AI产品候补名单为何越排越长?从Siri到大模型的等待困局
当等待成为AI时代的新常态
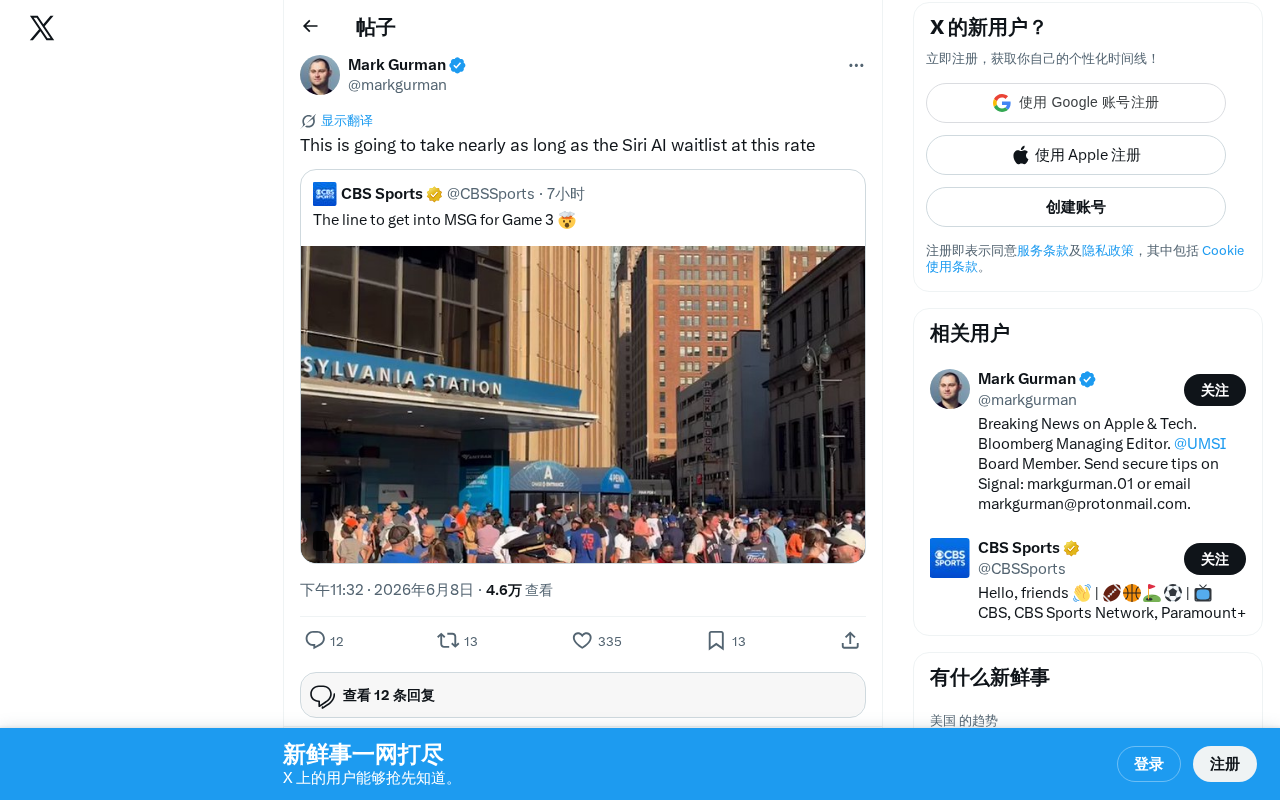
近日,一位Twitter用户发帖吐槽:"按照这个速度,等待时间快赶上Siri AI的候补名单了。"这条看似简单的抱怨,却折射出当前AI产品领域一个普遍而令人无奈的现象——用户正在经历越来越长的等待周期。
从Apple Intelligence的Siri升级版到各类大模型API的排队机制,"候补名单"(waitlist)已经成为AI产品发布的标配策略。用户的耐心正在被一次又一次地考验。
Siri AI候补名单:漫长等待的标志性符号
苹果在WWDC上宣布了Apple Intelligence计划,其中包括对Siri的重大AI升级。Apple Intelligence是苹果于2024年推出的个人智能系统,它将生成式AI能力深度整合到iOS、iPadOS和macOS中。其核心架构采用了端云协同的设计理念:简单任务由设备端的Apple Silicon芯片(如A17 Pro和M系列)本地处理,复杂任务则通过苹果自建的Private Cloud Compute(私有云计算)完成——这套私有云基础设施使用苹果自研芯片搭建,数据在处理后即时删除,从架构层面保障了用户隐私。
值得深入理解的是,苹果的Private Cloud Compute与传统云计算服务有着本质区别。传统云服务中,用户数据可能被存储、索引甚至用于模型训练,而苹果的PCC采用了"无状态计算"设计——每次请求在独立的加密环境中处理,计算节点不保留任何用户数据,且整个系统的代码经过独立安全研究人员的公开审计。这种架构虽然极大地保护了隐私,但也显著增加了系统复杂度和部署成本,因为无状态设计意味着无法通过缓存等传统优化手段来提升效率,间接加剧了产能瓶颈。
Siri的AI升级是其中最核心的用户感知功能,涵盖自然语言理解的大幅提升、跨应用操作能力、屏幕感知上下文等,苹果还与OpenAI达成合作,将ChatGPT集成为Siri的补充能力层。
然而,这项备受期待的功能并未如期全面推出。大量用户被放入了候补名单,等待时间之长已经成为科技社区广为流传的"梗"。
苹果的策略有其合理性:大规模AI推理需要庞大的计算资源,分批次开放能够确保服务质量和系统稳定性。但对于已经购买了最新硬件的用户来说,这种等待无疑令人焦虑。当其他AI产品的等待时间被拿来与Siri候补名单相提并论时,足以说明这个等待已经成为了"漫长"的代名词。
AI候补名单背后的行业逻辑
算力瓶颈是核心原因
当前AI产品普遍采用候补名单机制,根本原因在于GPU算力的供需严重失衡。无论是OpenAI、Google还是Apple,大规模部署AI服务都面临着基础设施的硬约束。每一个用户请求都需要消耗可观的计算资源,这与传统软件服务有着本质区别。
要理解这种区别,需要了解大语言模型推理的工作原理。传统互联网服务(如网页浏览、即时通讯)的后端处理主要依赖CPU,单次请求的计算量极小,通过负载均衡和CDN即可轻松扩展到数十亿用户。而大语言模型的推理过程本质上是一个自回归生成过程——模型需要逐token(词元)地生成输出,每生成一个token都需要对包含数十亿甚至数万亿参数的神经网络进行一次前向传播计算。
在这个过程中,一个关键的技术细节是KV Cache(键值缓存)机制。在自回归生成中,模型每生成一个新token都需要"看到"之前所有token的信息。为避免对历史token进行重复计算,系统会缓存Transformer每一层的Key和Value向量,这就是KV Cache。随着生成序列变长,KV Cache占用的GPU显存线性增长——对于GPT-4这样的超大模型,单个用户的长对话可能占用数GB的KV Cache显存。这意味着一台GPU服务器能同时服务的用户数量远比传统服务少得多,也解释了为什么长上下文对话比短对话消耗更多资源。
以GPT-4为例,其参数规模据估计超过1.8万亿,单次推理需要在GPU的高带宽显存(HBM)中加载和处理海量数据。HBM(High Bandwidth Memory)是由SK海力士和三星主导的高带宽堆叠内存技术,通过TSV(硅通孔)技术将多层DRAM芯片垂直堆叠,提供远超传统DDR内存的带宽(HBM3可达819GB/s),是大模型推理中数据搬运效率的关键所在。由于大模型推理往往是"内存带宽受限"(memory-bound)而非"计算受限"(compute-bound),HBM的带宽直接决定了推理速度的上限。这意味着AI服务的边际成本远高于传统软件服务,用户规模的线性增长会带来计算资源需求的近线性甚至超线性增长。
而在供给侧,当前AI推理和训练所依赖的高端GPU市场几乎由NVIDIA垄断,其H100和H200芯片是大模型运行的核心硬件。然而,台积电先进制程(如4nm、5nm)的产能有限,加上CoWoS(Chip on Wafer on Substrate)先进封装技术的产能瓶颈,导致这些芯片的交付周期长达数月。CoWoS是台积电开发的2.5D/3D先进封装技术,它将GPU计算芯片与HBM堆叠封装在同一硅中介层基板上,通过极短的互连距离实现芯片间的超高带宽通信。2023-2024年间,CoWoS产能成为整个AI芯片供应链中最紧张的环节——即便台积电将CoWoS月产能从2023年初的约8000片晶圆扩张至2024年底的超过3.5万片,仍然无法满足来自NVIDIA、AMD、Google等客户的爆发式需求。
据行业估算,训练一个GPT-4级别的模型需要约25000块A100 GPU运行数月,而每天为数亿用户提供推理服务所需的GPU集群规模更是天文数字。单次GPT-4查询的计算成本约为传统Google搜索的10倍以上。这种供需失衡推动了NVIDIA的市值突破3万亿美元,也催生了AMD MI300X、Google TPU v5以及众多AI芯片初创公司的竞争格局。
饥饿营销还是无奈之举?
有观点认为,候补名单本身也是一种营销策略——通过制造稀缺感来提升产品的感知价值。但更客观地看,大多数AI公司确实面临着真实的产能限制。以OpenAI为例,其GPT-4发布初期的API等待名单长达数月,背后是实实在在的服务器成本和供应链压力。
用户体验的双刃剑
候补名单机制虽然能保证已接入用户的体验质量,但也带来了不可忽视的负面效应:
- 用户热情衰减:等待时间越长,用户对产品的期待越容易转化为失望甚至放弃
- 竞争对手的机会窗口:当一家公司让用户排队时,另一家可能已经提供了可用的替代方案
- 品牌信任侵蚀:反复的延期和等待会逐步消耗用户对品牌的信任和好感
从等待到可用:AI产品的成熟之路
回顾科技产业的历史,类似的等待并非没有先例。Gmail在2004年4月1日发布时,提供了当时令人震惊的1GB免费存储空间(竞争对手Hotmail仅提供2MB),但采用了严格的邀请制注册机制。这一策略持续了近三年,直到2007年才完全开放注册,邀请码一度在eBay上被炒到数百美元。Google官方解释是服务器存储成本限制了扩张速度,但这种稀缺性也确实为Gmail创造了巨大的口碑效应。类似地,Amazon Web Services(AWS)在2006年推出EC2时,用户同样需要申请并等待审批。云计算早期的产能不足源于数据中心建设周期长、服务器采购规模有限,这与今天AI领域面临的GPU供应瓶颈在本质上高度相似。
但AI领域的等待有其特殊性:用户等待的不仅是接入权限,更是功能的逐步完善。许多AI产品即使开放了访问,其核心功能也可能仍处于"即将推出"的状态。Siri的AI升级就是一个典型案例——即便部分用户已经获得了访问权限,许多承诺的高级功能仍在持续开发中。
当前的AI候补名单现象,本质上反映了行业发展速度与基础设施建设之间的时间差。好消息是,解决这一瓶颈的技术路径正在多线并进。
第一条路径是推理芯片的专用化和产能扩张,包括NVIDIA的下一代Blackwell架构(B100/B200,采用台积电4NP工艺,推理性能相比H100提升高达30倍)、各大云厂商的自研推理芯片(如AWS Inferentia、Google TPU),以及Groq等专注于推理加速的初创公司。Groq的技术路线尤其值得关注——与GPU的通用并行计算架构不同,Groq开发的LPU(Language Processing Unit,语言处理单元)采用了确定性计算架构(TSP,Tensor Streaming Processor),通过软件定义的数据流调度消除了传统GPU中的内存带宽瓶颈和调度不确定性。这使得LPU在推理延迟上具有显著优势,能够实现每秒数百token的生成速度,远超传统GPU方案。这代表了AI推理硬件从"通用GPU"向"专用推理芯片"演进的行业趋势。
第二条路径是模型效率优化技术的持续突破,包括模型量化(将高精度参数如FP16/FP32压缩为低精度表示如INT8/INT4,以大幅降低显存占用和计算需求,通常可将模型体积缩小2-4倍而精度损失极小)、知识蒸馏(用大模型的输出作为"软标签"训练小模型,使小模型获得接近大模型的能力)、稀疏注意力机制(如Flash Attention,通过优化GPU内存访问模式将注意力计算的内存复杂度从O(n²)降低到O(n)),以及推测解码(Speculative Decoding)等技术。推测解码是近年来备受关注的推理加速方法,其核心思想是让一个轻量级的"草稿模型"先快速生成多个候选token序列,然后由大模型通过一次并行前向传播来验证这些候选是否可接受。由于并行验证比逐个生成更高效,当草稿模型的预测准确率较高时(通常可达70-90%),整体推理速度可提升2-3倍而完全不损失输出质量。Google DeepMind和Meta等机构已在实际生产部署中广泛使用这一技术。
第三条路径是边缘计算的普及——将AI模型部署到用户终端设备上,苹果的Apple Intelligence正是这一路线的代表,通过在iPhone和Mac上本地运行小型语言模型(据报道参数规模约30亿)来减轻云端压力;高通(Snapdragon 8 Gen 3集成的Hexagon NPU)、联发科(天玑9300的APU)等芯片厂商也在积极推动端侧AI能力的提升,使得越来越多的AI任务可以在不依赖云端的情况下完成。
随着这些技术路径的逐步成熟,等待终将缩短。但在此之前,耐心或许是AI时代用户最需要具备的一项"技能"。
结语:等待不应成为体验AI的第一步
一条简短的吐槽推文,道出了无数AI产品用户的心声。当"排队等候"成为体验AI的第一步时,行业需要思考的不仅是技术问题,更是如何管理用户预期、如何在产能有限的情况下最大化用户满意度。毕竟,再强大的AI,如果用户等到失去兴趣,也就失去了它应有的意义。
相关推荐
OpenAI o3助力波士顿儿童医院攻克罕见遗传病诊断难题
OpenAI o3助力波士顿儿童医院攻克罕见遗传病诊断难题
OpenAI o3 Deep Research模型与波士顿儿童医院合作,通过AI深度推理辅助罕见遗传病诊断,研究成果发表于NEJM AI。了解这项人机协作如何缩短诊断周期、推动精准医学发展。
Cursor是什么?AI原生编程IDE核心特性与使用场景全解析
深度解析Cursor这款AI原生编程IDE,涵盖智能代码生成、多模型支持、上下文感知等核心特性,对比传统IDE的六大优势,帮助开发者了解谁适合使用Cursor以及如何提升编程效率。
Cursor Composer 2.5:开源模型强化训练登顶编程榜前三的秘密
Cursor基于Kimi K2开源模型强化训练推出Composer 2.5,编程基准测试跻身前三,超越原厂K2.6。深度解析Cursor数据飞轮、产品架构、定价方案及对AI编程行业的启示。