返回播客列表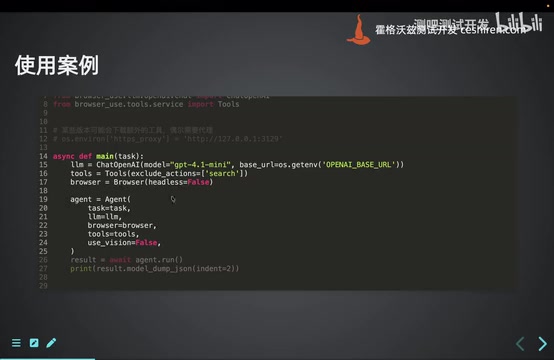
教程攻略·7:27·对话
Browser Use深度解析:自然语言驱动的浏览器自动化智能体实战指南
深入解析Browser Use浏览器自动化智能体的架构原理、安装配置、CDP底层框架及pytest实战应用。掌握自然语言驱动的AI Agent如何替代重复性浏览器操作,提升Web自动化测试效率。
收听播客对话
0:007:27
今天想跟你聊一个我最近特别感兴趣的工具——Browser Use。你想象一下,你跟浏览器说一句「帮我打开百度搜索Python」,它就自己动起来了,自己打开页面、输入关键词、点搜索,全程不用你写一行定位脚本。
对,这个工具现在在业内确实很火。它的定位很明确——自然语言驱动的浏览器自动化智能体。说白了就是你用日常说话的方式描述任务,它背后的AI Agent帮你拆解成一步步的浏览器操作去执行。阿里云之前技术文章里也提到过用它做核心智能体方案,算是目前这个赛道里公认最成熟的开源工具之一了。
嗯,这里面有个关键词——Agent,智能体。很多听众可能对这个概念还比较模糊,你能展开说说它跟普通的AI问答有什么本质区别吗?
好问题。你平时用ChatGPT,基本上是一问一答对吧?你问它一个问题,它给你一个回答,结束了。但Agent不一样,它是一个持续运转的循环系统。它先感知环境——比如看看当前浏览器页面长什么样,然后推理——我下一步该干嘛,再执行——比如点击某个按钮,执行完了再回头看结果对不对,不对就调整策略。这个「感知-决策-行动」的循环会一直转,直到任务完成。所以它不是回答问题,它是在真正地做事情。
明白了,这就像一个有眼睛有手还会思考的助手。那我们来拆一下它的架构,Browser Use内部到底是怎么运转的?
它的架构其实挺经典的,就是智能体加大模型加工具这个标准范式。从上往下看,最上面是客户端层,支持命令行、Python API和在线云服务三种方式。中间是智能体内核,负责管理消息历史、协调各个组件。然后是大模型层,兼容OpenAI、Claude、Ollama这些主流模型。最底下是浏览器控制层,负责实际操作浏览器。
这里面有一个技术细节我觉得特别值得聊——它跟大模型交互用的是结构化返回,而不是Function Calling。这两个有什么区别?
这个选择其实很聪明。Function Calling是OpenAI在2023年推出的机制,模型可以声明要调用某个函数并输出参数。但问题是,这个机制依赖各家模型提供商的特定API实现,不同厂商支持程度不一样,格式也不统一。而结构化返回呢,本质上就是在提示词里定义好一个JSON Schema,让模型按这个格式输出JSON数据。只要模型能遵循指令输出合法JSON就行,不依赖任何特定的API特性。所以Browser Use选这条路,适配范围一下子就宽了很多。
你看这就是一个很务实的工程决策——为了兼容性牺牲一点便利性。那底层的浏览器控制这块,我注意到它从Playwright迁移到了CDP协议,这个变化意味着什么?
这个迁移挺关键的。CDP就是Chrome DevTools Protocol,Chrome浏览器内置的远程调试协议,通过WebSocket直接跟浏览器底层通信。Playwright虽然底层也用CDP跟Chromium通信,但它在上面又加了一层自己的抽象协议和进程管理。在短任务里这没什么问题,但在长时间运行的场景下,这个中间层会引入额外的开销和不稳定因素。Browser Use做的就是把这个中间层去掉,直接跟浏览器对话。
但Playwright毕竟是微软维护的成熟框架,有很多好用的高级特性,比如自动等待元素可交互、跨浏览器支持这些。去掉它不会丢失很多便利功能吗?
确实,这是一个典型的控制力和便利性之间的取舍。比如Playwright的Auto-waiting机制,点击之前自动等元素变成可交互状态,开发者不用自己写等待逻辑,非常省心。迁移到自研CDP框架之后,这些东西就得自己重新实现了。但对于Browser Use这种需要长时间稳定运行的Agent场景来说,稳定性是第一优先级,这个取舍是合理的。而且他们的新框架也加了不少好东西,比如AI辅助定位——可以用自然语言描述让大模型帮你找页面元素。
有意思。那我们再聊聊它的提示词工程,我知道你专门做过抓包分析?
对,抓包看了它跟大模型之间的通信内容,设计得相当精细。系统提示词分五层:先是角色定义,告诉模型你是一个浏览器自动化AI;然后列举所有可执行的操作;接着是上下文信息,包括当前页面状态、DOM结构、执行历史;再加上一大堆推理规则和行为规范;最后要求模型按ReAct格式输出。
ReAct这个概念可能有些听众不太熟悉。
ReAct是2022年普林斯顿和Google联合提出的Agent推理框架,核心思想就是让模型交替进行推理和行动。每一步先想——我现在看到什么、该怎么做,然后再动——执行一个具体操作,再根据结果想下一步。Browser Use把这个过程结构化成了几个字段:thinking是当前的思考过程,evaluation是对页面状态的评估,memory是需要跨步骤记住的信息,next_goal是下一步目标,action是具体要执行的操作。每一步决策都清清楚楚,可追溯。
这个设计确实很透明。那实际使用的时候,有什么需要注意的坑吗?
有几个点。第一,视觉模型默认是auto自动检测,但我强烈建议关掉。视觉识别现在稳定性还不够,纯文本模式下它基于可访问性树来解析页面,反而更靠谱。可访问性树本来是给屏幕阅读器用的,过滤掉了样式和布局噪音,只保留语义信息,传给大模型的Token数量也少很多。第二,国内用户首次运行要注意配置代理,因为它启动时会下载一些海外资源。第三,工具响应策略可以自定义,比如生成大文件的时候,别把内容全发给大模型,告诉它任务完成就行,省Token。
说到实际应用,做Web自动化测试的团队应该会很感兴趣。它跟pytest结合起来效果怎么样?
非常自然。用pytest的参数化功能,把测试用例写成自然语言列表,每条就是一个任务描述,比如「打开百度搜索Python」「打开某社区进入高级搜索搜索自动化测试」。pytest自动遍历执行,每条都创建一个Agent跑一遍。更进一步的话,你可以从Jira、禅道这些测试管理平台动态拉取用例,搭一条全自动的测试流水线。
所以本质上它把写测试脚本这件事的门槛大幅降低了——以前你得写定位器、写操作代码,现在用自然语言描述就行。
没错,而且不光是门槛降低。传统脚本最头疼的就是页面一改、元素一变,脚本就挂了。自然语言驱动的方式天然就有一定的容错能力,因为Agent会根据当前页面状态重新推理,不是死板地按预设路径走。当然它也不是万能的,复杂场景下大模型的推理可能出错,但对于大量常规的回归测试场景,已经完全够用了。
最后帮大家总结一下。Browser Use的核心价值就是三个词:自然语言驱动降低门槛,结构化返回保证广泛的模型兼容性,CDP协议提供长时间运行的稳定性。如果你的团队在做Web自动化测试,或者有大量重复性的浏览器操作需要自动化,这个工具确实值得认真评估一下。
对,我补充一点——它的架构设计非常标准,代码也开源,即使你不直接用它,研究它的实现思路对理解AI Agent的工程化落地也很有帮助。推荐大家去看看源码,尤其是提示词工程和ReAct实现那部分,设计得确实漂亮。