11万PR实测:5款AI编码Agent谁更靠谱?
11万条PR实证研究揭示AI编码Agent代码质量不及人类,长期存活率仅约50%
MSR 2026一项覆盖11万条PR、5款主流编码智能体的大规模实证研究表明,AI编码Agent在PR合并率、代码长期存活率等关键指标上显著落后于资深人类开发者。AI代码3个月流失率比人类高40%,一年存活率仅约50%,核心模块更低至30%。研究建议团队对AI代码建立差异化评审标准,将非核心任务交给AI,核心逻辑仍由人类主导,并建立长期质量监控机制。
研究背景:AI编码Agent已深入实际开发流程
从自动补全到独立提交PR,自主编码智能体(Coding Agent)已经真正切入到软件开发的核心流程中。GitHub Copilot、Devin、Claude Code等工具在开源社区中的贡献占比持续攀升,但一个关键问题始终悬而未决:这些智能体的贡献质量到底怎么样?和人类开发者相比有什么差异?
值得注意的是,自主编码智能体的技术演进经历了三个明显阶段:第一阶段是以GitHub Copilot早期版本为代表的"代码补全"模式,基于Codex模型提供行级或函数级补全;第二阶段是"对话式编程",开发者通过自然语言描述需求,模型生成完整代码片段;第三阶段则是当前的"自主Agent"模式,系统能够自主规划任务、调用工具(如终端、浏览器、代码搜索)、执行多步骤操作并提交完整PR。Devin是第三阶段的典型代表,其核心架构包含任务规划器、工具调用模块和自我反思机制,能够在沙箱环境中独立完成从需求理解到代码提交的全流程。这种能力跃迁使得评估框架也必须从"代码片段质量"升级到"软件工程全生命周期贡献质量"。
来自MSR 2026的一项最新研究给出了迄今为止最系统的回答。Rezvan Mihai Popescu团队收集了11万条开源PR数据,覆盖5款主流编码智能体,不仅横向对比了当下的贡献差异,还纵向追踪了代码的长期演化。结论颠覆了不少人的认知。
研究设计:六层递进的严谨框架
这项研究的实验设计堪称教科书级别,整个框架分为六层逐层递进:
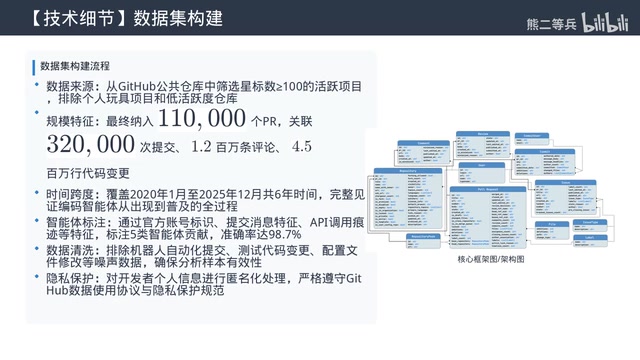
- 数据采集层:从主流开源平台爬取PR提交记录、评论、评审、Issue及文件变更数据
- 智能体识别层:通过提交信息、账号特征、内容特征等多维度识别AI与人类提交
- 横向对比层:将不同智能体与人类开发者的各维度指标进行统计检验
- 纵向分析层:跟踪代码在1个月、3个月、半年、1年后的存活率和流失率
- 统计校验层:排除项目活跃度、开发者经验等干扰变量
- 结论输出层:基于严格控制变量后的结果得出结论
最值得称道的是控制变量做得非常到位。对照组选择的是有多年开源贡献经验的资深开发者,而非新手,避免了"拿AI和新手比"的常见陷阱。
5款AI编码Agent与评估维度
对比的5款编码智能体包括:OpenAI Codex/CL、Claude Code、GitHub Copilot、Google Gemini和Devin。评估维度覆盖六项核心指标:PR合并率、变更规模、文件类型偏好、开发者互动信号、短期流失率(3个月)和长期存活率(1年)。
横向对比:合并率与行为模式差异显著
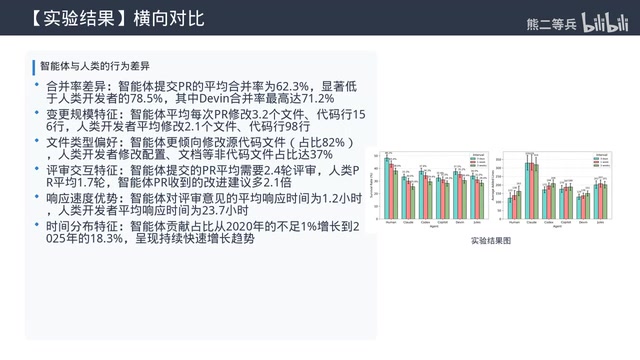
PR合并率:Copilot领先,Devin垫底
Pull Request(PR)合并率是开源社区中衡量代码贡献质量的核心代理指标(Proxy Metric)。一个PR从提交到合并需要经过代码评审(Code Review)、CI/CD自动化测试、维护者人工审核等多道关卡,因此合并率天然整合了代码正确性、风格一致性、需求匹配度等多个维度的信号。本研究通过控制项目活跃度变量,在一定程度上缓解了不同项目合并标准差异带来的偏差。
不同智能体的PR合并率差异明显。GitHub Copilot的合并率最高,约60%,与资深人类开发者基本持平;而Devin的合并率不到40%。这与两者的设计定位有关——Copilot本质是辅助工具,人类写主体代码它补充一部分,人类开发者在提交前已对Copilot生成的代码进行了筛选和修改,相当于在提交前完成了一轮人工过滤,所以合并率高;Devin主打自主完成完整任务,PR复杂度更高,合并率自然偏低。
变更规模:AI偏爱小改动
智能体提交的PR平均变更规模明显小于人类,大多是几十行的小改动。人类开发者的PR则经常包含几百行甚至上千行的功能提交。
文件类型偏好:AI更擅长"外围"工作
智能体普遍更倾向于修改文档、配置文件、测试用例等非核心代码文件,而人类开发者更多修改核心业务逻辑和架构相关代码。
评审互动:AI代码需要更多审查
智能体提交的PR平均收到的评论和评审意见比人类多约30%,说明人类评审者在检查AI代码时会更加谨慎。原因之一是智能体写的代码与项目原有风格的匹配度较低。
另一个值得注意的发现是:智能体PR的Issue解决率明显低于人类。虽然PR能通过评审,但并没有完全解决对应的需求,后续还需要人类补充修改。
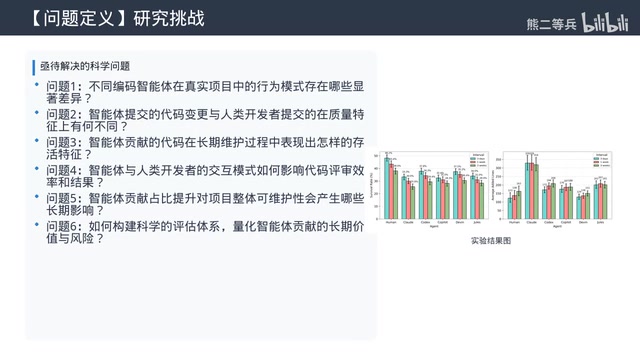
纵向追踪:AI代码的长期维护性令人担忧
如果说横向对比揭示的是当下差异,纵向追踪的结果则更值得警惕。
短期流失率:AI代码高出40%
PR合并后3个月内,智能体生成代码的流失率(被修改、重构或删除的比例)平均比人类高出40%。具体数据:人类代码的3个月流失率约25%,智能体平均达到35%,部分甚至超过40%。
长期存活率:一半AI代码活不过一年
代码存活率(Code Survival Rate)是软件演化研究领域的经典指标,通常基于Git blame分析测量——通过比对不同时间点的代码归属,统计某次提交的代码在后续版本中被保留的比例。存活率低意味着代码被频繁重构或删除,在工程实践中直接对应技术债务(Technical Debt)的积累。技术债务的概念由Ward Cunningham于1992年提出,描述为"为了短期交付速度而牺牲代码质量所产生的隐性成本"。
提交一年后,人类资深开发者写的代码约70%仍保留在项目中,而智能体生成代码的存活率平均只有50%左右,最低的甚至不到40%。若将后续维护和重构的隐性成本纳入ROI计算,AI编码工具的实际效益将大幅缩水,这对企业制定AI工具采购和使用策略具有直接的财务意义。
更关键的发现是:越是核心模块,智能体的存活率越低。核心业务逻辑代码中,人类的一年存活率能到80%,智能体只有30%多。反而是文档、配置文件等非核心部分,智能体的存活率与人类差不多。
这意味着:当时用AI写代码可能省了几天时间,但后续重构、改Bug花的时间反而更多,算总账可能并不划算。
深层原因:为什么AI代码"活不长"?
研究团队总结了六个核心原因:
- 上下文理解有限:当前主流LLM的上下文窗口已从早期的4K Token扩展至128K甚至200K Token,但大型生产级代码库的规模往往远超这一限制。更深层的挑战在于,代码理解不仅是文本理解,还涉及调用图(Call Graph)、数据流图(Data Flow Graph)、模块依赖关系等结构化知识,而这些信息难以被简单地"塞入"上下文窗口。核心模块往往与整个系统的历史演化深度耦合,这些"隐性知识"无法通过当前的上下文机制完整传递给模型。
- 目标函数偏差:训练目标侧重"写对当下的代码",而非长期可维护性和扩展性
- 隐性错误难以发现:AI代码有时藏着隐蔽错误,当下测试测不出来,线上运行一段时间才暴露
- 缺乏领域知识:行业特定的业务逻辑和"潜规则",AI缺乏足够的训练数据
- 创造力不足:遇到需要创新设计的场景(如新架构方案),不如人类开发者
- 沟通能力缺失:无法像人类一样在编码前与产品、同事沟通需求细节,只能依赖书面文档
实践启示:如何科学地使用AI编码工具
基于这项研究,开发团队可以从三个层面优化AI编码工具的使用策略:
建立差异化的代码评审标准
不要用和人类完全一样的标准评审AI代码。对于AI写的核心模块代码,要做更严格的检查,重点关注逻辑正确性、架构适配性和长期可维护性。
基于各工具优势合理分配任务
把改文档、写测试用例、改配置文件等AI擅长且流失率影响小的任务交给AI;核心业务逻辑、架构设计仍交给人类开发者,效率最高也最稳妥。当前RAG(检索增强生成)、代码图谱嵌入(Code Graph Embedding)等技术虽在一定程度上扩展了AI的代码理解能力,但在捕捉跨文件隐式依赖和历史设计决策方面仍存在明显短板,因此核心模块的人工主导仍是当前阶段的最优策略。
建立AI代码的长期监控机制
不要只看提交时有没有问题,要持续跟踪AI生成代码的流失率和Bug率。如果发现某类任务用AI后维护成本反而升高,就及时调整策略,避免为短期效率埋下技术债务。
总结
这项研究最大的价值在于,它没有停留在"AI能不能写代码"的表层问题,而是将视角延伸到了软件工程的完整生命周期。11万条PR的实证数据告诉我们:AI是很好的辅助工具,但核心代码的长期质量仍然需要人类把关。在AI编码工具日益普及的今天,理性认识其优势与局限,才能真正实现效益最大化。
核心要点
- 研究覆盖11万条PR数据和5款主流编码智能体,是目前该方向规模最大的实证研究之一
- GitHub Copilot合并率最高(约60%),与资深人类开发者持平;Devin合并率不到40%
- AI生成代码的3个月流失率比人类高40%,一年存活率仅约50%,核心模块存活率更低至30%
- 智能体更擅长修改文档、配置文件等非核心代码,核心业务逻辑仍需人类开发者主导
- 建议团队建立AI代码差异化评审标准、基于优势分配任务、并建立长期代码质量监控机制
相关推荐
 前沿研究
前沿研究纽约中央公园发现新物种?城市昆虫猎捕计划揭秘
科学家在纽约中央公园和布鲁克林展望公园设置昆虫捕集器,试图在城市环境中发现未知物种。地球90%物种尚未被命名,城市生物多样性研究正成为生态学新趋势。
 前沿研究
前沿研究希格斯玻色子发现始末:亲历者讲述「上帝粒子」背后的故事
费米实验室物理学家亲历讲述希格斯玻色子发现全过程:费米实验室与CERN的跨大西洋竞赛、2012年历史性宣布的幕后细节、从发现到验证的14年科学历程,以及「上帝粒子」名号的真实由来。
 前沿研究
前沿研究SciMDR:7B小模型如何在科研推理上比肩GPT-5
耶鲁大学等机构推出SciMDR框架,通过两阶段数据合成流水线,让70亿参数小模型在科研文献阅读理解上达到接近GPT-5水平。本文详解其降维构建与升维重塑的核心技术原理及实验结果。