返回播客列表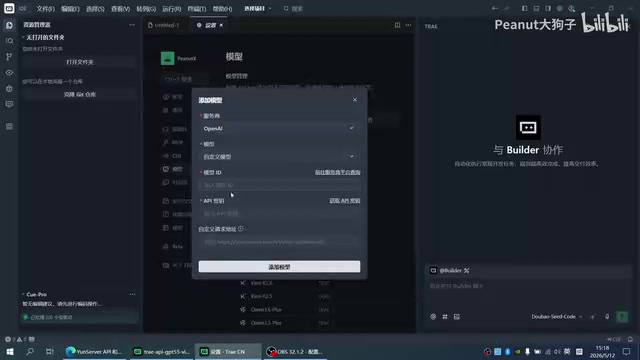
教程攻略·6:30·对话
Trae接入GPT-5.5完整教程:API中转站配置与实测效果
手把手教你在Trae IDE中通过API中转站接入GPT-5.5,包含Base URL配置、API Key设置、报错排查,以及HTML页面生成和代码迭代优化的真实效果评测,附成本控制建议。
收听播客对话
0:006:30
最近开发者圈子里有个话题特别火——OpenAI的GPT-5.5发布之后,大家都在琢磨怎么把它用到自己的开发工具里。今天我们就来聊一个很实际的事情:怎么在字节跳动的AI IDE Trae里接入GPT-5.5,以及它实际写代码的效果到底怎么样。
对,这个话题我觉得特别有意思。因为Trae本身已经内置了AI编程能力,它有字节自研的豆包大模型嘛。但很多开发者就想,能不能给它换一个更强的大脑?GPT-5.5作为OpenAI 2025年中期发布的旗舰模型,在代码生成准确率上确实有明显提升,尤其是前端开发这块,一次通过率比前代高了不少。
不过有个现实问题,国内直接调OpenAI的API并不方便。所以这里就用到了一个叫API中转站的东西,你能简单解释一下这是什么吗?
嗯,你可以把它想象成一个快递中转仓。你在国内发一个请求,这个请求先到中转站的服务器——这个服务器部署在一个既能访问国内网络、又能访问海外OpenAI服务器的节点上——然后中转站帮你把请求转发给OpenAI,拿到结果再回传给你。对开发者来说,只需要把请求地址换成中转站的地址就行了,不用自己折腾VPN什么的。
听起来挺方便的。但我得提一句,这毕竟是第三方服务,你的代码请求是经过人家服务器的,涉及敏感代码或者商业项目的时候,数据安全这根弦还是得绷着。
这点非常重要,后面我们也会专门说到。
好,那具体在Trae里怎么配置呢?
其实特别简单,核心就填四个东西。打开Trae的设置,找到AI模型配置的入口,新建一个OpenAI类型的模型。第一个填服务商,选OpenAI;第二个填模型ID,写GPT-5.5;第三个是API Key,就是你在中转站后台生成的密钥;第四个是Base URL,填中转站给你的请求地址,注意路径里要包含/v1/chat/completions。
这个/v1/chat/completions是什么?
这是OpenAI Chat Completions API的标准端点,你可以理解为一个统一的对话接口格式。它已经成了大模型领域的事实标准了,不光OpenAI用,Claude、Gemini、还有各种开源模型的推理框架都兼容这个格式。所以Trae只要支持这套格式,理论上就能接入各种模型服务,这也是整个方案能成立的技术基础。
明白了。那配置保存之后呢?
保存后先发一条简单消息测试一下,比如让它自我介绍一下、说说自己是什么模型。能正常返回就说明链路通了。如果报错的话,按优先级查三个地方:第一看Base URL格式对不对,少一段路径都不行;第二看API Key有没有复制完整,首尾字符容易漏;第三看模型ID跟中转站后台支持的名称是不是完全一致,大小写都要对上。
好,配置搞定了,我们来看实际效果。第一个测试任务是什么?
第一个任务是让GPT-5.5从零生成一个表白HTML单页。要求还挺具体的:只用HTML、CSS和JavaScript,不依赖外部框架;要有居中的表白文案、柔和配色;点击按钮弹出隐藏告白;还要有爱心动画效果;而且得是响应式布局,手机电脑都能看。
这个需求其实不算简单,涉及布局、交互、动画好几个层面。结果怎么样?
结果还挺惊喜的。GPT-5.5直接输出了一个完整的index.html文件,浏览器打开之后,配色柔和、排版舒服,按钮点击后隐藏告白正常弹出,爱心动画也很流畅。基本做到了一次生成就能用,代码结构也很清晰,功能点全部覆盖了。
一次生成就能用,这个确实不错。但说实话,从零写一个页面相对还好,更考验模型能力的是在已有代码上改东西。你们第二轮测试就是这个方向吧?
对,第二轮测试更贴近日常开发。在刚才那个表白页面的基础上,要求加两个交互功能:一个是「再想想」按钮,鼠标靠近的时候自动躲开——就是你怎么都点不到它;另一个是点击「愿意」按钮后,页面切换到一个成功状态。
这个任务的难点在哪?
难点在于模型得真正读懂已有代码。它需要同时理解现有的DOM结构、CSS样式的层叠关系、JavaScript的事件绑定逻辑,然后在不破坏原有功能的前提下,精准地添加新特性。你知道早期模型在这种任务里经常出现一个问题叫「幻觉式重构」——看起来新功能加上了,但悄悄改动了不相关的代码,原来好好的功能反而坏了。
改一处坏三处,这个开发者应该深有体会。
哈哈对,这是最让人崩溃的。但GPT-5.5的表现确实不错,它完整保留了原有的视觉风格,「再想想」按钮的躲避效果灵敏自然,「愿意」按钮的状态切换也没问题。说明它在连续修改任务中能维持代码结构的一致性,上下文理解能力是过关的。
听起来效果不错。但我想聊聊实际使用中大家比较关心的成本问题。GPT-5.5毕竟是旗舰模型,Token单价不便宜吧?
这个确实要注意。简单说一下,Token是模型处理文本的最小单元,中文每个汉字大概消耗1.5到2.5个Token。费用分输入和输出两部分,输出Token的单价通常是输入的两到四倍。举个例子,一个详细的需求描述可能消耗五百到一千个输入Token,模型生成一个完整HTML页面可能产生两千到五千个输出Token。再加上中转站的加价,单次复杂任务的成本可能到几块钱人民币。
所以建议是先小额充值跑通核心场景,别一上来就大量投入。
对,而且API Key的安全管理也很重要。Key等同于你的账户凭证,录屏截图分享配置的时候一定要打码。最好为不同用途生成独立的Key,出问题了方便定位和撤销。
最后帮大家总结一下,从这两轮实测来看,Trae加GPT-5.5这个组合适合什么场景?
我觉得三类场景比较合适:第一是小型前端页面和工具开发,一次性生成或少量迭代就能完成的项目;第二是快速原型验证,需要快速看到效果但对工程化要求不高的时候;第三是学习和技术探索,想体验最新模型能力上限的开发者。但对于大型项目的持续开发,长上下文场景下的稳定性还需要更多验证。
嗯,说到底配置很简单,几分钟就能搞定。但值不值得长期用,关键还是看你自己的项目里能不能稳定跑、响应速度和调用费用能不能接受。建议大家先拿个小项目跑一遍完整流程,根据实际体验再做决定。