返回播客列表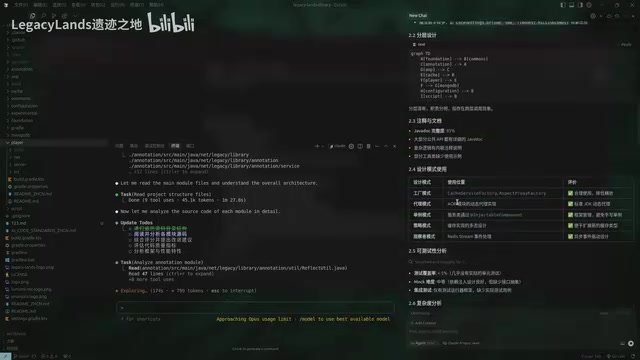
产品体验·6:27·对话
Cursor vs Claude Code实测对比:4万行Java项目分析谁更强?
通过2-4万行Java真实项目,使用相同模型和提示词,实测对比Cursor与Claude Code在代码分析、设计模式识别、测试覆盖率评估等方面的表现差异,附O3模型第三方评判结果。
收听播客对话
0:006:27
最近有个话题在开发者圈子里讨论得特别热——Cursor和Claude Code到底谁更强。但今天我想聊的不是那种泛泛而谈的比较,而是一个开发者做的非常硬核的实测。他拿了一个真实的Java项目,大概两三万行代码,用完全相同的模型、完全相同的提示词,分别让这两款工具去分析,结果差距还挺让人意外的。
对,我看了这个测试,觉得最有意思的地方就在于——它排除了模型能力的变量。你知道很多人比较AI工具的时候,其实是在比较背后的模型,但这次不是。同一个模型,同样的提示词,甚至还专门把Claude Code的自定义提示词文件都删掉了,确保起跑线一样。这样一来,最后的差异就只能归因于工具本身的设计了。
嗯,先说说这个测试项目吧。它叫LexiLens Library,是一个Minecraft插件开发的综合库,11个核心模块,技术栈里有一些比较小众但专业的东西,比如Fairy、Flame这些框架。这本身就是个考验——AI工具能不能理解这些不那么主流的技术组件。
没错,Fairy其实是一个专门给Minecraft服务端插件用的依赖注入框架,有点像游戏世界里的Spring。Flame是配套的命令和事件处理系统。这些东西在通用的编程知识库里不算热门,所以AI能不能准确识别它们,确实能看出工具的理解深度。
那我们直接看结果。Claude Code拿到任务之后第一件事是什么?
它先列了一个To-Do清单。你看,这个行为本身就很有意思——它没有急着去读代码,而是先做了一个任务规划,把'分析这个项目'这个大任务拆成了好几个子任务,然后一步一步执行。最终它统计出来接近4万行代码,其中测试代码1.1万行,识别出了8种设计模式,还给代码质量打了量化评分,比如命名规范给了95分,但具体指出了哪些命名不够好。
8种设计模式,这个数字挺亮眼的。
对,模板方法、策略模式、注册表模式、责任链、单例、动态代理、建造者、工厂,全都列出来了。其中注册表模式在Minecraft开发里特别常见,用来管理方块、物品这些游戏对象的全局注册。能识别出这个,说明它真的理解了这个项目的领域特征,而不只是在做通用的代码扫描。
还有一个发现我觉得特别厉害——ClassLoader隔离导致的GC阻塞问题?
这个是真的深。你看,Minecraft的插件系统里每个插件都有独立的ClassLoader来做类隔离,方便热加载和卸载。但如果卸载的时候,这个ClassLoader还被别的东西引用着——比如静态字段、线程局部变量什么的——JVM就没法回收它,Metaspace内存就会一直涨,最后可能直接OutOfMemoryError。这种问题在日常代码审查中极难发现,Claude Code能指出来,说明它的分析已经触及到运行时行为层面了,不只是看代码风格。
那Cursor这边呢?同样的提示词,表现怎么样?
嗯,怎么说呢,差距比较明显。Cursor拿到任务后直接就开始读文件了,没有规划阶段。最让人惊讶的是测试覆盖率这个判断——它一上来就说'测试覆盖率几乎为零,只有测试框架没有实际测试用例'。但实际上每个模块的Test包里都有大量测试啊,包括异常处理测试、并发测试。开发者指出来之后它才改口。
这就有点尴尬了。设计模式那边呢?
只识别出5种,比Claude Code少了3种,而且缺乏详细说明。潜在问题分析也比较薄弱,还给了一个让开发者摸不着头脑的'Optional控制针风险'建议,开发者说完全不知道这个建议从哪来的。
不过Cursor也不是一无是处吧?
对,在可视化呈现上Cursor确实扳回了一局。Claude Code画模块关系图用的是ASCII字符,就是那种终端里的文本图,功能是全的但看着比较朴素。Cursor生成的图表就漂亮多了,开发者自己都说'Cursor画的图还是挺好看的'。
后来开发者还做了一件很聪明的事——把两份报告匿名提交给O3模型做盲评。
这个方法论我觉得很值得推广。他把工具名称都隐去了,就标注为AIA和AIB,让O3来判断哪份报告更好。这样可以避免评测者对某个品牌的主观偏好。当然这个方法也不完美,O3本身可能对特定的文本风格有偏好,但至少比纯人工主观评价更可复现。
O3的结论是什么?
明确倾向Claude Code。核心理由是量化数据更精准、报告完整性更高、准确性更可靠。不过O3也说了,Cursor的报告'内容价值仍然高,可作为补充视角',不是说完全没用。
那回到最核心的问题——同一个模型,为什么表现差这么多?
其实就是工具层面的设计哲学不同。你想,大语言模型的上下文窗口是有限的,几万行代码不可能一次性全塞进去。Claude Code在终端里运行,可以直接用grep、find、wc这些命令先做预筛选和统计,在把代码送给模型之前就完成了信息压缩。它的To-Do清单机制本质上是一种Agent式的多步推理——大任务拆小,每步只加载必要的上下文。而Cursor作为IDE插件,它的索引策略更偏向'按需加载',在快速补全和局部修改的场景下效率很高,但全局遍历的大规模分析就容易遗漏。
所以本质上是一个'深度优先'和'效率优先'的取舍。
对,说得很准确。Claude Code像一个会先画思维导图再动手的分析师,Cursor更像一个手速极快的程序员,拿到需求就开干。两种风格在不同场景下各有优势。
那对于普通开发者来说,选择建议是什么?
其实很简单——如果你要做大型代码库的深度审查、架构分析、技术债务评估这类工作,Claude Code目前确实更靠谱。但如果是日常写代码、快速补全、小范围重构,Cursor的IDE集成体验和响应速度可能更顺手。最理想的当然是两者结合,各取所长。
嗯,我觉得这次测试最大的启示其实不是'谁更强',而是让我们意识到——AI编程工具的能力不仅取决于背后的模型,工具本身怎么调度模型、怎么管理上下文、怎么规划任务,这些'工程层面'的设计同样关键。选工具的时候,得先想清楚自己的工作流是什么样的。
完全同意。而且这个领域变化太快了,今天的结论可能半年后就不适用了。保持关注,多自己动手试,比听任何人的推荐都管用。