Agent上下文腐烂的两种病因:Distraction与Poisoning详解

AI Agent上下文腐烂分为注意力稀释和因果链污染两种病因,需分别治理。
AI Agent对话中的「上下文腐烂」并非单一问题,而是两种不同故障:Distraction(注意力稀释)——信号被噪声淹没导致模型抓不准重点;Poisoning(因果链污染)——早期错误被反复引用强化为「事实」。前者通过压缩折叠、外部记忆、任务切片和工具卸载提升信噪比;后者需事实校验、Checkpoint、回滚甚至重开来切断错误链。稳定的Agent需要建立完整的上下文治理层,分别防御这两类问题。
很多人在使用 AI Agent 时都遇到过这样的场景:一开始对话还挺聪明,越聊越偏、越改越乱,最后开个新对话反而一下就对了。这到底是模型变笨了,还是上下文出了问题?
答案是后者。所谓的「上下文腐烂」(Context Rot)其实根本不是一种单一的病症,而是两种完全不同的故障模式——Distraction(注意力稀释) 和 Poisoning(因果链污染)。把这两种问题混为一谈,解决方案就一定会走偏。
Distraction:不是窗口不够大,而是注意力预算不够用
信号被噪声淹没
想象一下,一个 Agent 在处理任务时,前面堆积了大量的对话历史、工具返回结果、代码片段、中间日志……看起来信息很丰富,但真正有价值的信号早已被海量噪声淹没了。
这时模型并不是完全看不见关键信息,而是看得见却抓不准。于是你会观察到几个非常典型的症状:响应变慢、选择变飘、明明该抓重点却去引用次要信息、长期任务线慢慢断裂。
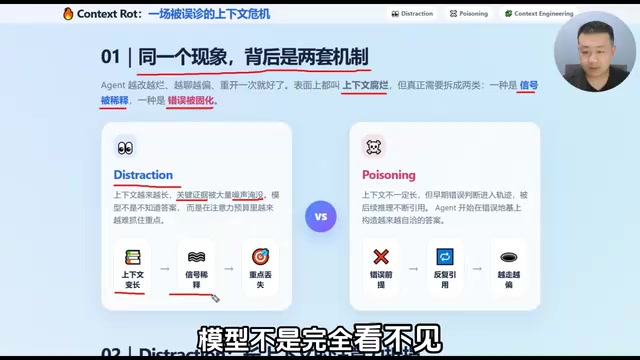
这与长上下文研究中的结论完全吻合——性能会随着输入 token 增长而持续下降,甚至很多时候还没到窗口上限,效果就已经开始掉了。Transformer 架构中的自注意力机制(Self-Attention)在理论上允许每个 token 关注序列中的所有其他 token,但实际计算中注意力权重的分配并非均匀的。随着输入序列变长,注意力权重被摊薄到更多 token 上,导致对关键信息的聚焦能力下降。Google 的「Lost in the Middle」研究(2023)明确指出,当关键信息被放置在长上下文的中间位置时,模型的检索和推理准确率会显著下降。这意味着即使模型标称支持 128K 甚至 1M token 的上下文窗口,其有效利用能力往往远低于这个数字,实际可靠工作的范围可能只有标称值的几分之一。模型的有效上下文窗口,往往远小于标称的最大 token 数。
三个字概括输出退化:慢、飘、断
从输入侧看,压力来源很明确:历史消息堆积、低价值 token 越来越多、关键信号被分散。输出侧则表现为:
- 慢——需要处理更多历史信息,推理延迟增加
- 飘——开始抓错重点,回答偏离核心问题
- 断——对长期目标的保持能力下降,任务线断裂
这本质上是一个工程问题,不是玄学问题。治理方向不是无限扩大上下文窗口,而是让上下文变得短、准、活。
四种治理手段解决注意力稀释
针对 Distraction 型的上下文腐烂,有一条清晰的治理线路:
- 压缩与折叠:把历史过程变成状态摘要,删掉重复的、过期的、低价值的内容,只保留当前决策真正需要的信息。
- 外部记忆:把长期资料、文档、日志放到上下文窗口之外,真正需要时再通过 RAG 检索拉回来。RAG(Retrieval-Augmented Generation,检索增强生成)的核心思路是不把所有信息塞进上下文窗口,而是在需要时通过向量检索从外部数据库中找到最相关的文档片段,再将这些片段注入当前的提示词中。典型的 RAG 流程包括文档分块(Chunking)、向量嵌入(Embedding)、相似度检索(Similarity Search)和上下文注入(Context Injection)四个步骤,确保上下文窗口中始终只包含与当前问题高度相关的信息。
- 任务切片:把一个大任务拆成多个小阶段,每一段只带局部目标、输入和验收标准。
- 工具卸载:计算、搜索、解析、校验这些事情交给专用工具完成,模型只消费结构化结果。
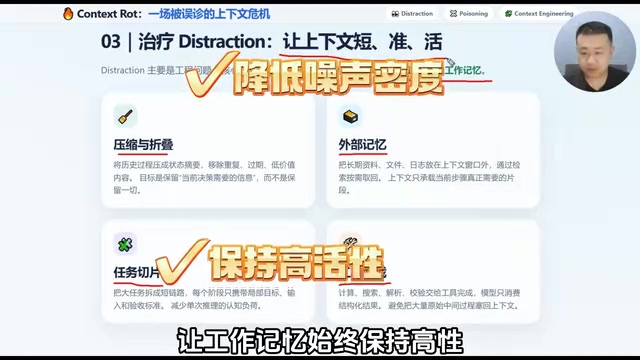
这几个方法本质上都在做同一件事:降低上下文里的噪声密度,让工作记忆始终保持高信噪比。这也是当前 Context Engineering 讨论中最核心的共识。值得一提的是,Context Engineering(上下文工程)与早期的 Prompt Engineering(提示词工程)有本质区别。Prompt Engineering 主要关注如何写好单次提示词——措辞、格式、Few-shot 示例等;而 Context Engineering 关注的是整个对话生命周期中上下文的动态管理,包括什么信息应该进入上下文、什么时候应该被压缩或移除、如何在多个 Agent 之间传递和隔离上下文等。Andrej Karpathy 等人将其类比为传统软件工程中的内存管理:Prompt Engineering 是写好一行代码,Context Engineering 是管理整个程序的运行时状态。
Poisoning:不是太长,而是信错了
比 Distraction 更危险的故障模式
Poisoning 的可怕之处在于,上下文长度可能根本没超标,但早期一个错误判断、一个误读、一个幻觉结果进入上下文后,被后续步骤不断引用,最终变成了「似乎大家都同意的前提」。
它不是在稀释信号,而是在污染因果链。
最开始可能只是一个小错误——比如把需求理解错了,或者把一个不可靠的工具结果当真了。但后面每一次引用、每一次总结、每一次继续推理,都会把这个错误再强化一遍。到最后,模型会在错误地基上构造出一个越来越自洽的答案:表面上逻辑很顺,实际上全是歪的。
这里需要特别理解大语言模型幻觉(Hallucination)在因果链污染中扮演的角色。幻觉是指模型生成看似合理但实际上不正确或无中生有的内容,其产生根源在于模型本质上是一个概率分布的采样器,它基于训练数据中的统计模式生成文本,而非基于事实推理。在多轮对话或多步推理的 Agent 场景中,幻觉的危害被成倍放大:一次幻觉产生的错误信息会被写入上下文,后续步骤将其视为已确认的事实继续引用和推理,形成所谓的「幻觉级联」(Hallucination Cascade)。这正是 Poisoning 最常见的触发源之一,也是为什么单纯依赖模型自身的「自我纠错」能力往往不够可靠的原因。
Poisoning 的四步演化过程
如果把因果链污染拆成过程来看,通常是四步:
- 错误进入上下文:可能是误读、错误假设、无效工具结果,也可能是模型自己产生的幻觉。
- 错误被当成锚点:后面的推理开始围着它转,不再主动复核。
- 错误被反复引用:引用次数一多,它就越来越像「事实」。
- 修复变难:你已经不是在修一个点,而是在修整条错误链。
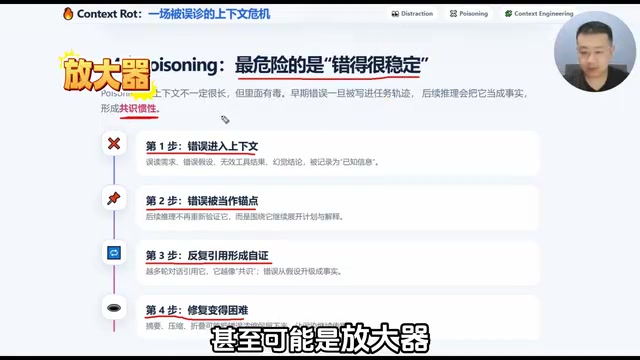
这里有一个反直觉的要点:针对 Poisoning,压缩上下文不一定是解药,甚至可能是放大器。因为摘要可能把毒性信息浓缩得更紧,带着它继续往下走。
切断错误因果链的四个关键操作
Poisoning 的处理原则很简单——不要在坏轨迹里死磕,要果断切断错误因果链:
- 事实校验:关键假设在进入主轨迹之前,先通过工具、规则或独立链路验证,不要让模型说过的话直接变成事实。
- Checkpoint:在关键决策点留下干净状态快照,后面一旦出错能回到可信版本。在传统软件工程中,Checkpoint(检查点)和回滚是数据库事务管理和分布式系统中的经典概念。在 Agent 系统中,Checkpoint 的实现通常是在关键决策节点保存当前的完整上下文状态——包括对话历史、已确认的事实、中间推理结果和任务进度。这一思路与 Git 版本控制中的分支和回退、数据库中的事务回滚(Rollback)在本质上是同构的,只是操作对象从代码或数据变成了 Agent 的推理状态。
- 回滚:一旦发现前提被污染,别继续在污染轨迹里做补丁式修复,直接退回到错误进入之前的状态。
- 重开:当污染源已经定位不清或污染太深时,最有效的办法往往就是清空上下文重新开始。
这个思路很朴素但极其重要:Poisoning 的修复不是把错误解释圆,而是把它从因果链里彻底切掉。
Sub-Agent:隔离仓还是新污染源?
很多人会觉得,把一个大任务拆给多个子 Agent(Sub-Agent),不就能把上下文拆短、把污染隔离了吗?没错,这确实是它的价值所在:
- 并行探索不同方向,独立搜索后只汇总结果和证据
- 任务隔离,让局部失败不污染主上下文
- 结构化交付,子任务只输出结果、依据和置信度
对 Distraction 来说,Sub-Agent 确实有帮助——它能缩短单个上下文的长度,降低单点复杂度。
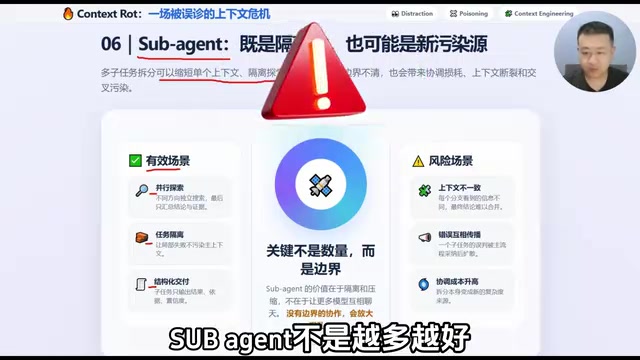
但问题也在这里:Sub-Agent 不是越多越好,关键是边界设计。Multi-Agent(多智能体)架构是当前 AI Agent 领域的主流设计模式之一,典型框架包括 AutoGen、CrewAI、LangGraph 等。在这种架构中,一个主 Agent(Orchestrator)负责任务分解和结果汇总,多个子 Agent 各自负责特定子任务。这种设计的核心挑战在于信息一致性和协调成本:每个子 Agent 拥有独立的上下文窗口,它们对同一问题可能形成不同甚至矛盾的理解;主 Agent 在合并结果时需要处理冲突、评估可信度、过滤低质量输出。如果协调协议设计不当,Multi-Agent 系统的整体表现可能反而不如单个 Agent——这就是所谓的「协调税」(Coordination Tax)问题。
具体来说,如果每个子 Agent 看到的信息不一致,最后就很难合并;如果一个分支的误判被主流程采纳,错误就会跨 Agent 扩散;如果拆分后协调成本太高,拆分本身就成了新的复杂度来源。
所以 Sub-Agent 既是隔离仓,也可能是新污染源。真正关键的不是有没有 Sub-Agent,而是边界清不清楚、输出干不干净、主流程能不能只消费结构化结果。
构建上下文治理层:完整的防御体系
把整张图串起来看,真正稳定的 Agent 靠的不是一个超长上下文窗口,而是一套上下文治理层。从上到下依次是:用户目标 → 任务规划 → 工作上下文 → 工具执行 → 结果交付。
围绕这条主链路,需要建立两层防线:
- 前面一层防 Distraction:用检索代替全文、用摘要代替流水账、用折叠代替堆叠、用工具结果代替原始过程,让工作上下文始终保持高信噪比。
- 后面一层防 Poisoning:对关键假设做事实校验、对风险结论做隔离、对关键步骤做 Checkpoint、对污染轨迹做回滚或重启。
前者解决「看不清」的问题,后者解决「信错了」的问题。前者靠上下文工程优化信噪比,后者靠轨迹管理切断错误传播。
你只要把 Distraction 和 Poisoning 这两种病因分开诊断,很多看起来很玄的 Agent 退化问题,其实就一下子变清楚了。
核心要点
- 上下文腐烂(Context Rot)本质上是两种不同故障:Distraction(注意力稀释)和 Poisoning(因果链污染),必须区分治理
- Distraction 的核心是信噪比问题,治理方向是压缩折叠、外部记忆、任务切片和工具卸载,让上下文保持短、准、活
- Poisoning 更为危险,一个早期错误会被反复引用强化为「事实」,压缩摘要反而可能放大毒性,需要通过事实校验、Checkpoint、回滚和重开来切断错误因果链
- Sub-Agent 对隔离 Distraction 有帮助,但边界不清时反而会成为新的污染源,关键在于输出结构化和主流程的消费方式
- 稳定的 Agent 需要一套完整的上下文治理层:前端防 Distraction 保信噪比,后端防 Poisoning 保因果链正确性
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。