AI Agent教程合集:多智能体、记忆与推理全覆盖
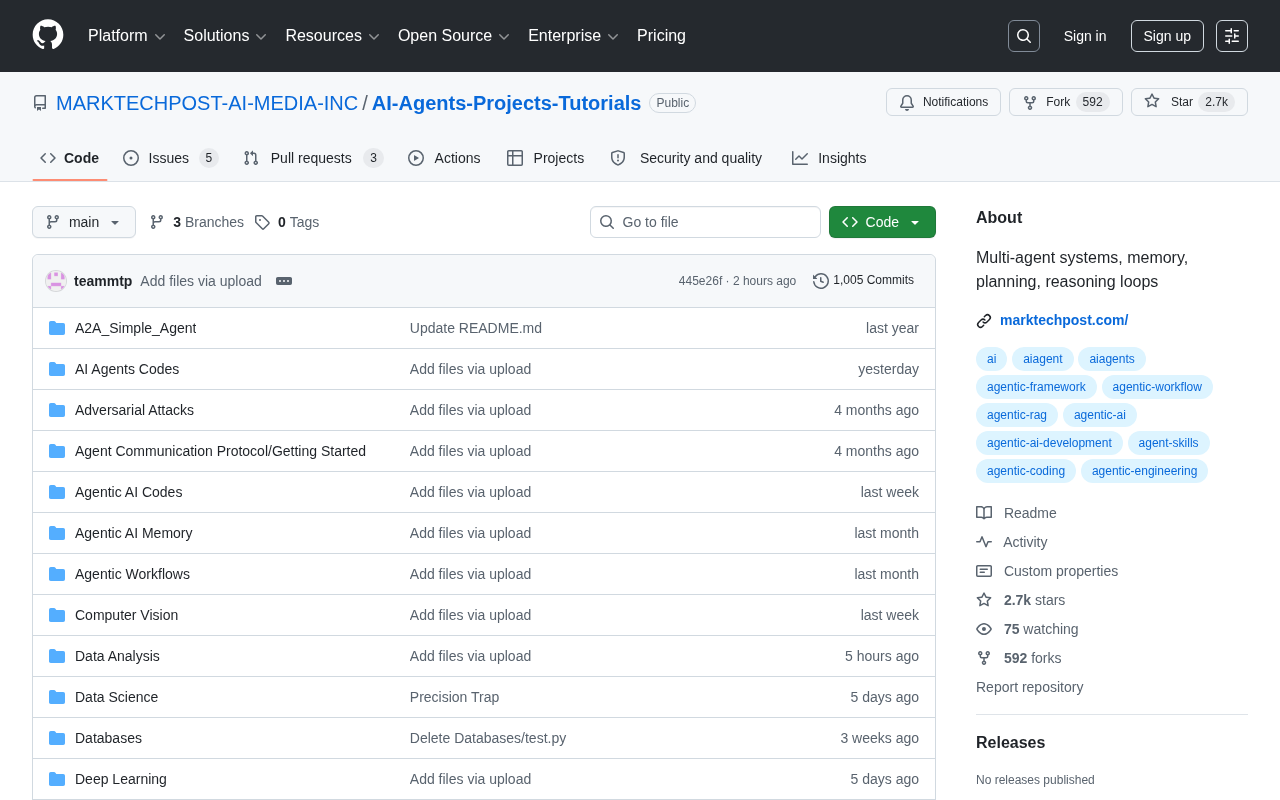
项目概览
在AI Agent开发领域,优质的学习资源往往分散在各处,开发者需要花费大量时间搜集和筛选。GitHub上由MarkTechPost(知名AI媒体)维护的开源项目 AI-Agents-Projects-Tutorials 正在改变这一现状。该项目已获得超过2690颗Star和590次Fork,成为AI Agent学习领域的热门资源库。
MarkTechPost成立于2017年,是一家专注于机器学习、深度学习和数据科学领域的在线媒体平台。与偏学术的arXiv或偏产业的TechCrunch不同,MarkTechPost定位于"让前沿AI研究对更广泛的技术社区可及",其内容风格介于论文解读和工程实践之间。该媒体在社交平台上拥有数十万关注者,由其维护的教程项目意味着内容经过了专业编辑团队的筛选和审核,相比个人开发者的零散教程,在系统性和准确性方面更有保障。
项目以Jupyter Notebook为主要载体,系统性地覆盖了AI Agent开发的核心主题:多智能体系统(Multi-agent Systems)、记忆机制(Memory)、规划能力(Planning)以及推理循环(Reasoning Loops)。这四大模块恰好构成了当前AI Agent技术栈的关键支柱。
Jupyter Notebook作为教学载体有其独特优势——它最初诞生于科学计算领域(前身为IPython Notebook),如今已成为数据科学和AI领域的标准工具。其核心价值在于将代码、运行结果、可视化图表和Markdown文本融合在同一个文档中,形成"文学编程"(Literate Programming)的范式。这一概念由计算机科学家Donald Knuth于1984年提出,核心理念是程序应该像文学作品一样,以人类可读的叙事方式组织,而非仅仅面向机器编译。Jupyter Notebook继承了这一思想,其名称本身就致敬了三大科学计算语言(Julia、Python、R)。对于AI Agent教学而言,Notebook允许学习者逐个Cell执行代码,实时观察Agent的推理过程、工具调用和输出变化,这种即时反馈机制远比阅读静态代码仓库高效。学习者可以在一个Cell中定义Agent的系统提示词,在下一个Cell中观察其推理输出,再在后续Cell中修改参数重新运行,这种交互式探索方式与Agent本身的迭代推理过程形成了有趣的呼应。此外,Google Colab等云端Notebook服务让学习者无需配置本地环境即可运行教程,进一步降低了入门门槛。
四大核心模块解析
多智能体系统(Multi-agent Systems)
多智能体系统是当前AI Agent领域最受关注的方向之一。与单一Agent相比,多智能体架构允许多个具有不同角色和能力的Agent协同工作,共同完成复杂任务。这一模块的教程涵盖了Agent间的通信协议、任务分配策略、冲突解决机制等核心概念。
在通信协议设计层面,当前主流框架采用了不同的通信范式:基于消息传递的模式(如AutoGen的对话式通信)、基于共享状态的模式(如LangGraph的状态图)、以及基于黑板系统的模式(多个Agent读写共享的信息空间)。在编排层面,存在两种主要架构——集中式编排(由一个"编排者"Agent统一调度其他Agent)和去中心化编排(Agent之间点对点协商)。集中式编排更易于调试和控制,但存在单点瓶颈;去中心化编排更灵活但可能导致协调混乱。实际生产环境中,混合架构往往是最佳选择。
从AutoGen到CrewAI,从LangGraph到MetaGPT,多智能体框架经历了爆发式增长。这一轮爆发始于2023年下半年:微软推出的AutoGen率先提出了"可对话Agent"的概念,允许多个Agent通过自然语言消息进行协作;CrewAI则引入了"角色扮演"机制,让每个Agent拥有明确的职责定义(如研究员、写手、审核员);LangGraph基于LangChain生态,以有向图的方式定义Agent间的工作流,提供了更精细的流程控制能力;MetaGPT则模拟软件公司的组织架构,让Agent分别扮演产品经理、架构师、程序员等角色协同完成软件开发。这些框架各有侧重,但共同推动了多智能体系统从学术研究走向工程实践。该项目将这些前沿实践以可运行的Notebook形式呈现,大幅降低了入门门槛。
记忆机制(Memory)
记忆是让AI Agent从"无状态工具"进化为"有上下文意识的助手"的关键能力。一个没有记忆的Agent每次交互都从零开始,而具备记忆能力的Agent可以:
- 短期记忆:在单次对话中维持上下文连贯性
- 长期记忆:跨会话保留用户偏好和历史信息
- 工作记忆:在复杂推理过程中暂存中间结果
记忆机制的实现通常涉及向量数据库、摘要压缩、检索增强等技术,这些都是Agent开发中的实战难点。其中,向量数据库是记忆机制的基础设施。其核心原理是将文本、对话历史等非结构化数据通过Embedding模型转化为高维向量,然后存储在专门优化了相似性搜索的数据库中。当Agent需要回忆相关信息时,通过向量相似度检索(如余弦相似度或近似最近邻搜索ANN)快速找到最相关的历史记录。
近似最近邻搜索(ANN)是向量数据库的核心算法。精确的最近邻搜索在高维空间中面临"维度灾难"——随着维度增加,计算复杂度呈指数增长。ANN算法通过牺牲少量精度换取数量级的速度提升。主流算法包括HNSW(Hierarchical Navigable Small World,构建多层图结构进行快速导航)、IVF(Inverted File Index,先聚类再在候选簇内搜索)和PQ(Product Quantization,将高维向量压缩为低维编码)。不同的向量数据库选择了不同的算法组合:Pinecone和Qdrant主要使用HNSW,Milvus支持多种索引类型的灵活切换。对于Agent的记忆系统而言,检索延迟直接影响响应速度,因此ANN算法的选择和参数调优是重要的工程考量。
主流的向量数据库包括Pinecone、Weaviate、Qdrant、ChromaDB和Milvus等。在实际Agent开发中,记忆的实现远不止简单存取——还需要设计记忆的过期策略、重要性评分、摘要压缩(将冗长的对话历史压缩为关键信息)以及记忆的层级组织,这些工程细节直接影响Agent的响应质量和推理效率。
规划能力(Planning)
规划是Agent处理复杂任务的核心能力。当面对一个多步骤任务时,Agent需要将其分解为可执行的子任务序列,并动态调整执行计划。常见的规划策略包括:
- 任务分解(Task Decomposition):将大目标拆解为小步骤
- 反思与修正(Reflection & Refinement):根据执行反馈调整计划
- 工具选择(Tool Selection):为每个子任务选择最合适的工具
这一模块对于构建能够自主完成端到端任务的Agent至关重要。值得注意的是,规划能力的研究深受经典AI中自动规划(Automated Planning)领域的影响。STRIPS(Stanford Research Institute Problem Solver)是1971年提出的经典自动规划系统,它将世界状态表示为一组逻辑谓词,通过前置条件和效果定义动作,使用搜索算法找到从初始状态到目标状态的动作序列。HTN(层次任务网络)则进一步引入了任务的层次分解——将高层抽象任务递归分解为具体可执行的原子操作,这与当前LLM Agent中的任务分解策略高度相似。
然而,经典规划要求完全形式化的状态和动作定义,而LLM驱动的规划则利用自然语言的灵活性处理开放域任务。这种灵活性是优势也是挑战——LLM可能生成不可行的计划或遗漏关键步骤,因此现代Agent框架通常结合形式化验证和LLM生成,在灵活性与可靠性之间寻找平衡。当前LLM Agent的规划方法本质上是将这些经典思想与大语言模型的自然语言理解能力相结合,使Agent能够在开放域任务中进行灵活的计划生成与调整。
推理循环(Reasoning Loops)
推理循环是Agent的"思维引擎"。经典的ReAct(Reasoning + Acting)范式让Agent在"思考-行动-观察"的循环中逐步逼近目标。
ReAct范式源自2022年普林斯顿大学和Google Brain联合发表的论文《ReAct: Synergizing Reasoning and Acting in Language Models》。该论文的核心洞察是:单纯的思维链推理(Chain-of-Thought)缺乏与外部世界交互的能力,而单纯的行动执行又缺乏推理指导。ReAct将两者交织在一起,形成"Thought → Action → Observation"的循环:Agent先思考当前应该做什么(Thought),然后执行具体操作如调用API或搜索(Action),再观察执行结果(Observation),基于观察继续下一轮思考。这一范式深刻影响了后续几乎所有Agent框架的设计,LangChain的Agent模块、AutoGPT的执行循环等都以ReAct为理论基础。
更先进的推理模式还包括:
- Chain-of-Thought:逐步推理,提升复杂问题的解决能力
- Tree-of-Thought:探索多条推理路径,选择最优方案
- Self-Reflection:Agent对自身输出进行批判性评估
Tree-of-Thought(ToT)由普林斯顿大学于2023年提出,是对线性Chain-of-Thought的重要扩展。传统CoT沿单一路径推理,一旦中间步骤出错就会导致最终结果偏差。ToT则将推理过程建模为一棵搜索树,在每个决策节点生成多个候选思路,通过评估函数(可以是LLM自身的判断)对各分支进行打分,然后采用广度优先搜索(BFS)或深度优先搜索(DFS)策略探索最有前景的路径。这种方法在需要前瞻性规划的任务(如数学证明、创意写作、策略游戏)中表现显著优于线性推理。
Self-Reflection则让Agent充当自己的"评审员",对已生成的输出进行批判性审视并迭代改进。其代表性实现Reflexion框架由Shinn等人于2023年提出,核心机制是为Agent引入三种记忆:短期记忆(当前任务的轨迹)、长期记忆(跨任务的经验积累)和自我反思记忆(对失败原因的语言化总结)。当Agent在任务中失败时,它不是简单地重试,而是先生成一段自然语言的反思(如"我在第三步选择了错误的API,因为我没有注意到参数类型要求"),将这段反思存入记忆,在下次尝试时作为额外上下文参考。实验表明,Reflexion在编程任务(HumanEval)、决策任务(AlfWorld)和推理任务上都显著优于无反思的基线方法,展示了语言化自我反馈作为学习信号的强大潜力。
推理循环的设计直接决定了Agent的智能水平和可靠性。
项目价值与适用人群
为什么这个项目值得关注
该项目的独特价值在于其系统性和实践性的结合。市面上不缺AI Agent的理论文章,但缺少将理论转化为可运行代码的教程集合。以Jupyter Notebook为载体意味着开发者可以逐步执行、修改参数、观察结果,真正做到"边学边练"。
此外,MarkTechPost作为专业AI媒体的背书,确保了内容的质量和时效性。项目持续更新,能够跟上AI Agent领域快速迭代的节奏。在当前Agent技术日新月异的背景下——从2024年初OpenAI推出GPTs和Assistants API,到Anthropic发布Claude的Tool Use能力,再到Google的Gemini Agent生态布局——保持教程内容的时效性尤为重要。
这背后是一场围绕"Agent平台化"的激烈竞争。OpenAI的Assistants API提供了内置的代码解释器、文件检索和函数调用能力,试图成为Agent开发的一站式平台;Anthropic的Claude Tool Use则以更精确的工具调用和更长的上下文窗口为卖点,在复杂Agent任务中表现突出;Google的Gemini则凭借多模态能力(原生支持文本、图像、视频、代码)和与Google生态(搜索、地图、日历等)的深度整合,提供了差异化的Agent能力。此外,开源阵营也不容忽视——Meta的Llama系列、Mistral等开源模型正在快速缩小与闭源模型在Agent能力上的差距,为开发者提供了更灵活、更低成本的选择。一个持续维护的开源教程库能够帮助开发者及时掌握最新的API变化和最佳实践,在这场平台竞争中保持技术敏锐度。
适合谁学习
- AI开发者:希望从零构建Agent系统的工程师
- 研究人员:需要快速复现和验证Agent架构的学者
- 技术管理者:想要理解Agent技术全貌以做出技术决策的团队负责人
- AI爱好者:对Agent技术感兴趣、有一定Python基础的学习者
推荐学习路径
项目托管在GitHub上,可以直接克隆到本地运行。建议按照以下路径循序渐进:
- 先从推理循环(Reasoning Loops)入手,理解Agent的基本运行机制
- 学习记忆机制,让Agent具备上下文感知能力
- 掌握规划模块,构建能处理复杂任务的Agent
- 最后进入多智能体系统,学习Agent间的协作与编排
这一学习路径的设计逻辑遵循了"从单体到系统"的渐进原则:推理循环是单个Agent的核心运行机制,记忆和规划是增强单个Agent能力的关键模块,而多智能体系统则是将多个能力完备的Agent组合成更强大系统的终极形态。每一层的知识都是下一层的基础,跳过前置模块直接学习多智能体系统往往会导致对底层机制理解不足。
在AI Agent从概念走向落地的关键阶段,这样一个结构化的学习资源库无疑是开发者的有力武器。无论你是刚入门还是希望深化理解,都值得将这个项目加入你的学习清单。
核心要点
相关推荐
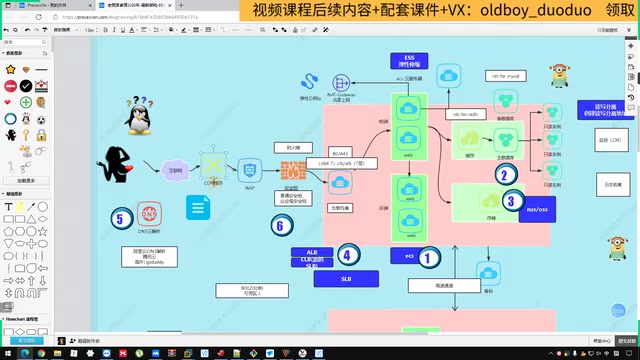
阿里云网站架构全解析:从DNS到弹性伸缩的完整链路
系统梳理阿里云网站架构核心组件,按用户请求流向详解DNS云解析、CDN、WAF防火墙、CLB/ALB负载均衡、ECS云服务器、Redis缓存、NAS/OSS存储及弹性伸缩等服务的作用与协作关系,帮助初学者建立完整的云架构认知体系。
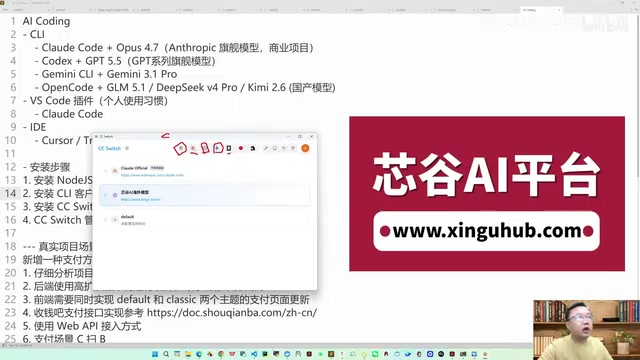
Claude Code实战:60美元4小时完成复杂支付系统二开
通过真实商业案例详解Claude Code + Opus 4.7如何在4小时内完成复杂支付系统二开,涵盖CC Switch配置、Prompt工程技巧、模型选择策略及AI Coding工程化落地方法论。

Vibe Coding入门指南:零基础用AI写代码的完整攻略
Vibe Coding(氛围编程)让零基础用户通过自然语言指令实现软件开发。本文详解Vibe Coding的核心概念、适用场景、推荐工具及实践步骤,帮你快速上手AI编程。