AI大模型原理详解:Transformer架构与测试实战指南
AI大模型离我们有多近?
很多人以为AI大模型是一个遥不可及的高科技概念,必须报专门的课程、在特定岗位才能使用。事实上,只要你能文字聊天,就能使用AI大模型。注册一个账号,你就可以用它来生成测试用例、评审需求、辅助设计方案。
本文将从AI大模型的基本概念、核心原理、优劣势分析,以及测试人员如何应对AI应用测试等多个维度,进行一次系统性的梳理。无论你是测试工程师、开发人员还是技术管理者,都能从中获得实用的认知框架。
AI大模型到底是什么?
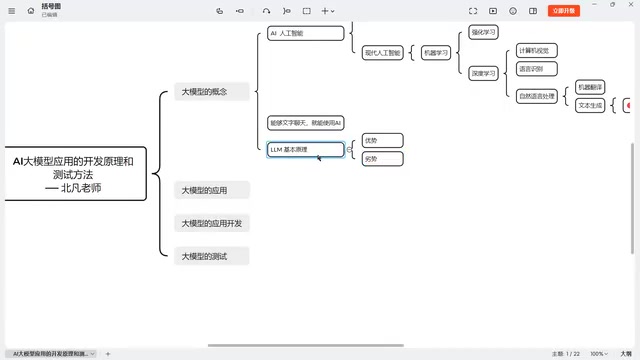
从人工智能到大语言模型的技术脉络
"AI大模型"这个说法其实并不精确。要真正理解它,我们需要先厘清技术层级关系:
- 人工智能(AI):最顶层的概念,涵盖所有让机器模拟人类智能的技术
- 机器学习:现代人工智能的主要实现路径
- 深度学习:机器学习中的一个重要分支
- 大语言模型(LLM):深度学习在自然语言处理领域的具体应用
机器学习的核心思想是让计算机从数据中自动学习规律,而不是由程序员手动编写每一条规则。深度学习则是机器学习中使用多层神经网络的方法,这些神经网络的结构灵感来源于人脑的神经元连接方式。层数越多、参数越多,模型就越"深",处理复杂模式的能力也越强。大语言模型之所以被称为"大",正是因为它们拥有数百亿甚至上万亿个参数,并且在互联网级别的海量文本数据上进行训练。
我们日常说的DeepSeek、ChatGPT、Gemini,狭义上指的就是大语言模型(LLM)。它并不是人工智能的全部,而是人工智能中一个非常具体的技术方向。
三大成熟的AI应用领域
目前人工智能应用比较成熟的领域主要有三个:
- 计算机视觉(CV):图形图像的理解与处理,如抖音的美颜滤镜、自动瘦脸、智能化妆等
- 语音识别(ASR):语音内容的理解,如智能音箱、语音转文字、甚至28元的智能声控灯
- 自然语言处理(NLP):文字语义的理解与生成,这正是大语言模型所在的领域
这三个领域各自走过了漫长的技术演进之路。计算机视觉领域的成熟得益于卷积神经网络(CNN)的突破,2012年AlexNet在ImageNet竞赛中大幅领先传统方法,标志着深度学习在图像识别领域的崛起。语音识别的发展则经历了从隐马尔可夫模型(HMM)到循环神经网络(RNN)再到端到端模型的演进过程,苹果Siri在2011年的发布让普通用户首次大规模接触语音AI。自然语言处理长期以来被认为是AI最难攻克的领域之一,因为人类语言充满了歧义、隐喻和文化背景,直到Transformer架构的出现才实现了质的飞跃。
计算机视觉和语音识别其实早已非常成熟,但它们有一个共同的问题——不方便普通人直接使用。视觉AI识别了图片内容,最终还是要通过文字告诉你结果;语音AI再厉害,跨语言沟通依然存在障碍。
直到大语言模型成熟,所有人都可以通过最自然的方式——打字聊天——来与AI交互,这才真正降低了AI的使用门槛。所以AI的爆发并非一夜之间,而是多年技术积累的集中释放。
Transformer:大模型的核心架构原理
从翻译任务理解Transformer架构
Transformer(转换器)是大语言模型的核心架构。它最初由Google提出,用于解决机器翻译问题。其工作流程可以简化为三个步骤:输入 → 模型处理 → 输出。
Transformer架构于2017年由Google团队在论文《Attention Is All You Need》中首次提出。在此之前,处理序列数据(如文本)主要依赖循环神经网络(RNN)和长短期记忆网络(LSTM),但它们有一个致命缺陷——必须逐词处理,无法并行计算,导致训练速度极慢。Transformer引入的自注意力机制(Self-Attention)彻底解决了这个问题,它允许模型同时关注输入序列中所有位置的信息,并自动判断哪些词之间的关联更重要。例如在处理"银行的河岸很陡峭"这句话时,注意力机制能够识别出"河岸"与"陡峭"的语义关联更强,从而正确理解"银行"在这里指的是河岸而非金融机构。
以翻译"I love you"为例:
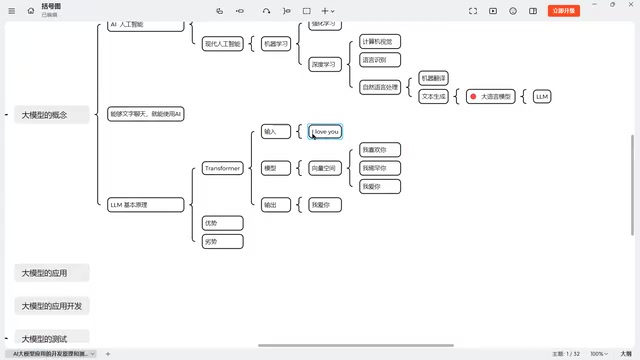
- 编码阶段:将输入的英文字符编码为数学向量,进入一个高维的"向量空间"
- 计算阶段:在向量空间中寻找语义相近的内容——"我爱你"、"我喜欢你"、"我稀罕你"、"我中意你"等不同表达,在语义层面都与"I love you"相近,因此它们在向量空间中的位置也是接近的
- 解码阶段:通过概率计算,逐字选择最可能的输出。比如第一个字"我"三个候选概率相当,到第二个字时"爱"的概率明显高于"喜"和"稀",最终输出"我爱你"
大模型的本质:基于概率的推算
理解了上述过程,我们就抓住了大模型最核心的本质——它的输出是概率性的,而非确定性的。
大模型在训练阶段的核心任务其实非常简单——预测下一个词。给定一段文本的前半部分,模型需要猜测接下来最可能出现什么词。通过在数万亿词汇的语料上反复进行这种预测训练,模型逐渐掌握了语言的语法结构、事实知识甚至推理能力。这种训练方式被称为"自回归语言建模"。值得注意的是,模型生成回答时有一个关键参数叫"温度"(Temperature):温度越低,模型越倾向于选择概率最高的词,输出越稳定但也越保守;温度越高,模型越愿意选择低概率的词,输出越有创造性但也越不可控。这就是为什么同一个问题有时得到严谨的回答,有时得到天马行空的答案。
这意味着:
- 同样的问题问100次,可能得到100个不同的回答
- 它不是从数据库中精确检索答案,而是根据概率"推测"最合理的下一个词
- 每次对话都是一次全新的概率计算过程
这个本质特征直接决定了大模型的优势与劣势。
大模型的优势与劣势分析
优势:创造性与多样性
正因为概率性的本质,大模型在以下场景表现出色:
- 文学创作:每次生成的内容都有变化,天然具备创造力和多样性
- 对话交互:回应丰富多变,不会像固定脚本那样千篇一律
- 发散性思维:能从不同角度审视问题,提供意想不到的视角
劣势:精确性与权威性不足
同样因为概率性本质,大模型在以下场景存在明显短板:
- 精密运算:让它解复杂方程,不如直接用计算器,这本质上不是它擅长的领域
- 权威准确回答:医疗诊断、法律咨询、金融财务等容不得出错的领域,大模型只能提供参考建议,不能作为最终依据
- 代码调试:在调试场景中,AI容易陷入"牛角尖",在错误方向上越走越远
测试人员如何应对AI应用测试?
AI在测试工作中的最佳应用场景
对于测试人员来说,大模型的概率特性恰恰是一种优势:
- 需求评审:AI可以从多个角度审视需求文档,发现人类容易忽略的边界条件和异常场景
- 测试用例设计:测试本身就需要考虑"千奇百怪、意想不到"的情况,大模型的发散性思维在这里大有用武之地
- 测试方案生成:快速生成多种测试策略供参考,显著提升工作效率
AI应用带来的测试新挑战
随着越来越多的公司围绕AI进行应用开发——AI口语陪练、AI客服、AI智能问答、AI IDE等,测试人员面临全新的挑战:
- 输出不确定性测试:同一输入可能产生不同输出,传统的"预期结果 vs 实际结果"的测试方法需要调整
- 概率质量评估:如何衡量AI输出的"好坏"?需要建立新的评估标准和指标体系
- 边界场景覆盖:AI应用的异常场景远比传统软件复杂,需要更系统的测试策略
- 安全与合规测试:确保AI不会在医疗、法律等敏感领域给出误导性的"权威"回答
传统软件测试建立在确定性逻辑之上——给定输入A,必然得到输出B,测试通过与否一目了然。但AI应用的测试需要全新的思维方式。业界目前正在探索的评估方法包括:基于人工标注的评分体系(如让标注员对AI回答从1-5分打分)、自动化评估指标(如BLEU分数衡量翻译质量、ROUGE分数衡量摘要质量)、以及用另一个AI来评判AI输出质量的"LLM-as-Judge"方法。此外,AI安全测试已成为一个独立的技术方向,包括对抗性测试(故意输入诱导性问题测试模型是否会产生有害输出)、幻觉检测(识别AI编造不存在的事实)以及偏见审计(检测模型是否对特定群体存在歧视性输出)。
提升AI使用效果的关键技巧
虽然"能文字聊天就能用AI",但使用效果差异巨大。核心技巧在于:
- 明确上下文:提供足够的背景信息,让AI理解你的具体场景
- 善用优势领域:将AI用在创造性、发散性任务上,而非精确计算
- 迭代优化:不要期望一次对话就得到完美结果,通过多轮交互逐步逼近目标
- 结果验证:AI的输出永远是参考,关键决策仍需人工判断
总结
AI大模型(LLM)是深度学习在自然语言处理领域的重要突破,其核心是基于Transformer架构的概率推算。理解这一本质,我们就能扬长避短:在创造性任务中充分发挥它的优势,在精确性要求高的场景中保持审慎。
对于测试人员而言,这既是工具升级的机遇——用AI提升需求评审和用例设计的效率,也是职业发展的新方向——掌握AI应用测试的方法论,在这个快速发展的领域中占据先机。
核心要点
相关推荐
Ayanna Howard出任Spelman学院校长:AI机器人专家掌舵黑人女子学院
AI与机器人领域杰出学者Ayanna Howard被任命为Spelman学院校长,从NASA到佐治亚理工院长再到HBCU掌门人,她的任命标志着STEM教育与多元化发展的深度融合。
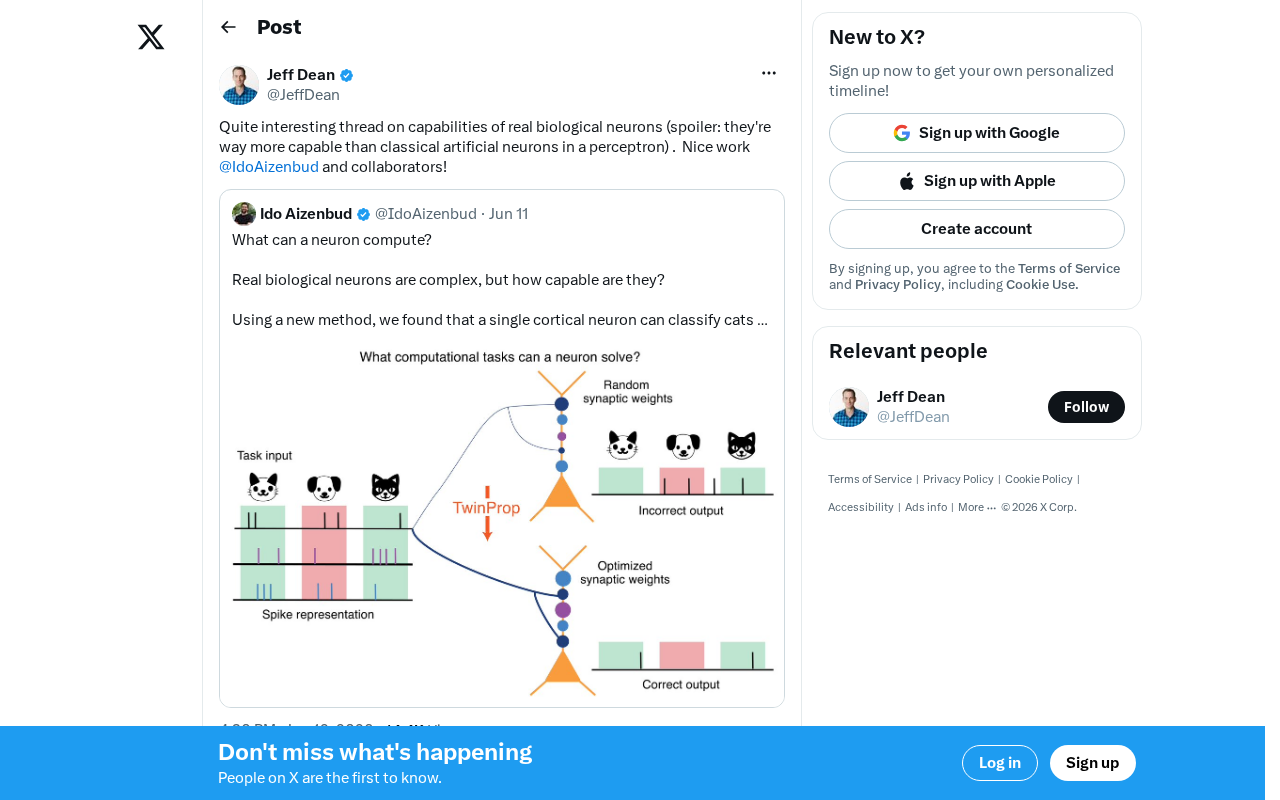
生物神经元vs人工神经元:计算能力差距有多大?
最新研究表明,生物神经元的计算能力远超经典人工神经元。本文深入解析树突计算、时间编码等生物机制,探讨其对下一代AI架构设计的深远启示,以及为何大脑仅用20瓦功耗就能完成复杂智能任务。
Anthropic投入2500万美元Computer Use积分,AI Agent赋能美国小企业
Anthropic宣布提供2500万美元Computer Use计算积分,支持美国小企业利用AI Agent加速发展。本文解析这一举措背后的战略意图、Computer Use应用场景,以及对AI Agent生态竞争格局的深远影响。