去读取前后的片段补充上下文。最后才基于完整信息生成答案。
这个Read File工具很有意思。传统RAG里切片导致的信息碎片化问题一直很头疼,Agentic RAG等于是让模型自己去主动补全上下文了。
对,而且还有List Files这个工具,专门解决'你有哪些文档'这类元信息查询。还有Gather File Meta,获取文件的创建时间、作者、页数这些元数据。你想想,传统RAG对这些完全无能为力,但在实际业务场景中用户经常会问这类问题。
那从代码实现的角度来看,复杂度差别大吗?我看到现在LangGraph这类框架已经把ReAct Agent封装得很好了。
其实核心代码反而很简洁。你定义好工具集,然后用LangGraph的create_react_agent把模型和工具绑在一起就行了。LangGraph和LangChain的线性Chain不一样,它是基于有向图的,天然支持循环和条件分支,特别适合实现ReAct这种需要反复迭代的模式。代码看着简单,但背后的能力完全不一样了——模型获得了自主决策的权力。
不过我有个疑问,多轮工具调用意味着更多的API调用、更多的Token消耗、更长的响应时间。在生产环境中这个代价能接受吗?
这确实是需要权衡的。Agentic RAG本质上是用时间换智能。一个请求可能涉及三到五次工具调用,延迟肯定比传统RAG高。但你想想,如果传统RAG给了一个错误答案,用户还得重新问、重新等,总时间可能更长。所以关键是看场景——对实时性要求极高的场景,可能还是传统RAG更合适;但对答案质量要求高的场景,比如企业知识库、专业文档分析,Agentic RAG的优势就很明显了。
嗯,这个trade-off说得很清楚。最后我想总结几个关键点。第一,Agentic RAG的核心不是什么新算法,而是思维方式的转变——从固定流程到智能决策。第二,工具本身是静态的,真正的智能在于模型的选择和规划能力。第三,即使有了Agentic能力,离线阶段的文档切分、Embedding选择这些基础工作依然是重中之重,巧妇难为无米之炊嘛。
补充一点,其实现在市面上很多所谓的AI应用,底层就是ReAct加Tool Use这套范式。理解了这个,你就抓住了当前大部分AI应用的技术内核。而且Agentic RAG还在快速演进,多Agent协作、知识图谱融合这些方向都很值得关注。对于做大模型应用的工程师来说,这已经不是加分项了,是必备技能。
说得好。一句话总结今天的内容:传统RAG是一条流水线,Agentic RAG是一个会思考的决策者。从被动执行到主动决策,这就是RAG范式演进的核心方向。