阿里QwQ-32B开源:32B参数如何媲美671B的DeepSeek R1
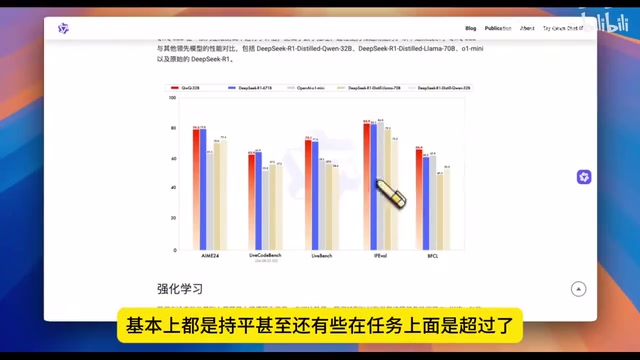
阿里QwQ-32B以32B参数通过两阶段强化学习达到671B参数模型的性能水平
阿里开源推理模型QwQ-32B仅用32B参数,在多项基准测试中媲美甚至超越671B参数的DeepSeek R1。其核心在于两阶段强化学习训练策略:先在可精确验证的数学和编程任务上建立推理基础,再扩展到通用领域。强化学习还展现出不会导致灾难性遗忘、反而能协同提升多项能力的优势。该模型可在消费级显卡上本地部署,大幅降低了高性能推理模型的使用门槛。
阿里近日发布了全新开源推理模型QwQ-32B,仅用DeepSeek R1满血版约二十分之一的参数量,就在多项基准测试中达到甚至超越了后者的表现。这一成果背后的训练策略虽然只用了一篇227字的博客来阐述,但其中蕴含的技术路线值得深入解读。
QwQ-32B性能对比:32B vs 671B,以小博大
QwQ-32B最令人震撼的地方在于它的参数效率。DeepSeek R1满血版拥有671B参数,而QwQ-32B仅有32B参数——不到前者的5%。然而在各项主流基准测试中,两者的表现几乎持平,部分任务上QwQ-32B甚至实现了反超。
在大语言模型领域,参数量(Parameters)是衡量模型规模的核心指标。参数本质上是神经网络中可学习的权重数值,参数越多,模型理论上能够捕捉的语言模式和知识就越丰富。671B意味着6710亿个参数,32B则是320亿个参数。传统观点认为,参数量与模型能力之间存在近似线性的正相关关系——这就是OpenAI在2020年提出的"Scaling Law"(缩放定律)。然而QwQ-32B的出现正在挑战这一认知,说明在训练方法足够先进的情况下,缩放定律的边界可以被大幅突破。值得注意的是,DeepSeek R1采用的是MoE(Mixture of Experts,混合专家)架构,虽然总参数量为671B,但每次推理时实际激活的参数量远小于此,大约在37B左右。即便如此,QwQ-32B用更小的总参数量达到相近性能,仍然是一项显著的效率突破。
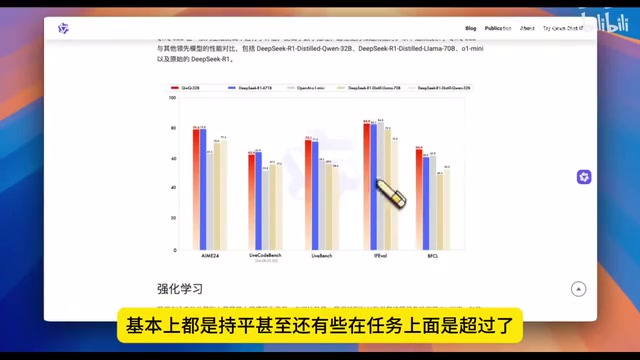
从官方公布的性能报告来看,在LiveBench等代码相关任务上,QwQ-32B超过DeepSeek R1约两个百分点。LiveBench是一个相对较新的大模型评估基准,其核心特点是使用持续更新的、未被模型训练数据污染的测试题目。传统基准测试(如MMLU、HumanEval等)由于题目固定且公开,存在被模型"记忆"答案的风险——即所谓的数据污染(Data Contamination)问题。LiveBench通过定期从最新的数学竞赛、编程挑战、学术论文等来源抽取题目,确保评估结果能真实反映模型的推理能力而非记忆能力。QwQ-32B在这类"防作弊"基准上的优异表现,更能说明其推理能力的真实性和泛化性。
与OpenAI的O1模型相比,QwQ-32B同样展现出了极强的竞争力。这意味着一个可以在消费级显卡上本地部署的模型,已经具备了与顶级闭源大模型掰手腕的实力。
这种"以小博大"的能力,核心在于数据质量和训练策略的突破,而非单纯的参数堆叠。
训练策略解析:两阶段强化学习是关键
虽然阿里没有发布正式论文,但从博客中可以提炼出清晰的两阶段训练路线。
强化学习(Reinforcement Learning, RL)是机器学习的三大范式之一,与监督学习和无监督学习并列。在传统的大模型训练流程中,通常分为预训练(Pre-training)和监督微调(Supervised Fine-Tuning, SFT)两个阶段,随后可能加入RLHF(基于人类反馈的强化学习)来对齐人类偏好。而QwQ-32B所采用的策略更进一步,将强化学习提升为核心训练手段而非仅仅是对齐工具。具体来说,强化学习的核心机制是:智能体(模型)在环境中采取行动,根据获得的奖励信号不断调整策略。在推理模型的训练中,模型尝试解决问题,如果答案正确就获得正向奖励,错误则获得负向奖励,通过大量试错来优化推理策略。这与DeepSeek R1的训练思路一脉相承,后者也大量使用了GRPO(Group Relative Policy Optimization)等强化学习算法。
第一阶段:数学与编程任务的强化学习
QwQ-32B的训练首先从数学和编程两大领域切入,进行大规模强化学习。选择这两个领域有一个关键原因:它们的答案可以被精确量化验证。

数学任务中,1加1就等于2,不会等于3——答案是确定的,模型可以通过已知答案进行反向推理训练。编程任务同理,代码写出来能不能通过测试用例,跑一下就知道了。这种天然的可验证性意味着不需要额外的奖励模型或人工标注,就能高效地判断模型推理是否正确。
在强化学习训练中,奖励信号(Reward Signal)的质量直接决定了训练效果。数学和编程任务之所以被优先选择,正是因为它们属于"可形式化验证"的任务类型。数学问题可以通过符号计算或数值比对来判断对错;编程任务则可以通过自动化测试套件(Test Suite)来验证代码的正确性——这在软件工程中被称为"单元测试"。这种自动化验证机制使得训练过程可以完全摆脱对人工标注的依赖,实现所谓的"自我博弈"式学习。相比之下,如果直接在写作或对话等开放性任务上进行强化学习,就必须依赖另一个模型(即奖励模型)来提供评分,而奖励模型本身的偏差会引入"奖励黑客"(Reward Hacking)问题——模型学会了讨好评委而非真正提升能力。因此,先在可验证任务上建立扎实的推理基础,是一种非常聪明的课程设计策略。
通过在这两类任务上的大量强化学习训练,模型的逻辑推理能力得到了根本性的提升。这也是QwQ-32B能在小参数量下展现出强大推理能力的核心原因。
第二阶段:通用能力的强化学习扩展
在第一阶段打好推理基础后,训练进入第二阶段——引入通用领域的强化学习。这一阶段使用了两种验证机制:
通用奖励模型(Reward Model): 对于写作、对话等难以量化的任务,阿里训练了专门的奖励模型来评判输出质量。比如让模型写一篇文章,文章好不好很难用规则判断,这时就需要另一个模型来充当"评委"。奖励模型通常基于人类偏好数据训练而成——标注员对模型的多个输出进行排序,奖励模型学习这种偏好排序后,就能对新的输出给出质量评分。这种方法虽然不如数学验证那样精确,但为开放性任务的强化学习训练提供了可行的优化方向。
基于规则的验证器: 用于检验模型输出的格式规范性。推理模型通常需要分两个阶段输出——thinking标签中的思考过程和solution中的最终答案。此外,当要求模型以JSON等特定格式输出时,规则验证器可以直接判断格式是否合规。这种结构化输出能力对于模型在实际应用中的可靠性至关重要,尤其是在需要与其他系统进行数据交互的场景中。
强化学习的"涌现"优势:能力不降反升
训练过程中,阿里团队发现了一个极具价值的现象:强化学习不会导致其他能力下降,反而会带来全面提升。
这与传统的模型微调(Fine-tuning)形成了鲜明对比。做过微调的从业者都知道,当你用特定领域数据微调模型时,模型在原始任务上的能力往往会下降几个百分点,这是一个普遍存在的"灾难性遗忘"问题。
灾难性遗忘(Catastrophic Forgetting)是神经网络领域一个长期存在的经典问题,最早在1989年由McCloskey和Cohen提出。当神经网络在新任务上进行训练时,网络权重的更新会覆盖之前学到的知识,导致旧任务的性能急剧下降。在大模型微调场景中,这个问题尤为突出:比如用大量医学数据微调一个通用模型后,模型的医学问答能力会显著提升,但写代码或做数学题的能力可能明显退化。业界为此发展了多种缓解方案,包括LoRA(低秩适配)、弹性权重巩固(EWC)、多任务联合训练等。
但在强化学习框架下,当团队加入通用领域的训练数据后,模型的其他能力不仅没有下降,还出现了协同提升的效果。比如写作能力的提升可能同时带动了聊天能力的增强。这可能是因为强化学习优化的是策略层面的决策能力,而非简单地拟合特定数据分布,因此对模型已有知识的破坏更小。这一发现对于未来模型训练的方向选择具有重要的指导意义——强化学习可能是比监督微调更优的能力扩展路径。
技术启示:小模型的大未来
从QwQ-32B的成功中,我们可以提炼出几个核心启示:
第一,参数量不是决定性因素。 32B参数能媲美671B参数的模型,说明在合理的训练策略下,小模型完全可以释放出巨大潜力。这对于本地部署和边缘计算场景意义重大。
第二,数据质量远比数据数量重要。 QwQ-32B的成功很大程度上归功于精心筛选的高质量训练数据和科学的训练流程设计,而非简单的数据堆砌。
第三,强化学习正在成为推理模型的核心训练范式。 从DeepSeek R1到QwQ-32B,强化学习在提升模型推理能力方面展现出了独特优势,尤其是在可验证任务上的自监督训练效率极高。
从实际部署角度来看,32B参数规模的模型在量化(Quantization)后,通常可以压缩到约16-20GB的显存占用。这意味着一张NVIDIA RTX 4090(24GB显存)就能运行该模型,而671B参数的模型即使采用MoE架构,完整部署也需要多张专业级GPU(如A100或H100),硬件成本动辄数十万元。量化是一种模型压缩技术,通过将模型权重从32位浮点数降低到8位甚至4位整数来减少内存占用和计算量,同时尽量保持模型性能。对于企业用户而言,本地部署意味着数据不需要发送到云端API,从根本上解决了数据隐私和安全合规问题。对于开发者和研究者而言,这大幅降低了实验和迭代的成本。QwQ-32B的开源许可(Apache 2.0)更进一步消除了商业使用的法律障碍。
阿里在博客末尾也提到,未来将继续整合强化学习能力,朝着通用人工智能的方向迈进。QwQ-32B的开源,不仅为社区提供了一个强大的本地可部署推理模型,更验证了一条高效的小模型训练路线,这或许会深刻影响接下来开源AI模型的发展方向。
核心要点
- 阿里QwQ-32B仅用32B参数就在多项基准测试中媲美甚至超越671B参数的DeepSeek R1满血版
- 训练采用分阶段强化学习策略:先用可精确验证的数学和编程任务打基础,再扩展到通用领域
- 强化学习相比传统微调的关键优势在于不会导致其他能力下降,反而能实现能力的协同提升
- 模型的成功再次证明数据质量和训练策略比单纯的参数规模更为重要
- 作为开源模型,QwQ-32B可在消费级显卡上本地部署,大幅降低了高性能推理模型的使用门槛
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。