#JSON格式错误
共 3 篇相关文章
·10 分钟
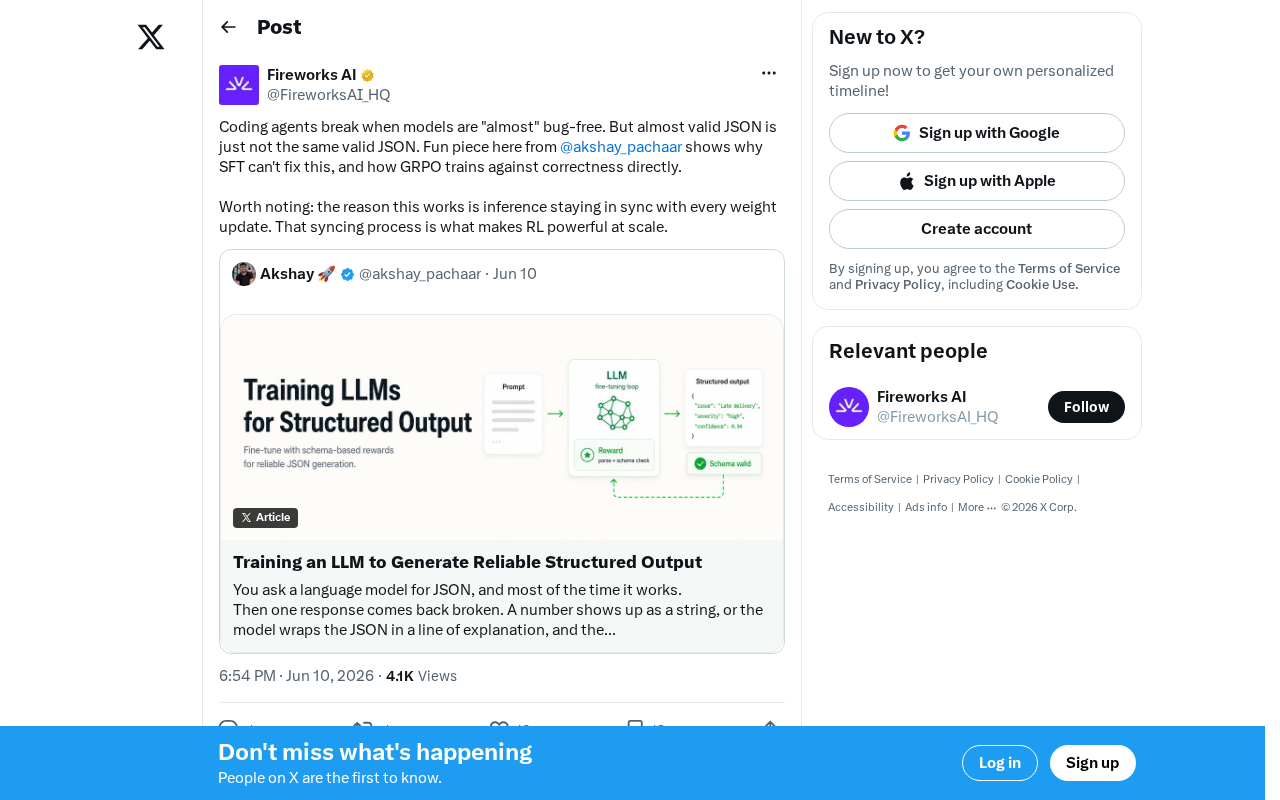
SFT无法修复JSON错误的根因:GRPO正确性训练如何突破编码Agent瓶颈
深入分析为什么监督微调(SFT)无法解决编码Agent的JSON格式错误问题,以及GRPO(群组相对策略优化)如何通过二元奖励信号和推理权重同步机制,直接针对输出正确性训练,实现从"几乎正确"到"完全正确"的跨越。
阅读全文 →
 科技前沿
科技前沿·6 分钟
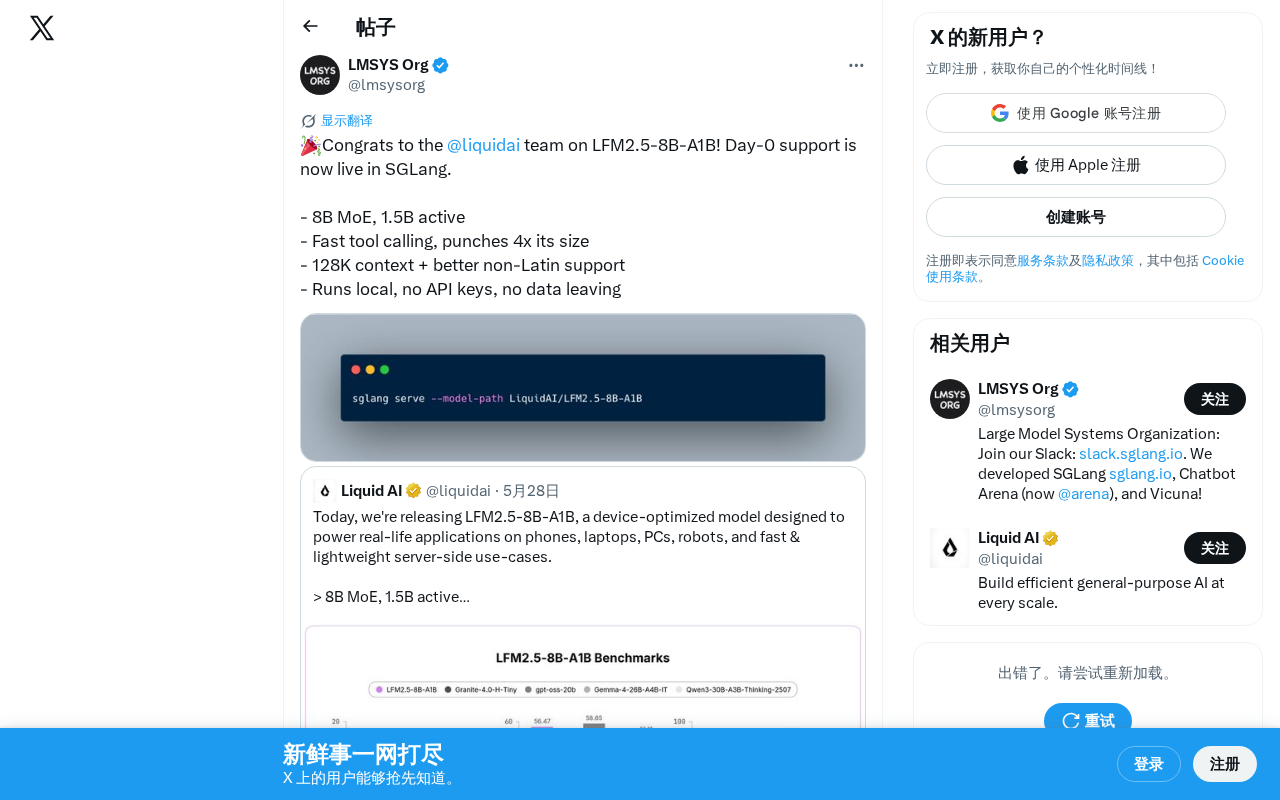
LFM2.5-8B-A1B:1.5B激活参数实现4倍体量效果的MoE模型
Liquid AI发布LFM2.5-8B-A1B模型,采用MoE架构,8B总参数仅激活1.5B,在工具调用场景中媲美6B级模型表现。支持128K上下文、本地部署、多语言,SGLang即时支持。
阅读全文 →
 教程攻略
教程攻略·9 分钟
Shopify Agent冷启动实战:零对话数据训练生产级AI的三步法
Shopify公开生产级AI Agent冷启动方案:零真实对话数据下,从已有业务流程倒推训练样本,微调Qwen-32B实现速度提升2.2倍、成本降低60%。详解三步数据构造法、Tool Call链路设计及企业AI落地启发。
阅读全文 →