AI Agent首次湿实验对决人类:蛋白质Binder设计Hit Rate无显著差异

AI Agent在蛋白质设计湿实验中首次追平人类设计师
2026年2月旧金山Hackathon中,六个全自主LLM Agent与九支人类队伍针对阿尔茨海默症靶点TREM2进行蛋白Binder设计,湿实验验证显示两者Hit Rate无统计学显著差异(34.3% vs 38.5%)。但实验也暴露出In-Silico筛选工具精度不足(AUC仅0.65)、Agent工具选择严重趋同等问题,表明蛋白设计师的价值正从执行转向问题定义与非共识判断。
2026年2月28日,旧金山一场仅持续一天的Hackathon,悄然改写了计算生物学的历史。九支人类队伍对阵六个全自主LLM Agent(Claude、Quinn、Grok、Gemini、GLM、GPT),任务是针对阿尔茨海默症相关的微胶质细胞受体TRAM-2,从头设计蛋白Binder。141个设计提交,Top 100进入湿实验验证,最终37个被确认为真正的Binder。
TRAM-2(TREM2,Triggering Receptor Expressed on Myeloid Cells 2)是一种在大脑微胶质细胞表面高度表达的跨膜受体。微胶质细胞是中枢神经系统的常驻免疫细胞,负责清除β-淀粉样蛋白斑块、修剪突触以及调控神经炎症。TREM2的功能缺失突变(如R47H)被全基因组关联研究(GWAS)确认为阿尔茨海默症最强的单基因风险因子之一,携带者患病风险提高2-4倍。设计能与TREM2高亲和力结合的蛋白Binder,可能用于激活微胶质细胞的吞噬功能或作为诊断探针,是当前神经退行性疾病药物开发的前沿方向。
这不是又一个Benchmark排行榜,而是第一次真正意义上的AI Agent与人类蛋白质设计师湿实验闭环对比。结果令人震惊,也令人深思。
AI Agent追平人类蛋白质设计师:Hit Rate统计无显著差异
先看核心数据:人类队伍的Hit Rate为38.5%(25个Binder),Agent的Hit Rate为34.3%(12个Binder)。Fisher精确检验P值等于0.83,pKD分布的Mann-Whitney检验P值等于0.75——统计意义上,两者没有任何显著差异。
这里有必要解释这两项统计检验的含义。Fisher精确检验是一种用于分析2×2列联表的非参数统计方法,特别适用于样本量较小的情况——它比较的是人类和Agent两组的Binder成功/失败比例是否存在显著差异。P值0.83意味着观察到的差异有83%的概率仅由随机波动造成,远高于通常的显著性阈值0.05。Mann-Whitney U检验则比较两组pKD分布的中位数差异,P值0.75同样表明两组的亲和力分布没有统计学上的显著区别。两项检验共同构成了"AI追平人类"这一结论的严格统计学基础。
排行榜前三名确实都是人类,但Agent的最好成绩排在第四,最强人类仅比最强Agent高出约三倍。考虑到每个Agent只收到一份Brief,然后被丢进Muni的Sandbox——一个为LLM Agent设计的隔离计算环境,Agent在其中可以访问预装的蛋白设计工具链、执行计算任务、读取输出结果并做出后续决策——自己挑工具、自己跑Pipeline、自己排序、自己交出Final 10,这个成绩已经相当惊人。这一全流程涵盖了科研中的问题理解、方案设计、实验执行和结果评估四个核心环节,是当前AI Agent在科学发现领域最完整的端到端能力测试之一。
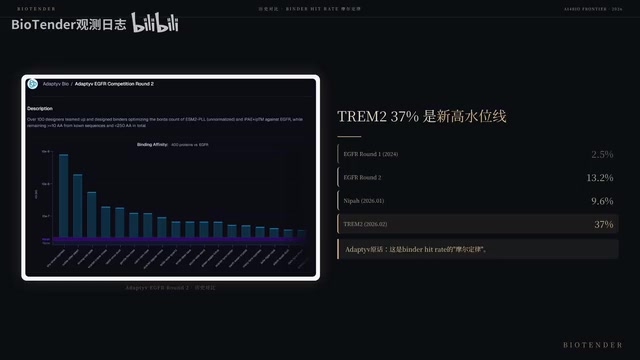
更值得关注的是历史纵向对比。Adaptive竞赛第一届针对EGFR的Hit Rate只有2.5%,第二轮提升到13.2%,今年1月NIPA任务为9.6%。而这场TRAM-2任务的整体Hit Rate突破30%,是Post-AlphaFold时代Binder设计的新高水位线。Adaptive团队将其称为"Binder Hit Rate的摩尔定律"。
要理解这一进步的意义,需要了解蛋白Binder设计的基本原理。从头设计一个全新的蛋白质分子使其高亲和力结合目标蛋白,需要精确计算蛋白-蛋白相互作用界面的形状互补性、氢键网络、疏水堆积和静电匹配。传统方法依赖Rosetta等能量函数驱动的计算框架,而AlphaFold2的出现使结构预测精度大幅提升,催生了RFdiffusion、BindCraft等基于深度学习的新一代设计工具。衡量Binder成功与否的核心指标正是Hit Rate(提交设计中真正能结合目标的比例)和pKD(解离常数的负对数,数值越高表示亲和力越强)。从2.5%到30%的Hit Rate跃迁,标志着这些新工具正在从"偶尔成功"走向"可靠产出"。
In-Silico评分器精度不足:Agent设计被过度淘汰
然而,"追平"这个结论建立在一个并不精确的筛选机制之上。
141个设计如何筛出Top 100?用的是BoSe 2的iPSAE评分。iPSAE(integrated Protein Structure and Energy)是一种综合考虑结构预测置信度、界面能量和接触面积等特征的In-Silico评分函数。但Muni团队在湿实验做完后回头复盘发现,iPSAE对于"是否为Binder"的二分类预测,AUC仅为0.65——比随机猜测强一些,但离一个可靠的分类器差得很远。
AUC(Area Under the ROC Curve,受试者工作特征曲线下面积)是衡量二分类器性能的标准指标:AUC=1.0表示完美分类,AUC=0.5等同于随机猜测。iPSAE的AUC仅为0.65,意味着它在区分"真正能结合的Binder"和"不能结合的设计"时,准确性仅略优于抛硬币。这一发现对整个计算生物学领域具有警示意义——许多研究依赖类似的In-Silico指标来筛选候选分子,但这些指标的实际预测能力可能远低于预期。
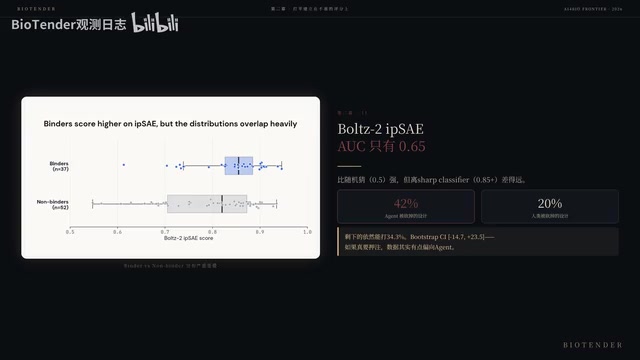
更微妙的是,这个不准的Filter对Agent的设计砍得更狠:Agent损失了42%的设计,而人类只损失了20%。换句话说,如果换一个更准确的筛选器,Agent可能有更多设计进入湿实验验证,最终的Hit Rate或许会更高。
这揭示了一个深层问题:当前In-Silico评估工具的精度,已经成为制约蛋白质设计领域进步的核心瓶颈。 AUC 0.65意味着我们对设计好坏的预判能力依然薄弱,只有湿实验闭环才能给出真相。
六个LLM Agent集体选择PX Design:工具趋同现象值得警惕
这是整篇报告中最让人"后背一凉"的发现。
Muni提供的工具菜单很长:PX Design、BindCraft、RF Diffusion、BoSe Gen等等。这些工具代表了截然不同的技术路线——PX Design基于物理能量函数与深度学习的混合架构;RFdiffusion由David Baker实验室开发,基于扩散模型(Diffusion Model)从噪声中逐步生成蛋白骨架结构,是当前最具影响力的de novo设计方法之一;BindCraft则侧重于利用AlphaFold2的结构预测能力反向优化序列,通过迭代优化使预测结构收敛到理想的结合构型。不同工具代表了不同的设计哲学——从物理驱动到数据驱动,从全局生成到模块组装。
然而,六个Agent来自完全不同的公司,没有互相沟通,却全部独立地选择了PX Design。Claude、Quinn、Grok、Gemini、GLM、GPT,六家齐全。

PX Design占了Agent提交设计的53%,Agent的Top 10 Binder中,10个全部来自PX Design。
为什么是PX Design?它确实表现不错,去年8月刚发了Preprint,Marketing做得漂亮,声称17-82%的Hit Rate。Agent可能通过Knowledge Cutoff之后的训练数据、工具列表描述或Web Search发现了它。具体机制不重要,重要的是结果:当AI Agent成为科研Pipeline的入口,谁的工具被Agent"看见"并优先选择,谁就赢了。
这意味着一种全新的竞争维度正在形成——工具开发者不仅要让人类科学家认可自己的工具,还要让AI Agent能够发现并优先选择自己的工具。这几乎是"SEO for AI Agent"的科研版本,也是计算生物学工具生态面临的全新挑战。
蛮力生成vs专家判断力:人与AI Agent的本质差异
按工具拆分来看,人机差异更加鲜明。
冠军队伍NRes使用的是Mosaic方法——一种采用模块化拼接策略的设计方法,将已知有效的结构模块重新组合以构建新的结合界面——6个设计中4个成功,Hit Rate高达66.7%。值得注意的是,Mosaic甚至不在Muni的官方工具菜单里,这意味着冠军队伍主动引入了非标准化的工具选择,体现了人类设计师在方法论层面的创造性判断。同样使用PX Design,人类的Hit Rate为72.7%,远高于Agent的44.4%。
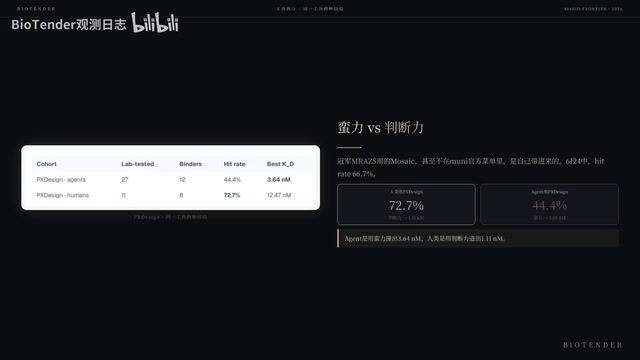
但有趣的是,完全"压满"PX Design的Agent,反而撞出了亲和力最高的Binder——3.64纳摩尔。这个数字在整个竞赛中排名靠前。在药物开发的语境中,KD值越小表示Binder与靶点的结合越紧密。一般而言,KD在微摩尔(μM)级别的分子被视为初步命中(Hit),纳摩尔级别则进入先导化合物(Lead)的范畴,而临床候选药物通常需要达到亚纳摩尔甚至皮摩尔级别。3.64 nM的亲和力意味着该设计已经具备了作为先导分子进一步优化的潜力,无需经过大量亲和力成熟(Affinity Maturation)步骤即可进入功能验证阶段。对于一个在Hackathon中一天内从头设计的蛋白来说,这一数字尤为突出。
这揭示了人与AI Agent在蛋白质设计中的本质差异:Agent靠蛮力大量生成,人类靠判断力精准设计。 人类设计师会根据经验选择不同工具、调整参数、做出非标准化的判断;Agent则倾向于找到一个"看起来最好"的工具然后大量生成,用数量换质量。
两种策略各有优劣,但当计算成本持续下降时,蛮力策略的性价比会越来越高。
蛋白质设计师的未来:不是会不会被取代而是如何转型
回到最核心的问题:AI Agent时代,蛋白质设计师的饭碗保不保?
短期来看,真正危险的不是资深设计师,而是只会跑单一Pipeline的执行者。 这场Hackathon的真正信号是三件事同时发生:
- AI Agent端到端能力已追平人类Hit Rate——从理解任务、选择工具、运行计算到提交结果,全程无人干预
- 现有In-Silico Filter严重不足(AUC仅0.65)——湿实验闭环仍然不可替代
- Agent在工具选择上严重单一化——缺乏人类设计师的多样性思维和非共识判断
设计师的饭碗保得住,但端着饭碗的姿势必须改变。未来的蛋白质设计师需要具备三种核心能力:理解AI Agent的行为模式并加以引导的能力、在工具选择上做出非共识判断的能力、以及设计和解读湿实验的能力。
当AI Agent能在一天内完成从Brief到Final Design的全流程,设计师的价值不再是"跑Pipeline",而是定义问题、选择非显而易见的路径、以及在Agent的输出上做出最终判断。这场旧金山的一日Hackathon,不是终点,而是人机协作蛋白质设计新时代的起点。
核心要点
- 六个全自主LLM Agent在蛋白Binder设计湿实验中首次追平人类,Hit Rate分别为34.3%和38.5%,统计上无显著差异
- 现有In-Silico筛选工具(iPSAE)AUC仅0.65,对Agent设计的淘汰率(42%)远高于人类(20%),湿实验闭环仍是验证真相的唯一途径
- 六个来自不同公司的Agent在无沟通情况下全部选择了PX Design工具,暴露出Agent工具选择严重趋同的问题
- 人类设计师通过判断力和工具多样性取得更高单工具Hit Rate,但Agent凭借蛮力策略撞出了亲和力最高的Binder(3.64纳摩尔)
- 蛋白设计师的核心价值正从执行Pipeline转向定义问题、非共识工具选择和湿实验判断
相关推荐
 前沿研究
前沿研究纽约中央公园发现新物种?城市昆虫猎捕计划揭秘
科学家在纽约中央公园和布鲁克林展望公园设置昆虫捕集器,试图在城市环境中发现未知物种。地球90%物种尚未被命名,城市生物多样性研究正成为生态学新趋势。
 前沿研究
前沿研究希格斯玻色子发现始末:亲历者讲述「上帝粒子」背后的故事
费米实验室物理学家亲历讲述希格斯玻色子发现全过程:费米实验室与CERN的跨大西洋竞赛、2012年历史性宣布的幕后细节、从发现到验证的14年科学历程,以及「上帝粒子」名号的真实由来。
 前沿研究
前沿研究SciMDR:7B小模型如何在科研推理上比肩GPT-5
耶鲁大学等机构推出SciMDR框架,通过两阶段数据合成流水线,让70亿参数小模型在科研文献阅读理解上达到接近GPT-5水平。本文详解其降维构建与升维重塑的核心技术原理及实验结果。