AI代码审查从30分到80分:AST+RAG架构核心难点全解析

通过AST、RAG和向量数据库突破AI代码审查系统的核心瓶颈
基础AI代码审查系统虽易搭建,但面临长上下文处理不足和代码依赖关系理解缺失两大瓶颈。文章提出通过AST语法树解析提炼项目代码摘要、RAG检索增强生成获取依赖上下文、向量数据库存储结构化知识三大技术手段,结合专有安全漏洞检测工具和知识持续更新机制,将AI代码审查能力从30%提升至70%-80%。
搭建一个基础的AI代码审查系统并不难,它或许能解决30%的问题、提升30%的效率。但要将这个数字提升到70%甚至80%,真正的挑战才刚刚开始。本文将深入分析AI代码审查系统面临的核心难点,以及如何通过AST解析、RAG检索和向量数据库等技术手段构建更强大的代码审查智能体。
基础AI代码审查系统的局限在哪里
一个简单版本的AI代码审查系统,对于熟悉LangGraph或LangChain的开发者来说,两三个小时就能搭建完成。LangChain是目前最流行的LLM应用开发框架之一,它提供了Prompt模板、链式调用、工具集成、记忆管理等一系列抽象,帮助开发者快速构建基于大模型的应用。而LangGraph则是LangChain团队推出的扩展库,专注于构建有状态的、多步骤的AI Agent工作流——它基于有向图的概念,允许开发者定义节点(处理步骤)和边(流转条件),支持循环、条件分支和并行执行,非常适合编排AST解析、RAG检索、多模型协作等多个步骤的复杂执行流程。
但这样快速搭建的系统存在两个根本性问题:
第一,长上下文处理能力不足。 当一个PR包含几千行代码变更时,大模型的上下文窗口可能无法完整消化所有信息。虽然这种情况在规范的开发流程中不常出现,但它确实是一个需要考虑的边界场景。
第二,也是更关键的问题——代码依赖关系的理解。 一个项目小则几万行,大则几十万、上百万甚至千万行代码。仅凭PR中的代码片段进行审查,AI根本无法理解这段代码在整个项目中的真实含义。涉及业务逻辑或复杂调用链时,脱离项目上下文的审查几乎没有意义。
这就引出了核心问题:如何让AI大模型在审核PR时,能够结合整个项目代码库进行审查?
AST语法树:理解代码结构的基石
要解决项目级别的代码理解问题,首先需要了解AST(抽象语法树)。AST是编译原理中的核心概念,几乎所有现代编程语言的编译器或解释器都以AST作为中间表示。当源代码被解析时,词法分析器(Lexer)首先将字符流拆分为Token序列,然后语法分析器(Parser)根据语言的文法规则将Token序列组织成树状结构。这棵树省略了括号、分号等对语义无关的符号,只保留程序的逻辑结构。例如,一条赋值语句 int x = a + b; 会被解析为一个声明节点,其子节点包含类型、变量名和一个二元运算表达式。
所有编程语言在设计时都基于AST进行解析——代码的结构和规则被抽象成树状结构,每个节点代表一种语法规则。在代码审查场景中,AST的价值在于它提供了一种与具体语法风格无关的、结构化的代码表示方式,使得跨文件的依赖分析、调用链追踪和模式匹配成为可能。常见的AST解析工具包括Python的ast模块、JavaScript的Babel Parser、Java的Eclipse JDT和JavaParser等。
AST有一个非常重要的特性:信息压缩。以SQL语言为例,其语法树构建出来大概在一千行左右(标准SQL,不含方言);TypeScript、Java等常规编程语言的语法树通常在一两千行左右。这个量级完全在AI大模型的理解范围之内。
不过,我们使用AST的目的并不是让AI理解语法本身——通用大模型已经具备这个能力。真正的用途是通过AST对整个项目代码库进行提炼和摘要。
基于AST的代码摘要策略
假设代码库有十万行代码、一千个类、两千个方法,直接让AI处理显然不现实。解决方案分为以下几步:
- 通过AST解析,将所有类、方法及其注释抽离出来
- 形成结构化摘要,存入向量数据库
- 新PR到来时,再次通过AST解析PR代码,分析其依赖了哪些外部类、方法、变量
- 通过RAG检索,从向量数据库中获取相关依赖的摘要信息
- 组合完整上下文,交给AI大模型进行审查
这正是Cursor、字节Trae等AI编程工具的底层机制——它们需要对整个项目不断提取、不断形成摘要,从而在给出建议时能够结合多文件上下文。
完整架构设计:从代码库到智能审查的两条主线
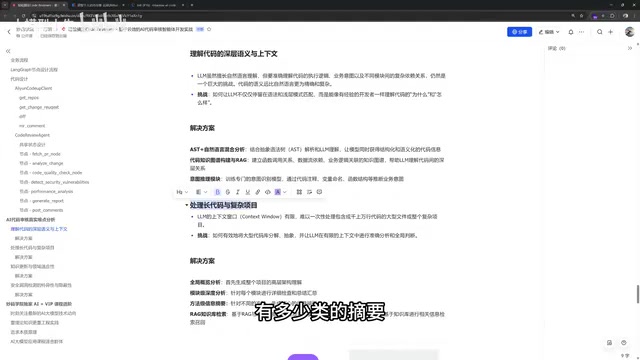
整个AI代码审查系统可以分为左右两条主线:
PR审查主流程
从Codebase中获取代码片段(PR形式),经过以下处理:
- AST分解:提取代码的引用关系,识别依赖了哪个类、哪个库
- Retriever检索:从向量数据库中获取相关依赖的参数、注释、业务含义等摘要信息
- AI大模型分析:将PR代码 + 依赖上下文一起送入大模型进行深度审查
这里的检索环节采用的正是RAG(Retrieval-Augmented Generation,检索增强生成)架构。RAG由Meta AI在2020年提出,其核心思想是在生成回答之前,先从外部知识库中检索与当前查询最相关的文档片段,然后将这些片段作为上下文拼接到Prompt中,引导大模型基于真实数据进行推理。RAG的典型流程包括三个阶段:索引(Indexing)——将文档切片并通过Embedding模型转化为向量存入数据库;检索(Retrieval)——将用户查询同样向量化后进行相似度搜索;生成(Generation)——将检索到的上下文与原始问题一起送入LLM。在代码审查场景中,RAG使得AI能够在审查PR时动态获取项目中相关类、方法的文档和签名信息,而无需将整个代码库塞入上下文窗口。
知识库构建流程
这是一个独立的后台程序,负责持续维护向量数据库:
- AST语法解析:扫描项目代码,找出所有方法、类和注释
- AI智能体加工:对提取的信息进行进一步处理——文档写得不好的补充更好的文档,没有文档的自动生成文档摘要
- 定时同步:通过定时任务将处理后的数据输入向量数据库
这里的向量数据库是整个系统的核心存储组件。向量数据库是专门为高维向量的存储、索引和近似最近邻(ANN)搜索而设计的数据库系统。与传统关系型数据库基于精确匹配不同,向量数据库通过余弦相似度、欧氏距离等度量方式进行语义级别的模糊检索。当文本或代码片段通过Embedding模型(如OpenAI的text-embedding-ada-002、BGE等)转化为高维浮点向量后,语义相近的内容在向量空间中会彼此靠近。主流的向量数据库包括Pinecone、Weaviate、Milvus、Qdrant和Chroma等,它们通常采用HNSW(Hierarchical Navigable Small World)、IVF(Inverted File Index)等索引算法来加速检索,能够在毫秒级时间内从数万个代码片段中找到与当前PR最相关的依赖信息。
这套机制能让系统从解决30%的问题提升到解决50%-60%的问题。
安全漏洞检测:通用大模型的明显短板
在安全检测领域,通用大模型只能分析出浅层次的问题。对于深层漏洞或最新披露的安全风险,大模型几乎无能为力。
代码安全漏洞检测在软件工程中有着悠久的历史,传统工具分为SAST(静态应用安全测试)和DAST(动态应用安全测试)两大类。SAST工具如SonarQube、Checkmarx、Fortify等在不运行代码的情况下通过分析源代码或字节码来发现潜在漏洞,其核心技术包括数据流分析、污点追踪(Taint Analysis)和模式匹配。OWASP(开放式Web应用安全项目)维护着Top 10安全风险清单,涵盖注入攻击、身份认证失效、敏感数据暴露等常见威胁。CVE(Common Vulnerabilities and Exposures)数据库则是全球最权威的漏洞编号系统,每天都有新的漏洞被披露和收录。
传统方案:风险库 + 模式匹配
专业安全公司会沉淀一个庞大的风险库,包含各类隐藏漏洞和问题代码模式。当新代码提交时,通过AST解析进行模式匹配,将代码结构与风险库比对,发现匹配项即标记风险。
AI时代方案:专有风险模型
部分公司开始训练专门的风险分析模型,灌注大量漏洞数据,实现更智能的漏洞检测。但由于新漏洞每天都在披露(阿里云、腾讯云等平台持续更新),任何模型都无法做到实时覆盖。近年来,GitHub的Dependabot、Snyk等工具也开始利用AI技术进行依赖项漏洞扫描和自动修复建议,但对于零日漏洞(Zero-day)和复杂的业务逻辑漏洞,仍然需要专业安全团队和专有工具的介入。
最佳实践是双管齐下:一个持续更新的风险库 + 一个强大的风险分析模型,两者协同工作。这部分通常需要商业付费的专有工具,不建议纳入通用大模型的职责范围。
知识更新:系统持续演进的挑战

知识更新是AI代码审查系统面临的另一个棘手问题:
- 新框架版本:当项目升级到某个框架的最新版本,AI大模型可能完全不了解新特性
- 新语法特性:编程语言发布新语法,不更新知识库就无法正确识别
- 新编程范式:行业最佳实践在不断演进
知识更新的应对策略
方案一:构建可更新的知识图谱或向量数据库,定期同步编程语言特性和框架更新。但维护成本高,且RAG召回的上下文过多时反而会适得其反。
方案二:将关键知识微调到基础模型中。模型微调(Fine-tuning)是指在预训练大模型的基础上,使用特定领域的数据集进行进一步训练,使模型获得该领域的专业能力。常见的微调方法包括全参数微调(Full Fine-tuning)、LoRA(Low-Rank Adaptation)和QLoRA等。其中LoRA通过在模型权重矩阵中注入低秩分解矩阵,仅训练极少量参数(通常不到原模型的1%),大幅降低了微调的计算成本和显存需求。在代码审查场景中,微调可以将特定框架的API规范、团队编码规范、历史审查意见等知识直接编码到模型参数中,使其在推理时无需额外检索即可调用这些知识。但微调的局限在于知识更新不够灵活——每次遇到新框架、新知识都需要重新训练,且存在灾难性遗忘的风险。因此,业界通常将RAG(处理动态知识)和微调(处理稳定的领域知识)结合使用,成本同样不低。
务实建议:在项目中选择相对稳定的技术栈版本,避免频繁升级带来的知识同步压力。大型公司通常不会轻易更换软件版本,除非有不可回避的必要性。对于确实难以解决的边缘场景,可以适当忽略,将精力集中在高频、高价值的审查场景上。
总结:三个维度突破AI代码审查瓶颈
构建一个从30分进化到80分的AI代码审查系统,核心在于三个维度的突破:
- 项目级上下文理解:通过AST + RAG + 向量数据库,让AI能够结合整个代码库进行审查
- 安全漏洞检测:结合传统风险库和专有风险模型,弥补通用大模型在安全领域的不足
- 知识持续更新:建立知识维护机制,保持系统对新技术、新框架的感知能力
简单版本两三个小时就能搞定,但要真正解决核心问题,需要在RAG架构设计、AST解析优化、向量数据库索引策略等方面持续投入。字节等大厂内部已经在使用自研的AI代码审核系统,这条路径的价值已经得到了充分验证。
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。