Agent评估五维体系:AI产品经理面试必考题全解析
系统化拆解AI Agent评估体系的五维指标与方法论
文章针对AI Agent评估这一核心问题,提出了一套完整的体系化评估框架:首先区分结果评估与过程评估两个维度,其次从真实用户数据、竞品采集和人工构造三个来源设计任务集,然后围绕"诚(成功率)、快(效率)、省(成本)、稳(可靠性)、安全(风险防控)"五维指标进行系统评估,最后通过对照实验验证Agent的实际价值。
在AI产品经理的面试中,有一道题几乎是必考的:你做的Agent怎么评估好不好?
很多人的第一反应是"看回答准不准",但如果你只给出这样的回答,面试官大概率会判断你没有真正做过Agent产品。因为在实际项目中,Agent评估远不是"答得好不好"这么简单——它是一整套系统化的评估体系。这篇文章把这套评估逻辑拆解清楚,帮你在面试和实际工作中都能游刃有余。
在深入评估方法之前,有必要先理解Agent的本质。AI Agent(智能体)不同于传统的聊天机器人或简单的问答系统,它是一种能够自主感知环境、制定计划、调用工具并执行多步骤任务的AI系统。典型的Agent架构包含规划模块(Planning)、记忆模块(Memory)、工具调用模块(Tool Use)和执行模块(Action)。正因为Agent涉及多个模块的协同工作和外部系统的交互,其评估复杂度远超单纯的大模型问答评估——你不仅要评估最终输出,还要评估整个决策链路的合理性。
搞清楚评估的是结果还是过程
很多人在评估Agent时只关注结果——答案对不对、任务完没完成。但真正有经验的产品经理知道,Agent评估一定要同时看过程。
过程评估需要关注的维度包括:
- 有没有重复调用工具?
- 有没有失败重试?
- 有没有逻辑跳跃?
- 有没有卡住进入死循环?
- 有没有兜底策略?
在技术实现上,过程评估通常依赖于Agent的执行轨迹(Trace)分析。每一次Agent运行都会产生一条完整的Trace,记录了从接收用户输入到最终输出之间的所有中间步骤,包括每次大模型推理的输入输出、工具调用的参数和返回值、以及状态转换的逻辑。通过对Trace的结构化分析,可以精确定位Agent在哪个环节出了问题——是规划阶段的意图理解错误,还是工具调用阶段的参数传递失误,抑或是结果整合阶段的信息丢失。这种细粒度的过程诊断能力,是优化Agent性能的核心基础。
所以Agent评估至少要拆成两个维度:结果对不对和过程稳不稳。这是评估体系的第一层逻辑,也是区分"纸上谈兵"和"实战经验"的分水岭。
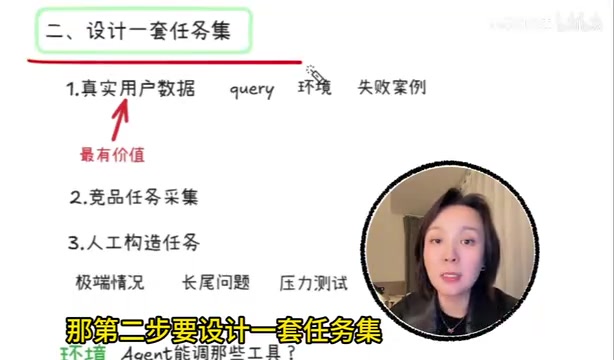
设计一套科学的任务集
评估Agent的前提是——你用什么任务去测试它?任务集的设计质量直接决定了评估的有效性。一般来说,任务来源有三种:
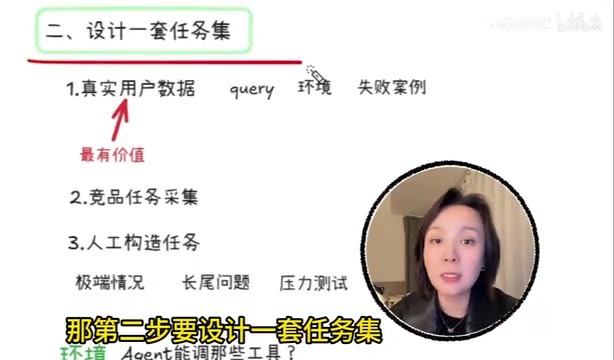
真实用户数据(最有价值)
用户的真实query、真实使用环境、真实的失败案例,这是最接近生产场景的测试素材。它能暴露出那些你在设计阶段根本想不到的边界问题。
竞品任务采集
如果你做的是智能客服Agent,那行业里的典型问题、高频回答、标准业务流程,都可以纳入任务集。这类任务帮助你建立行业基准线,也能快速发现自家Agent和竞品之间的差距。
人工构造任务
主要用来测试极端情况、边界问题和压力场景。很多人忽略了这一点,但它恰恰是发现系统脆弱性的关键手段。
特别需要注意的是,任务不仅仅是一句话。它还包括环境信息:Agent能调用哪些工具、知识库版本是什么、有没有调用限制、失败后怎么兜底——这些都是Agent评估中不可忽视的组成部分。
五维评估指标:诚、快、省、稳、安全
这是整个Agent评估体系中最核心的部分。我将其总结为五个字:诚、快、省、稳、安全。如果你在面试时能把这五个维度讲清楚,面试官基本就会认定你是真正做过Agent产品的人。
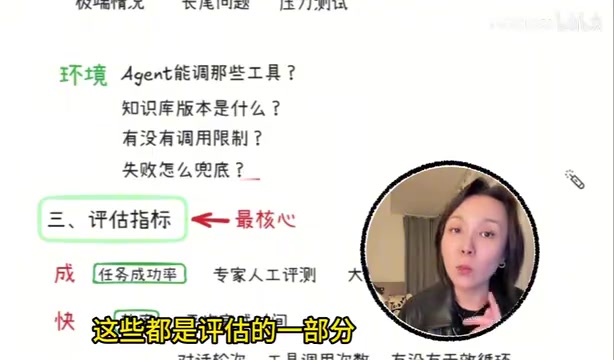
诚——任务成功率
从任务视角定义"成功"。比如机票改签场景,不是Agent说"已帮您改签"就算成功,而是要看:
- 是不是真的帮用户完成了改签操作?
- 是不是同步到了订单系统?
- 用户是否收到了确认通知?
如果没有标准答案可以对照,一般采用两种方法:专家人工评测或用大模型自动评测(LLM-as-Judge)。前者精度高但成本大,后者可规模化但需要校准。在实际Agent评估项目中,两种方法往往配合使用。
LLM-as-Judge是近两年在AI评估领域兴起的重要方法论,最早由UC Berkeley等机构在2023年系统提出。其核心思路是利用GPT-4等强大的大语言模型作为"裁判",对Agent的输出质量进行自动化评分。具体实现时,通常会设计详细的评分标准(Rubric),将其作为系统提示词传给评判模型,让它对Agent的回答从准确性、完整性、相关性等维度打分。这种方法的优势在于可以大规模、低成本地进行评估,研究表明其与人类专家评分的一致性可达80%以上。但它也存在已知偏差,比如位置偏差(倾向于给排在前面的答案更高分)和冗长偏差(倾向于给更长的回答更高分),因此在实际使用中需要通过多次评测、交换顺序等校准手段来提高可靠性。
快——执行效率
一个靠谱的Agent不是慢慢"思考",而是在合理时间内完成任务。效率评估需要关注:
- 平均完成时间
- 对话轮次
- 工具调用次数
- 有没有无效循环

很多Agent的问题不是不聪明,而是太啰嗦——反复调用工具、多余的确认步骤、冗长的推理链条。这些都会严重拖累用户体验和系统效率。
省——成本控制
很多Agent看起来实现了自动化,但一算账发现比人工还贵。成本评估需要计算:
- Token消耗量
- API调用次数和费用
- 单任务综合成本
Token是大语言模型处理文本的基本计量单位,大致可以理解为文本的最小语义片段(中文中大约1个汉字对应1.5-2个Token)。主流大模型API按Token数量计费,输入和输出分别定价。对于Agent而言,成本问题尤为突出,因为一次完整的任务执行可能涉及多轮大模型调用——规划阶段需要一次调用,每次工具选择需要一次调用,结果整合又需要一次调用,再加上可能的重试和纠错,单次任务的Token消耗量可能是普通对话的5-10倍。常见的成本优化策略包括:精简系统提示词、使用更小的模型处理简单子任务(模型路由)、缓存常见查询结果、以及优化Agent的推理链条减少不必要的中间步骤。
只有当Agent在保证质量的前提下真正做到了降本增效,它才有商业价值。这一点在向业务方汇报ROI时尤为关键。
稳——可靠性
同一个任务跑十次,成功率是不是稳定的?用户输入稍微复杂一点,系统会不会崩溃?这里一般会做鲁棒性测试,包括:
- 输入变体测试(同义表达、口语化表达、错别字)
- 并发压力测试
- 异常输入测试(超长文本、特殊字符、恶意输入)
鲁棒性(Robustness)这一概念源自控制理论,指系统在面对输入扰动或环境变化时维持正常功能的能力。在Agent评估中,鲁棒性测试通常采用对抗性测试(Adversarial Testing)的思路,系统性地构造各种"刁难"场景。具体技术手段包括:语义等价变换(将"帮我订明天去上海的机票"改写为"明儿我要飞上海,帮我搞张票")、信息缺失测试(用户只说"改签"但不提供航班号)、多意图混合测试(一句话里包含多个请求)、以及上下文干扰测试(对话中途插入无关话题后再回到原任务)。业界常用的量化指标是"一致性得分"(Consistency Score),即同一语义在不同表达形式下获得相同正确结果的比例。
一个成功率90%但波动剧烈的Agent,远不如一个成功率85%但表现稳定的Agent可靠。稳定性是Agent能否上线的底线要求。
安全——风险防控
这是五个维度中最重要的一个。一旦Agent具备了执行能力(比如操作数据库、发起交易、调用外部API),所有安全问题都会被成倍放大。
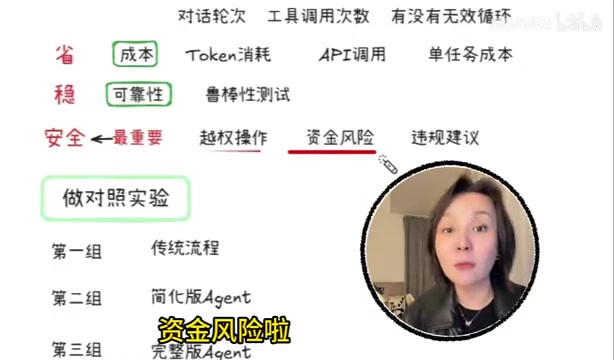
需要重点关注的风险场景包括:
- 越权操作:Agent是否会执行超出权限范围的操作?
- 资金风险:涉及金融交易时,Agent是否有足够的校验机制?
- 违规建议:Agent是否会给出违反法规或公司政策的建议?
Agent安全问题的本质在于,当AI系统从"建议者"升级为"执行者",其错误的后果也从"信息误导"升级为"实际损害"。业界目前普遍采用的安全防控框架包括几个层次:第一层是权限最小化原则(Principle of Least Privilege),即Agent只被授予完成当前任务所必需的最小权限集;第二层是人机协同确认机制(Human-in-the-Loop),对于高风险操作(如大额转账、数据删除)必须经过人工确认才能执行;第三层是操作可逆性设计,确保Agent执行的操作在出错时可以回滚;第四层是实时监控与熔断机制,当检测到异常行为模式时自动中断Agent的执行。此外,Prompt注入攻击(通过精心构造的输入诱导Agent执行非预期操作)是当前Agent安全领域最受关注的威胁之一,评估时需要专门设计此类攻击场景进行测试。
评估时一定要专门设计高风险场景,测试Agent在极端情况下是否会越界。这不是可选项,而是必选项。
设计对照实验验证Agent价值
最后一个很多人忽略但极其重要的环节——对照实验。最好设计三组对比:
| 实验组 | 说明 |
|---|---|
| 对照组A | 传统流程(人工处理或旧系统) |
| 实验组B | 简化版Agent(基础能力) |
| 实验组C | 完整版Agent(全部能力) |
通过三组对比,你才能清晰地回答以下问题:
- Agent相比传统方案提升了多少?
- 完整版Agent相比简化版的增量价值在哪里?
- 额外的复杂度是否值得投入?
对照实验(Controlled Experiment)的设计思路源自经典的A/B测试方法论,在互联网产品领域已有成熟的实践体系。但Agent的对照实验有其特殊性:首先,Agent的输出具有随机性(同一输入可能产生不同的执行路径),因此需要足够大的样本量来消除随机波动的影响;其次,Agent的表现可能受到任务顺序的影响(前一个任务的上下文可能影响后一个任务的执行),因此需要对任务顺序进行随机化处理;最后,评估指标往往是多维度的,需要综合考虑成功率、效率、成本等多个变量,不能仅凭单一指标下结论。在统计显著性检验方面,通常要求p值小于0.05,并且效果量(Effect Size)达到实际有意义的水平,才能认定Agent确实带来了有价值的提升。
这样对比出来的效果才真正有说服力,无论是面试还是向老板汇报都能站得住脚。
总结:用体系化思维回答Agent评估问题
一套完整的Agent评估体系可以概括为四个步骤:
- 明确评估维度:结果 + 过程
- 构建任务集:真实数据 + 竞品采集 + 人工构造
- 五维评估指标:诚(成功率)、快(效率)、省(成本)、稳(可靠性)、安全(风险防控)
- 对照实验:传统流程 vs 简化Agent vs 完整Agent
如果你在面试中能把任务集 + 五维指标 + 对照实验这一套逻辑完整地讲出来,面试官基本就会判断你是真正做过AI产品的人。评估体系的完整性和系统性,本身就是产品经理专业能力的最好证明。
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。