Agent需要控制流,不是更多Prompt
构建AI Agent应用代码控制流而非超长Prompt来编排流程
文章指出AI Agent不可靠的根源在于将控制流写进自然语言Prompt,而非大模型能力不足。由于LLM的概率性本质和"Lost in the Middle"效应,超长Prompt会导致关键指令被稀释。正确做法是采用"控制流优先"架构:用代码定义状态机和流程编排,Prompt仅负责单一任务,可将多步骤可靠性从40%提升至90%以上。
一个反直觉的事实:Prompt越长,Agent越不可靠
很多开发者在构建AI Agent时,都会陷入一个误区——当Agent表现不佳时,第一反应是优化Prompt,加更多的条件判断、更详细的指令、更完善的示例。结果Prompt越写越长,Agent却越来越不稳定。
这不是你的问题,是架构错了。
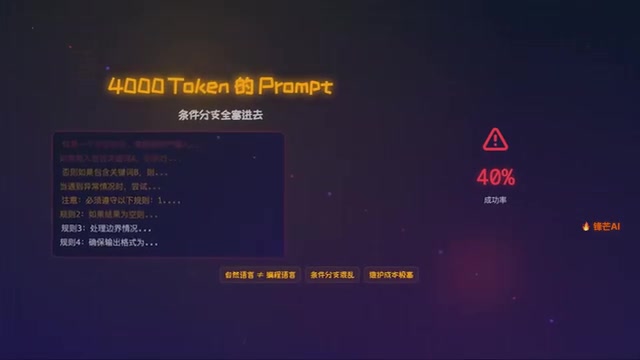
有团队为Agent编写了超过4000 token的Prompt,把所有条件分支、异常处理、流程控制全部塞进自然语言描述中,结果系统依然随机崩溃,表现极不稳定。问题的根源不在大模型的能力,而在于他们把控制流写进了自然语言——而自然语言,是一门极烂的编程语言。
自然语言为什么不适合做控制流
编程语言之所以存在,是因为它具备自然语言不具备的关键特性:确定性。一个 if-else 分支在代码中的行为是100%可预测的,而同样的逻辑用自然语言描述给大模型,每次执行的结果都可能不同。
这种不确定性有其深刻的技术根源。大型语言模型(LLM)的底层机制决定了其输出的概率性特征——LLM本质上是在做下一个token的概率预测,即便温度参数(Temperature)设为0,面对复杂的多步骤指令时,模型仍会受到注意力机制(Attention Mechanism)的影响。随着Prompt长度增加,模型对早期关键指令的"注意力权重"会被稀释,导致遗忘或误解。这一现象被研究者称为"Lost in the Middle"效应,在2023年斯坦福的研究中已被实验证实:当关键信息被埋在超长上下文的中间位置时,模型的检索准确率会显著下降。这正是4000 token的Prompt反而让Agent更不稳定的底层原因。
当我们在Prompt中写下"如果用户提到价格问题,先查询数据库,然后生成对比报告,如果查询失败则返回默认值"这样的指令时,我们实际上是在用一种模糊的、概率性的媒介来表达一种需要精确执行的逻辑。大模型可能会:
- 跳过某个步骤
- 错误理解条件判断的边界
- 在多步骤任务中丢失上下文
- 对"失败"的定义产生歧义
这些问题不会随着模型能力的提升而彻底消失,因为这是自然语言本身的固有局限。
真正的解法:控制流优先架构
真正的解决方案是一次范式转变——控制流优先(Control Flow First)。核心思想很简单:把大模型当作函数调用,用代码来定义状态机、循环和错误处理,Prompt只负责单一、明确的任务。

具体怎么做?
以一个常见的数据分析Agent为例,任务是"提取数据→查询数据库→生成报告"。
Prompt优先方案:用一条超长指令把整个流程串起来,让大模型自行决定每一步的执行。实测成功率不到40%。
控制流优先方案:用有向图定义整个流程,每个节点对应一个编排好的步骤,每一步都有类型检查和重试逻辑。大模型只在每个节点内完成单一任务(比如"从这段文本中提取日期和金额"),流程的推进、分支、异常处理全部由代码控制。
这里的"有向图"并非抽象概念,而是软件工程中处理复杂流程的经典工具——有向无环图(DAG)和状态机(State Machine)。状态机明确定义了系统在任意时刻所处的"状态"以及触发状态转移的"事件",这种确定性正是自然语言所缺乏的。LangGraph框架正是将这一思想引入Agent编排:每个节点代表一个原子操作,边代表条件转移,整个Agent的执行路径在代码层面完全可追踪、可调试、可回滚,彻底消除了"大模型自行决策流程"带来的不确定性。

效果对比
这种架构转变带来的提升是显著的:
- 单步任务成本降低80倍:因为每个Prompt变得极其简短和聚焦,token消耗大幅下降
- 多步骤可靠性从40%飙升到90%以上:因为流程控制不再依赖大模型的"理解",而是由确定性的代码保证
这不是模型变聪明了,是架构做对了。

DSPy的启示:别写Prompt,写程序
这种理念并非空穴来风。斯坦福大学推出的DSPy框架,其核心理念就是**"别写Prompt,写程序"**。DSPy把与大模型的交互抽象为可编程的模块,开发者定义输入输出的签名(Signature),框架自动优化底层的Prompt,开发者只需要关注程序逻辑本身。
DSPy(Declarative Self-improving Language Programs)由斯坦福NLP实验室于2023年发布,其核心创新在于将Prompt从手写字符串提升为可优化的程序参数。开发者通过定义Signature(输入输出的类型声明)和Module(如ChainOfThought、ReAct等推理模块)来描述任务逻辑,DSPy的编译器(Compiler)则通过少量标注样本自动搜索最优Prompt和Few-shot示例组合。这意味着Prompt不再是人工调参的产物,而是被纳入机器学习的优化循环——从根本上将"Prompt工程"转变为"程序设计",让系统自己找到最有效的表达方式。
这代表了AI编程的一个重要趋势:我们正在从"Prompt工程"走向"Agent工程"。前者的核心技能是写出好的自然语言指令,后者的核心技能是设计好的系统架构。
对开发者的实际建议
如果你正在构建AI Agent,以下几点值得立即实践:
- 拆分Prompt:任何超过500 token的Prompt都应该被拆解为多个单一职责的小Prompt
- 用代码编排流程:状态转移、条件分支、循环重试,这些逻辑必须写在代码里,而不是Prompt里
- 为每个节点添加校验:类型检查、格式验证、结果断言,确保每一步的输出符合预期后再进入下一步
- 善用成熟框架:LangGraph、DSPy、CrewAI等框架都在朝控制流优先的方向演进,善用工具能事半功倍
当前Agent编排框架生态已相对成熟,各有侧重:LangGraph基于图结构,适合需要精细控制循环与条件分支的复杂Agent;CrewAI以多Agent协作为核心,内置角色分工和任务委派机制,适合模拟团队协作场景;AutoGen(微软)则专注于多Agent对话编排,支持人机混合介入。这些框架的共同趋势正是"控制流优先"——将流程编排的主导权从LLM交还给代码,LLM只在明确边界内完成认知任务。选择框架时,核心考量应是其对状态持久化、错误重试和节点级可观测性的支持程度。
Agent的未来不是更长的Prompt,而是更聪明的架构。当你发现自己在Prompt里写 if...then...else 的时候,停下来——那应该是代码的工作。
核心要点
- 自然语言是极差的编程语言,把控制流写进Prompt是Agent不可靠的根本原因
- LLM的"Lost in the Middle"效应决定了超长Prompt必然导致关键指令被稀释和遗忘
- 控制流优先架构将大模型当作函数调用,用代码定义状态机和错误处理,Prompt只负责单一任务
- 架构转变可将多步骤任务可靠性从40%提升至90%以上,单步成本降低80倍
- DSPy等框架代表了从Prompt工程到Agent工程的范式转变,Prompt本身成为可被机器优化的参数
- 开发者应拆分超长Prompt、用代码编排流程、为每个节点添加类型检查和校验
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。