返回播客列表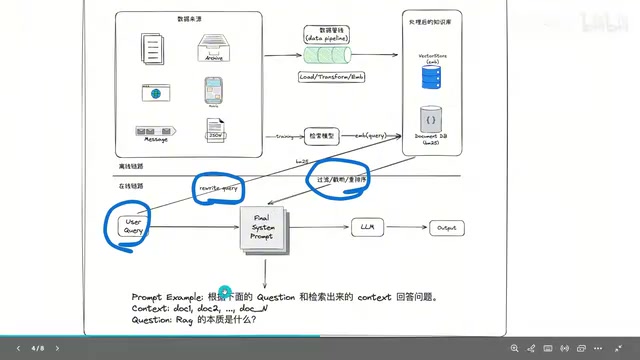
教程攻略·8:18·对话
Agentic RAG实战教程:用LangGraph实现智能检索增强生成
深入讲解Agentic RAG的原理与代码实现,对比传统RAG的局限性,通过LangChain和LangGraph演示如何将检索能力工具化,让大模型具备自主决策、多轮迭代检索的智能体能力。
收听播客对话
0:008:18
今天聊一个我觉得特别有意思的话题——RAG的进化。做过大模型应用的朋友应该都搭过RAG系统,但说实话,传统RAG用起来真的是又爱又恨。"},
{"speaker": "guest", "text": "哈哈对,爱它是因为确实能让大模型接上外部知识,恨它嘛……你肯定遇到过那种场景,用户问了个问题,检索到一堆看似相关但完全没用的内容,模型就硬着头皮瞎编一个答案出来。"},
{"speaker": "host", "text": "太真实了。还有一种更尴尬的,用户问"你知识库里有哪些文档",系统直接懵了,因为传统RAG压根就没设计这个能力。"},
{"speaker": "guest", "text": "对,这就是传统RAG最根本的问题——它是一条直线走到底的流程。检索一次,生成一次,结束。不管检索结果好不好,它都不会回头重试。你可以把它想象成一个只会按固定路线走的快递员,送错地址了也不会自己纠正。"},
{"speaker": "host", "text": "那我们先帮听众理清一下传统RAG到底是怎么工作的吧。它其实分两条链路对吧?"},
{"speaker": "guest", "text": "嗯,一条离线一条在线。离线链路跟用户无关,就是做数据准备:把PDF、Word这些文档加载进来,切成小段落,比如每256个字符一段,然后用Embedding模型把每段文字变成一个向量,最后存到向量数据库里。这里面有个特别容易被忽视的环节就是文本切片。切太大,向量的语义就被稀释了,变得模糊;切太小呢,上下文丢了,模型看不懂这段在说什么。"},
{"speaker": "host", "text": "所以切片策略其实是个技术活,不是随便切就行。"},
{"speaker": "guest", "text": "完全是。LangChain里常用的RecursiveCharacterTextSplitter就挺聪明的,它会按段落、句子、字符这个优先级递归地切,尽量保持语义完整。另外Embedding模型的选择也很关键,中文场景下BGE、M3E这些国产模型往往比OpenAI的通用Embedding效果更好。"},
{"speaker": "host", "text": "好,离线准备好了,在线链路呢?"},
{"speaker": "guest", "text": "在线链路就是处理用户实时查询。一般会先做Query改写,因为用户的问题不一定适合直接拿去检索。然后做双路检索——BM25做关键词匹配,向量检索做语义匹配,两路结果合并。这两个其实互补性特别强:BM25擅长精确匹配,比如产品型号、专有名词,但它不理解"汽车"和"轿车"是一回事;向量检索能理解语义,但在精确术语上可能不如关键词搜索。"},
{"speaker": "host", "text": "合并之后还有个重排序的步骤?"},
{"speaker": "guest", "text": "对,Rerank是提升精度的关键。初始检索本质上是把query和文档分别编码再算相似度,效率高但精度有限。Rerank模型用的是交叉编码器,把query和文档拼在一起输入,能捕捉更细粒度的语义交互。虽然计算成本高一些,但它只需要对初始检索返回的几十条候选文档重排,延迟可控,却能把最终结果的相关性提升百分之三十到五十。"},
{"speaker": "host", "text": "听起来传统RAG也做了不少优化,但你刚才说的核心问题还是在——整个流程是单向的、一次性的。"},
{"speaker": "guest", "text": "没错,第一轮没检索到有用信息,它就直接告诉你"我不知道",不会换个关键词重试,也不会主动去读更多上下文。这就是Agentic RAG要解决的问题。"},
{"speaker": "host", "text": "那Agentic RAG到底做了什么根本性的改变?"},
{"speaker": "guest", "text": "核心理念其实就一句话:把检索能力工具化。它把Query改写、向量检索、文件读取这些环节全部封装成可调用的工具,然后让大模型自己决定什么时候调用哪个工具。整个过程变成了一个闭环——思考、行动、观察结果、再思考、再行动,直到模型觉得信息够了才生成最终答案。"},
{"speaker": "host", "text": "这个闭环就是ReAct框架对吧?"},
{"speaker": "guest", "text": "对,ReAct是2022年提出的,全称是Reasoning加Acting。传统的思维链只让模型推理但不跟外部环境交互,ReAct把推理和行动交织在一起。而且它有个很大的优势——每一步的思考和行动都有明确记录,出了问题你能精确定位是推理错了还是工具调用错了,可调试性特别好。"},
{"speaker": "host", "text": "那实现Agentic RAG,模型需要具备哪些能力?"},
{"speaker": "guest", "text": "三个核心能力。第一是规划能力,模型要能规划执行步骤;第二是工具调用能力,这是技术前提,模型要能输出结构化的JSON来触发工具调用;第三是多步迭代能力,能在多轮工具调用之间保持上下文。其中工具调用这个能力不是所有模型都支持的,不支持的话就得靠精心设计的Prompt来模拟,但稳定性会明显下降。"},
{"speaker": "host", "text": "你提到了一个开源项目ChatBoss,它的实现挺有代表性的?"},
{"speaker": "guest", "text": "嗯,ChatBoss的设计很巧妙。它进来先判断模型支不支持工具调用,不支持的话就走传统路线,用Prompt判断要不要检索;支持的话就把所有工具注册进去,让模型自己决策。它定义了四个工具:语义搜索、列出文件清单、精确读取特定文档片段、获取文件元数据。这四个工具组合起来就能覆盖传统RAG做不到的事——比如回答"你有哪些文档"、主动读取前后片段补充上下文。"},
{"speaker": "host", "text": "代码层面呢?用LangGraph实现起来复杂吗?"},
{"speaker": "guest", "text": "其实代码量不大。LangGraph是LangChain团队出的框架,专门用来构建有状态的多步骤Agent。它基于图的抽象,支持条件分支、循环和状态持久化,天然适合这种多轮迭代场景。核心就是用create_react_agent把模型、工具集和系统提示词组装起来,几行代码就搞定了。但有个坑要注意——系统提示词里必须严格限制输出格式,不然模型可能把JSON里的引号或括号吃掉,工具调用就解析失败了。"},
{"speaker": "host", "text": "所以本质上,Agentic RAG是用时间换智能——多跑几轮,但每轮都是有目的的。"},
{"speaker": "guest", "text": "说得特别准确。而且你可能没注意到,现在国内很多所谓的"套壳"应用,核心逻辑其实就是这套Agentic RAG。掌握了这个模式,你就理解了大部分RAG产品背后的技术本质。"},
{"speaker": "host", "text": "最后帮大家总结一下。传统RAG是固定流水线,简单直接但脆弱;Agentic RAG把检索能力变成工具,让模型自己决定怎么用,形成思考和行动的闭环。用你的话说就是——工具赋予能力,智能在于选择。"},
{"speaker": "guest", "text": "对,始于检索,成于决策。这才是RAG该有的样子。"}
],