AI Agent架构详解:核心组件、四大框架与思维链技术

AI Agent通过给大模型加装工具和执行流程,使其从聊天机器人进化为自主行动的智能助手。
AI Agent的本质是"大模型+外部工具+执行流程",通过控制端、感知端和行动端三大组件弥补大模型的幻觉、实时信息缺失和计算不足等短板。业界代表性框架包括AutoGPT(提示词工程)、BabyAGI(任务递归分解)、HuggingGPT(多模型协作)和LlamaIndex(知识检索增强),配合CoT、CoT-SC、ToT等思维链技术提升推理能力。当前Agent仍面临链路过长、效率低、迁移性差等挑战,但它是大模型走向产品落地的必经之路。
大模型虽然强大,但它有幻觉、缺乏实时信息、计算能力有限——这些"人工智障"时刻让人又爱又恨。AI Agent(智能体)的出现,正是为了给大模型"打补丁",让它从一个只会聊天的语言模型,进化为能调用工具、分解任务、自主行动的智能助手。
本文将系统梳理AI Agent的核心架构、四大经典框架和思维链技术,帮你建立对智能体技术的完整认知。
Agent的本质:给大模型装上手和脚
一句话概括Agent:大模型 + 外部工具 + 执行流程 = Agent。
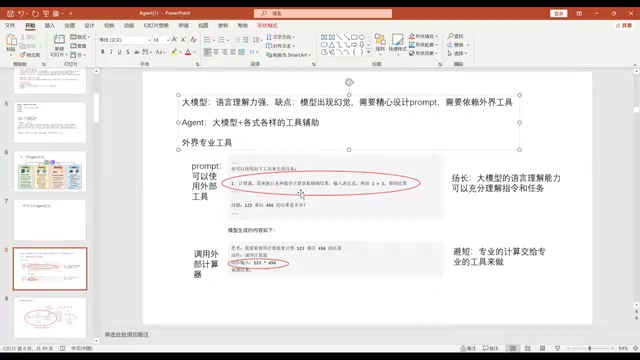
当前的大语言模型(如GPT-4、LLaMA、Claude等)面临几个核心问题:会产生幻觉输出虚假信息、无法获取实时数据(比如今天的天气或最新新闻)、复杂计算能力不足。Agent的设计思路就是"扬长避短"——利用大模型强大的语言理解能力来"指挥",把专业的事情交给专业的工具来做。
举个例子:你问大模型"123×456等于多少",它可能算不准。但通过Agent架构,大模型会理解你的意图,然后调用计算器API得出精确答案56088。这就是给大模型装上了"手和脚"。
AI Agent的三大核心组件
一个完整的Agent架构由控制端、感知端和行动端三部分组成,它们各司其职又紧密协作。
控制端:Agent的大脑
控制端是整个Agent的核心,需要具备五大能力:
- 自然语言处理能力:理解用户意图,这是大模型的基本功
- 知识获取能力:通过外部知识库(如RAG检索增强生成)获取实时信息
- 记忆能力:包括短期记忆(多轮对话上下文)和长期记忆(历史交互记录)
- 推理与规划能力:将复杂任务分解为子任务。比如"特朗普时期阿里巴巴的CTO是谁",需要先确定时间范围,再查找对应人选
- 迁移与泛化能力:在不同场景下灵活应对,"见人说人话,见鬼说鬼话"
感知端:Agent的眼睛和耳朵
感知端负责接收多模态输入——文本、图片、语音等。这本质上是多模态技术的应用,比如将图片转化为文本描述或编码,再与语言模型交互。随着多模态大模型的发展,感知端的能力正在快速提升。
行动端:Agent的手和脚
行动端负责执行具体操作:调用计算器、访问天气API、触发搜索引擎,甚至调用其他AI模型(如Stable Diffusion图像生成、TTS语音合成)。大模型不再只是输出文本,而是能真正"做事"。
四大经典Agent框架深度解析
了解了Agent的基本架构后,我们来看看业界最具代表性的四个Agent框架,它们各自代表了不同的设计思路。
AutoGPT:提示词工程的极致
AutoGPT是最早引爆Agent热潮的项目之一,它的核心其实就是一套精心设计的Prompt工程。它会在提示词中明确告诉大模型:你的目标是什么、有哪些限制条件、可以使用哪些工具(如Google搜索、浏览器)、拥有什么资源、输出格式要求等。
这套方案的优势在于能最大限度激发大模型能力,但也有明显局限:模型必须足够大(至少百亿参数级别),且不同模型需要不同的提示词适配,可迁移性较差。
BabyAGI:任务分解与递归执行
BabyAGI的核心思想是将复杂任务递归分解为子任务。举个简单例子:你问"我想泡茶应该怎么操作",大模型会分解为三步——烧开水、准备茶叶、冲泡。然后对每个子任务再次调用大模型进一步细化,比如"烧开水"会被分解为"把凉水放进水壶→接通电源"。
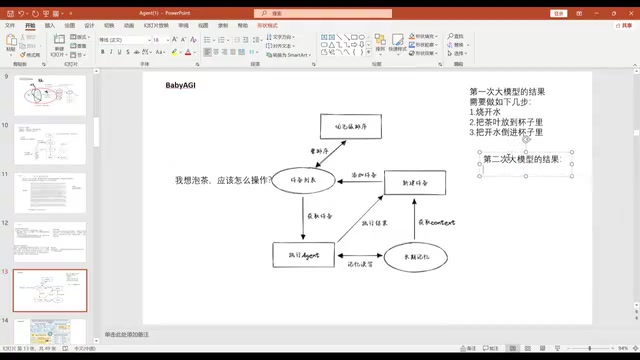
这种方式的核心难点在于流程设计——如何合理地设计任务分解和执行的流程。大模型本身没变,变的是围绕它搭建的工作流。BabyAGI的思路对后来的很多Agent框架都产生了深远影响。
HuggingGPT:多模型协作的指挥官
HuggingGPT展示了一种更复杂的Agent形态:一个大模型指挥多个专业模型协作。
比如输入一张图片,要求"生成一个小女孩读书的图片,体态与原图一致"。这个任务需要:
- 调用姿态检测模型提取体态
- 调用图像生成模型生成新图片
- 调用目标检测模型框选结果
- 调用语音模型播报描述
这种架构能解决复杂的跨模态问题,但缺点也很明显——链路过长,任何一个环节出错都会影响最终结果。目前这类方案还主要停留在Demo阶段,解决的是"有无"问题,而非"完备稳定"问题。
LlamaIndex:知识外挂与高效检索
LlamaIndex专注于解决大模型的知识缺陷问题,核心是将外部数据以不同结构存储并高效检索,是构建RAG系统的重要工具。
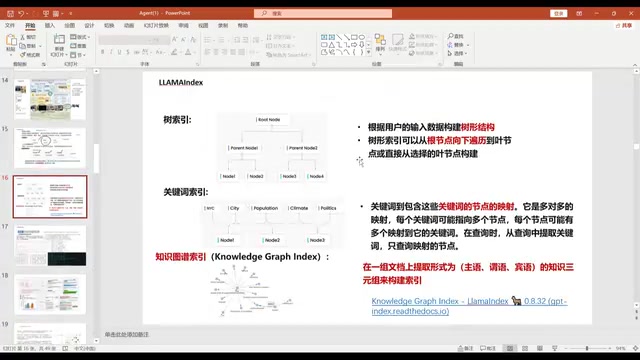
它支持多种索引方式:
- 列表索引:基于关键词的简单检索,适合结构化数据
- 向量存储索引:通过语义相似度检索,能找到关键词匹配之外的相关内容。比如搜索"哈马斯",向量检索还能关联到"巴勒斯坦""以色列"等相关知识
- 树形索引:按层级结构组织知识,如"中东局势→巴以冲突→哈马斯",检索时能获取完整的上下文
- 知识图谱索引:通过实体关系进行多跳检索,比树形结构更加灵活,适合复杂关联查询
思维链技术:让大模型学会分步推理
思维链(Chain of Thought, CoT)是Agent中至关重要的推理技术,它让大模型不再"拍脑袋给答案",而是展示完整的推理过程。
标准CoT:教大模型"抄解题步骤"
标准CoT的核心思路是:不仅给大模型答案,还给出推理过程。就像小学抄作业,不能只抄答案,还要抄解题步骤。比如"5+2×3=?",你需要在示例中展示"先算2×3=6,再算5+6=11"的过程,大模型就能学会这种分步推理的模式。
CoT-SC(自洽性):多次投票取最优
CoT-SC利用大模型输出的随机性,对同一问题多次调用,然后对结果投票取多数。也可以用不同模型分别回答同一问题再投票,类似于"三个臭皮匠赛过诸葛亮"的策略。这种方法能显著提升推理结果的可靠性。
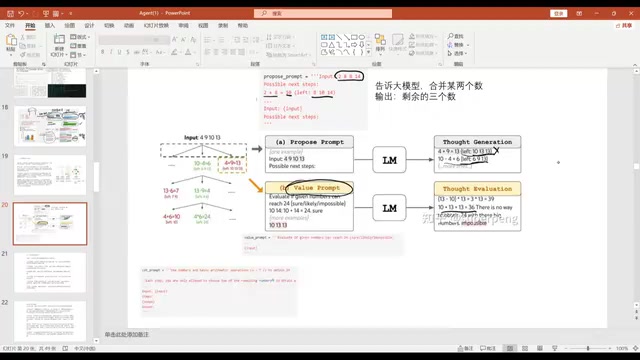
ToT(思维树):搜索、评估与回溯
ToT(Tree of Thoughts)在CoT基础上加入了搜索、评估和回溯机制,是目前最先进的推理框架之一。
以24点游戏为例,大模型会先列出所有可能的两数合并方案,然后自我评估每种方案凑成24点的可能性,淘汰不可行的分支,最终找到正确路径。这种"探索-评估-剪枝"的策略,让大模型具备了类似人类的试错能力。
Agent的五大局限与未来展望
用一个比喻来总结:如果大模型是电池,那Agent就是电动车。电池是核心动力,但用户买的是整辆车。Agent是大模型走向最终产品的必经之路。
但当前Agent技术仍面临五大挑战:
- 依赖大模型核心能力:电池不行,车再好也跑不远。底层模型的推理能力直接决定了Agent的上限
- 链路过长容易出错:串联架构中任何环节失败都会导致整体失败,系统鲁棒性不足
- 多次调用效率低:反复调用大模型带来延迟和成本问题,影响用户体验
- 跨模型迁移能力弱:为GPT-4设计的提示词换到LLaMA上可能完全失效,适配成本高
- 高度依赖提示词设计水平:Agent的能力上限很大程度取决于Prompt工程师的水平
尽管如此,单纯依靠大模型的端到端能力是有上限的,很多复杂问题无法一步到位解决。Agent这种"分解-调用-组合"的范式,将是大模型应用落地的主流方向。可以预见,未来所有面向用户的大模型产品,最终都会以Agent的形式呈现。
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。