Agent智能体工作原理拆解:四要素与ReAct循环决策机制详解
深入拆解Agent智能体的四大要素与ReAct循环决策工作原理
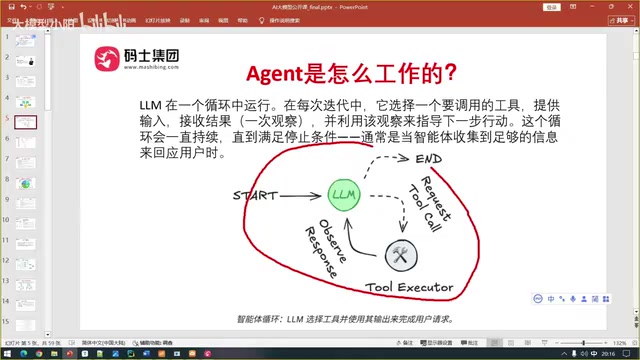
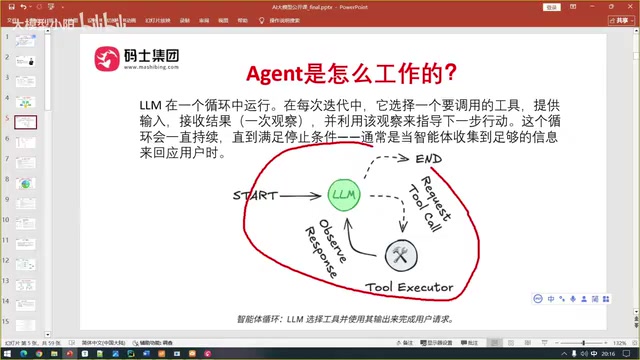
本文系统介绍了AI Agent智能体的核心构成与工作机制。Agent由大模型(决策大脑)、工具集(执行手脚)、提示词(参考手册)和工具执行器(行动桥梁)四大要素组成,遵循ReAct(推理+行动)范式工作:通过接收输入、模型推理决策、执行工具更新上下文、判断是否终止的循环迭代过程完成复杂任务。
什么是Agent智能体?
在大模型应用开发领域,Agent(智能体)是最核心的落地形态,没有之一。很多人听过这个概念,但对其内部构成和工作机制并不真正理解。本文将从Agent的四大组成要素出发,深入拆解ReAct循环决策的工作原理,帮助你建立对智能体的系统认知。
Agent的四大核心要素
所有的Agent智能体,不论基于哪种框架开发,都由四个核心部分组成:
1. 大模型(LLM):Agent的"大脑",负责提供决策和推理能力。它决定了智能体理解问题、规划步骤的上限。
大语言模型(Large Language Model,LLM)是基于Transformer架构、经过海量文本数据训练的神经网络模型。GPT-4、Claude、Gemini等代表性模型参数量通常在千亿级别以上。LLM之所以能成为Agent的"大脑",关键在于其涌现出的两种核心能力:**指令跟随(Instruction Following)**让模型能理解复杂任务描述,**上下文学习(In-Context Learning)让模型能根据对话历史动态调整推理路径。值得注意的是,不同模型在函数调用(Function Calling)**能力上差异显著,这直接决定了Agent能否准确识别并调用正确工具——这也是为什么选择底层模型是Agent工程中最关键的决策之一。
2. 工具集(Tools):让Agent能够执行具体动作的"手脚"。比如查询天气需要天气API工具,创建订单需要订单工具,查火车票需要票务工具。没有工具,Agent就只能"纸上谈兵"。
工具调用在技术实现层面依赖大模型的Function Calling机制,这一能力由OpenAI于2023年在GPT-3.5/GPT-4中率先商业化落地。其原理是:开发者将工具的名称、功能描述、参数Schema(通常为JSON Schema格式)注入到模型的请求中,模型在推理时若判断需要调用工具,会输出一段结构化的JSON而非自然语言,其中包含工具名和参数值。工具执行器解析这段JSON、执行对应函数、将结果以"工具消息"的形式追加到对话历史,再次触发模型推理。这一机制是现代Agent框架(LangChain、LlamaIndex、AutoGen等)的底层基础。
3. 提示词(Prompts):这里需要纠正一个常见误解——提示词不仅仅是程序员写的那段系统描述。在Agent体系中,提示词是一个广义概念,它包括:系统级的功能描述、每个工具的功能说明、每个工具参数的详细描述。这些信息共同构成了大模型做决策时的"参考手册"。
4. 工具执行器(Tool Executor):当大模型决策出需要调用某个工具时,执行器负责实际运行该工具并返回结果。它是连接"决策"与"行动"的桥梁。
ReAct范式:推理与行动的循环机制
所有智能体都遵循一个核心工作范式——ReAct(Reason + Action),即"推理+行动"。这不是某种特定的智能体类型,而是所有Agent通用的工作方式。
ReAct范式由谷歌研究院于2022年在论文《ReAct: Synergizing Reasoning and Acting in Language Models》中正式提出。其核心洞察是:单纯的推理链(Chain-of-Thought)缺乏与外部环境的交互,而单纯的行动序列又缺乏推理支撑,两者结合才能让模型在动态环境中稳健地完成复杂任务。ReAct的每一步都包含 Thought(思考过程)、Action(工具调用)、Observation(工具返回结果) 三个子步骤,这三者构成一个最小执行单元,多个单元串联形成完整的任务解决链路。
循环执行的核心流程
智能体的工作过程是一个循环迭代的过程,具体步骤如下:
第一步:接收输入并恢复状态
用户提供输入(可以是问题,也可以是请求),系统将用户输入与历史对话记录组合成完整的上下文(Context)。恢复状态的目的是让Agent具备"记忆"——比如用户说"今天这个城市天气怎么样",Agent需要从上下文中找到"这个城市"具体指哪里。
这里的"记忆"本质上依赖大模型的上下文窗口(Context Window)——即模型单次推理时能处理的最大Token数量。GPT-4 Turbo支持128K Token,Claude 3系列最高支持200K Token。随着循环迭代,工具返回结果不断追加到上下文中,Token消耗持续增长。当任务复杂度较高、工具调用次数较多时,上下文可能接近窗口上限。为此,企业级Agent系统通常会引入外部记忆模块(如向量数据库)来存储长期记忆,只将最相关的历史片段检索回上下文,以突破窗口限制。
第二步:大模型推理与决策
大模型根据上下文和所有工具的描述信息进行推理,判断当前应该调用哪个工具。这个过程完全依赖大模型的语义理解和逻辑推理能力,不是程序员用if-else硬编码控制的。
第三步:执行工具并更新上下文
工具执行器运行被选中的工具,将返回结果追加到上下文中。此时上下文信息变得更丰富了。
第四步:判断是否终止循环
大模型重新审视更新后的上下文,判断是否已经收集到足够的信息来回答用户的问题。如果还不够,继续回到第二步,决策调用下一个工具;如果已经足够,生成最终答案,循环结束。
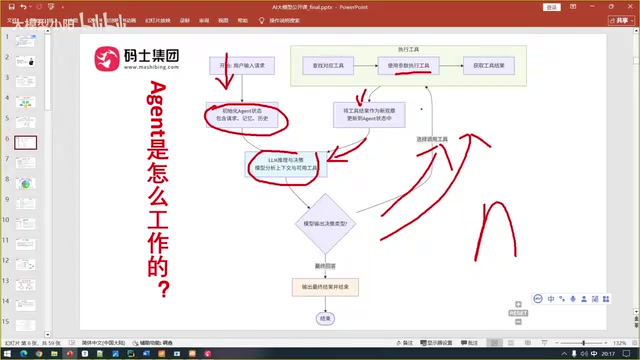
循环终止的条件
很多人担心这个循环会变成死循环。实际上有两种终止条件:
- 正常终止:上下文中已经包含了足以回答用户问题的完整信息
- 异常终止:大模型重复思考约三次后仍找不到合适的工具,会主动返回错误信息告知用户
循环次数没有固定限制,可能一次就够,也可能需要多次迭代。
实例拆解:查询上海天气的完整流程
用一个具体例子来串联整个流程。用户输入:"上海今天天气怎么样?用摄氏度告诉我。"
第一轮:思考→行动
思考(Reason):大模型推理得出——用户想知道上海的实时天气,且要求摄氏度。我自身没有实时数据,需要借助工具。在工具列表中找到一个名为get_weather的工具,可以查询天气。
行动(Action):通过工具执行器调用get_weather工具,传入参数"上海
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。