生物神经元vs人工神经元:计算能力差距有多大?
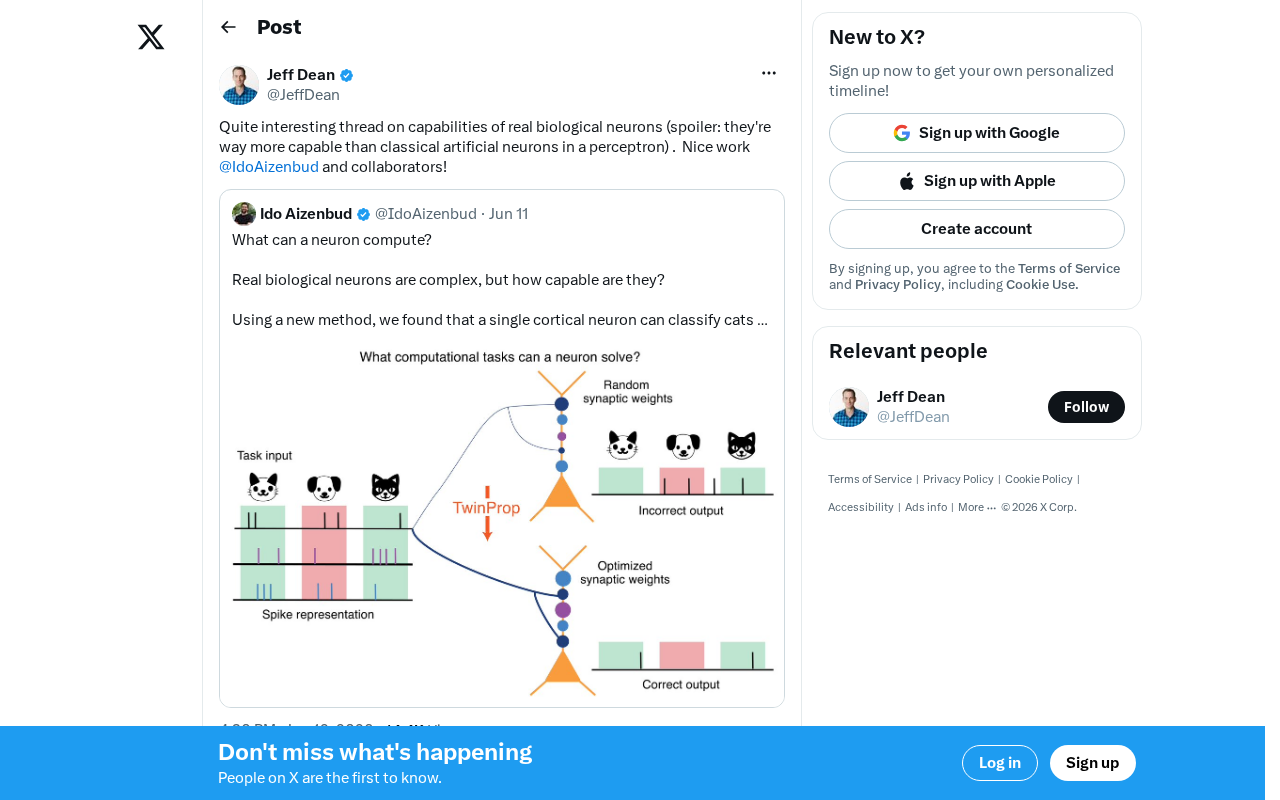
引言:我们真的理解神经元吗?
深度学习席卷全球的今天,人工神经网络(ANN)已经在图像识别、自然语言处理等领域取得了令人瞩目的成就。然而,一个长期被忽视的问题正在重新引发学术界的关注:真实的生物神经元,究竟比经典人工神经元强大多少?
研究者 Ido Aizenbud 及其合作者发表的一项研究给出了令人震撼的结论——生物神经元的计算能力远远超出经典人工神经元模型所能表达的范畴。这不仅是一个神经科学问题,更可能深刻影响下一代AI架构的设计方向。
经典人工神经元:一个沿用近70年的简化模型
感知器的历史局限
现代深度学习中使用的人工神经元,核心模型可以追溯到1957年 Frank Rosenblatt 提出的感知器(Perceptron)。这个模型将神经元抽象为一个极其简单的计算单元:接收多个输入信号,进行加权求和,再通过一个激活函数输出结果。
事实上,感知器的思想根源可以追溯到更早的1943年。神经科学家Warren McCulloch和逻辑学家Walter Pitts提出了第一个数学化的神经元模型——McCulloch-Pitts(MCP)模型,将神经元视为一个二值逻辑门:接收0或1的输入,当加权输入之和超过某个阈值时输出1,否则输出0。Rosenblatt在此基础上增加了可学习的权重调整机制,使感知器具备了从数据中自动学习的能力。值得注意的是,1969年Minsky和Papert在《Perceptrons》一书中证明了单层感知器无法解决异或(XOR)等线性不可分问题,这一结论直接导致了长达十余年的"AI寒冬"。直到反向传播算法的普及和多层网络的出现,神经网络研究才重新复兴。
这种"点积+非线性"的范式已经沿用了近70年。尽管网络架构层面经历了大量创新——从卷积网络到Transformer——但单个神经元的计算模型几乎没有本质变化。它本质上是一个线性分类器加上简单的非线性变换。
简化带来的代价
这种简化在工程上无疑是成功的,因为它使大规模并行计算成为可能。但从生物学角度看,这种模型丢失了大量关键信息。真实的生物神经元并非简单的"开关"或"加权求和器",它们是拥有复杂树突结构的微型计算系统。
生物神经元的真实计算能力:远不止"加权求和"
树突本身就是一台微型计算机
传统观点将树突(dendrite)视为简单的信号传输通道,就像连接到神经元胞体的电线。但越来越多的研究表明,单根树突本身就能执行复杂的非线性计算。树突上的不同分支可以独立处理信息,进行局部的信号整合和非线性变换,然后再将结果传递给胞体。
树突的计算能力源于其复杂的生物物理特性。树突并非被动的电缆,而是分布着大量电压门控离子通道(如钠通道、钙通道和钾通道)。这些离子通道使树突能够产生局部的电信号——称为树突棘电位(dendritic spike)。2003年,伦敦大学学院的Michael Häusser实验室利用双光子成像技术直接观察到了树突分支上的局部钙信号,证实了单根树突可以独立执行与(AND)、或(OR)等逻辑运算。更近期的研究表明,人类皮层锥体神经元的树突甚至能执行一种名为XOR的逻辑运算——这恰恰是单层感知器被证明无法完成的任务。这意味着单个生物神经元在计算复杂度上已经超越了单层人工神经网络。
这意味着一个生物神经元的计算能力,可能相当于一个多层人工神经网络,而非单个人工神经元。
时间维度:被人工神经元忽略的关键信息
生物神经元还利用了一个人工神经元几乎完全忽略的维度:时间。脉冲的精确时序、突触的短期可塑性、膜电位的动态变化,这些都携带着丰富的计算信息。经典的人工神经元模型是静态的——它处理的是一个固定的输入向量,而生物神经元则在持续的时间流中进行动态计算。
多种突触机制协同工作
生物神经元拥有兴奋性和抑制性等多种类型的突触,且这些突触的位置、强度和动态特性各不相同。突触可塑性规则也远比简单的梯度下降复杂,包括:
- 脉冲时序依赖可塑性(STDP):根据前后神经元放电的时间差调整突触强度。STDP最早由纽约大学的Guo-qiang Bi和Mu-ming Poo于1998年在培养的海马神经元中系统性地发现并描述。其核心规则出奇地优雅:如果突触前神经元在突触后神经元之前放电(因果关系),突触强度增强(长时程增强,LTP);如果顺序相反,突触强度减弱(长时程抑制,LTD)。增强或减弱的幅度取决于两者放电的时间间隔,通常在几十毫秒的窗口内。STDP被认为是Hebb学习规则("一起放电的神经元连在一起")在时间维度上的精确化版本,它为大脑如何在无监督条件下学习因果关系和时序模式提供了生物学基础。与深度学习中依赖全局误差信号的反向传播不同,STDP是一种完全局部的学习规则,仅依赖突触前后两个神经元的活动信息。
- 突触标签与捕获机制:实现短期记忆向长期记忆的转化
- 多种局部学习规则:在不同树突分支上独立运行
对AI发展的深远启示
我们是否在用低效方式弥补单元能力的不足?
Aizenbud 等人的研究提出了一个根本性问题:如果基本计算单元就是过度简化的,那么我们是否一直在用堆叠网络层数的方式来弥补单元能力的不足?
当前大语言模型动辄数千亿参数,需要消耗巨大的计算资源。而人类大脑仅用约860亿个神经元和约20瓦的功耗,就能完成远比当前AI更通用的智能任务。这种效率差距可以通过具体数字来感受:训练GPT-4据估计消耗了约50-100吉瓦时(GWh)的电能,相当于约1万个美国家庭一年的用电量;单次推理中,一个千亿参数模型在GPU集群上的功耗约为数百瓦到数千瓦。而人脑的总功耗仅约20瓦——与一个普通LED灯泡相当。在单位能耗的计算效率上,人脑每秒每瓦可执行约10^13次突触操作,而当前最先进的AI芯片(如NVIDIA H100)每秒每瓦约执行10^12次等效操作。更关键的差距在于通用性:人脑用20瓦即可同时处理视觉、语言、运动控制、情感和创造性思维,而当前AI系统通常只能在单一或少数任务上表现出色,且每个任务都需要独立的大规模模型。这种效率差距的一个重要原因,可能就在于单个计算单元的能力差异。
正在探索中的新型神经元模型
学术界已经开始探索更接近生物真实性的神经元模型,主要方向包括:
- 树突神经网络:在人工神经元中引入树突结构,使单个神经元具备多层计算能力
- 脉冲神经网络(SNN):引入时间维度,用脉冲时序编码信息,更接近大脑的工作方式。SNN被称为"第三代神经网络",其核心优势在于事件驱动的计算模式——神经元只在接收到脉冲时才进行计算,而非像传统ANN那样在每个时间步对所有神经元进行前向传播。这种稀疏计算特性使SNN在理论上具有极高的能效比。目前已有多款专用神经形态芯片问世:Intel的Loihi 2集成了100万个神经元核心,支持片上学习;IBM的TrueNorth包含54亿个晶体管模拟100万个神经元;此外还有英国曼彻斯特大学的SpiNNaker 2等学术项目。2024年,基于SNN的模型已在特定任务上(如手势识别、关键词检测)展现出比传统ANN低10-100倍功耗的优势。然而,SNN在训练效率和大规模任务上仍面临挑战,主要瓶颈在于脉冲信号的不可微性使得传统反向传播算法难以直接应用,研究者正在通过替代梯度(surrogate gradient)等方法寻求突破。
- 动态神经元模型:如 Izhikevich 模型,能够复现多种生物神经元的放电模式
这些方向虽然尚未在工程应用中全面超越传统模型,但它们代表了一种重要的思路转变——从"堆参数"转向"提升单元计算密度"。
生物真实性与工程可行性的平衡
经典人工神经元的简单性并非毫无价值。正是因为它足够简单,才能在GPU上实现大规模并行计算,才有了今天深度学习的繁荣。生物真实性和工程可行性之间的平衡,是这一领域需要持续探索的核心问题。
未来的突破可能不在于完全复制生物神经元的复杂性,而在于找到那些关键的、被忽略的计算原语,将它们以硬件友好的方式融入人工神经网络。这需要神经科学家、计算机科学家和硬件工程师的深度协作。
结语:下一个范式转移的方向
从感知器到Transformer,AI的进步主要发生在网络架构层面,而单个神经元的计算模型几乎未变。Aizenbud 等人的研究再次提醒我们:大自然经过数亿年进化打磨的生物神经元,蕴含着远比当前模型更丰富的计算智慧。
当我们为大语言模型的能力惊叹时,或许也应该思考:如果每个计算单元都能像生物神经元一样强大,我们还需要万亿参数吗?这个问题的答案,可能指向AI发展的下一个范式转移。
相关推荐
Claude Fable 5作为Computer Use编排模型:长时间Agent工作流表现出色
Anthropic向Pro和Max用户开放Claude Fable 5作为Computer Use编排模型,在长时间Agent工作流中表现优异,支持自动化数据处理、软件测试等多种应用场景。
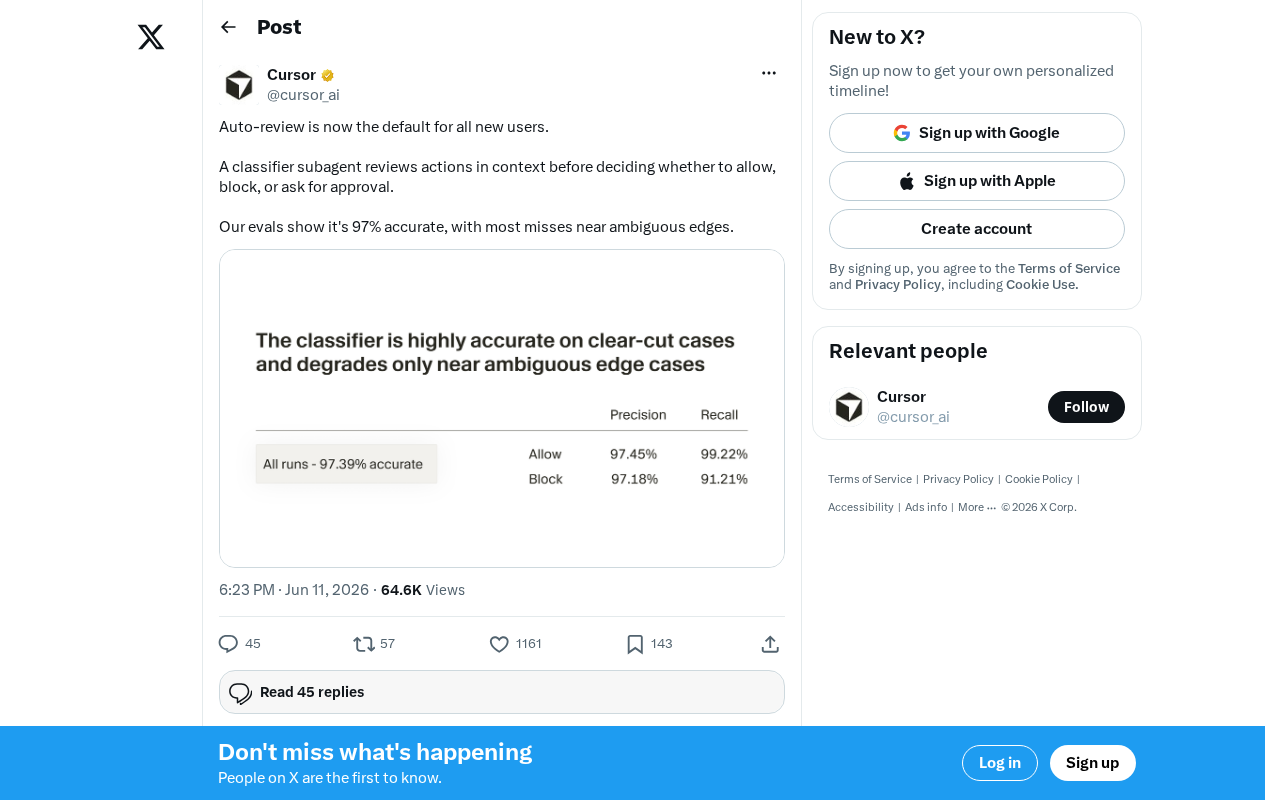
AI自动审查成为默认机制:97%准确率的子代理分类器如何工作
AI代理自动审查机制全面上线,分类器子代理以97%准确率对每个操作进行三级安全决策。深入解析其工作原理、上下文感知技术、误判边界及对AI代理安全范式的深远影响。

Android Studio Gemini用量限制提升:Pro/Ultra订阅用户获更高配额
Google宣布Android Studio中Gemini用量限制提升,Google AI Pro和Ultra订阅用户自动获得更高token配额,支持长时间Agentic开发会话,无需额外配置即可生效。