AI对齐的本质:对齐What to do而非How to do

AI对齐应聚焦"做什么"而非"怎么做",后者应沉淀为Harness规范。
文章提出AI工程化中的对齐核心原则:与AI对齐"What to do"(业务场景、目标、意图),而将"How to do"(标准流程、技能模块、编码规范)沉淀为Harness约束框架。通过数据库迁移案例说明,人负责决策做什么,Harness告诉AI按什么标准做,AI负责执行。当Harness体系足够完善并结合多智能体架构,可实现端到端全自动化开发。
在AI工程化落地的过程中,"AI与人的对齐"是一个被频繁提及却常常被误解的概念。在学术界,AI对齐(AI Alignment)通常指确保AI系统的行为与人类的价值观、意图和目标保持一致,是OpenAI、Anthropic、DeepMind等机构重点投入的AI安全研究方向,主要关注超级智能可能带来的存在性风险。而在工程实践中,"对齐"的含义更加具体——它不是哲学层面的价值对齐,而是工作流层面的意图对齐:如何让AI准确理解开发者的需求并正确执行。RLHF(基于人类反馈的强化学习)解决的是模型层面的通用对齐,而我们在工程中要解决的,是项目层面的专属对齐问题。
不少开发者在使用AI辅助编程时,习惯事无巨细地告诉AI每一步该怎么做——从变量命名到循环写法,恨不得把伪代码都写好再交给AI翻译。结果呢?效率没提上去,返工倒是一轮接一轮。
问题出在哪?出在对齐的方向搞反了。
AI到底需要跟人对齐什么内容?本文将从一个数据库迁移的实际案例出发,深入探讨AI对齐的核心原则——对齐What to do,而非How to do。
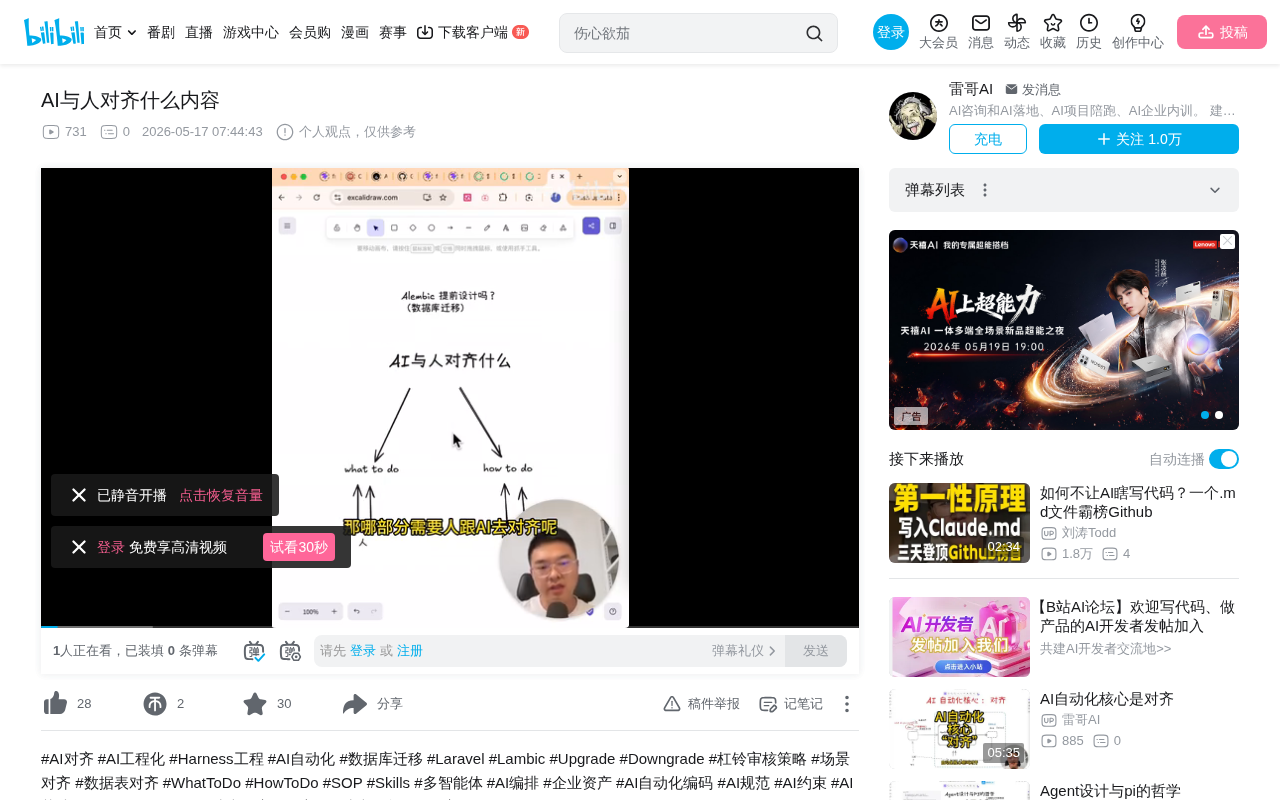
从数据库迁移看AI对齐的边界
以Python生态中常见的Alembic数据库迁移框架为例。Alembic是SQLAlchemy生态中的数据库迁移工具,由SQLAlchemy的作者Mike Bayer开发,其核心理念是将数据库的Schema变更(如建表、加字段、改索引)以版本化的迁移脚本形式管理,类似于Git对代码的版本控制。在Django的Migrations、Rails的ActiveRecord Migration中也有类似的实现,这种模式已经成为现代Web开发的标准实践。Alembic提供了upgrade和downgrade两个核心操作,用于管理数据库版本的前进和回退——每个迁移脚本都包含这两个函数,确保数据库变更可追溯、可回滚,并且通常与CI/CD流水线集成,实现数据库变更的自动化部署。
当我们进行建表操作时,通过"杠铃策略"来审视这个过程,会发现杠铃的两端分别是业务场景和数据表结构。这里的"杠铃策略"(Barbell Strategy)最早由风险学者纳西姆·塔勒布在《反脆弱》一书中提出,原本用于描述投资中同时持有极端保守和极端激进资产、避开中间地带的策略。在AI工程化语境中,它被借用来描述一种分析框架:关注问题的两个极端——一端是高度确定的、可标准化的部分(如框架的固定用法),另一端是高度不确定的、需要人类判断的部分(如业务决策)。通过识别杠铃的两端,开发者可以清晰地划分哪些工作应该交给AI自动完成,哪些必须由人来决策。
这里有一个关键问题:建表时的字段设计、表结构定义,这些内容需要跟AI对齐吗?
答案是需要的,因为这些跟具体的业务场景直接相关,AI无法凭空推断你的业务需求。用户表该有哪些字段、订单表和商品表之间是什么关联关系——这些决策只有你自己清楚。
但是,Alembic的upgrade和downgrade迁移脚本的生成逻辑呢?结论是:这部分不需要对齐。迁移脚本的生成是一个标准化的、可规范化的流程,AI完全有能力按照既定规则自主完成。你只需要告诉它"建一张用户表,包含这些字段",至于怎么写op.create_table()、怎么处理downgrade中的op.drop_table(),AI自己就能搞定。
这个案例恰好揭示了AI对齐中最关键的边界划分问题。
AI对齐的核心原则:What to do vs How to do
上面的数据库迁移案例揭示了AI对齐的核心原则——区分"做什么"和"怎么做"。
AI不知道的是"做什么"(What to do)
AI跟人对齐的本质,是解决AI"不知道的东西"。而AI真正不知道的是What to do——要去做什么。具体来说:
- 场景对齐:你的业务场景是什么,要解决什么问题
- 目标对齐:最终要达成的结果是什么,比如数据表的最终结构
- 意图对齐:为什么要做这件事,背后的业务逻辑是什么
这些信息是AI无法自行推断的,必须由人来明确传达。你不说清楚要建什么表、表之间什么关系、字段有哪些约束,AI再聪明也只能猜。这本质上是一个信息传递效率问题——如何用最少的沟通成本,让AI获得完成任务所需的充分信息。
AI擅长的是"怎么做"(How to do)
而How to do——如何去做——恰恰是AI的强项。这部分内容可以被规范化为:
- SOP(标准操作流程):固定的执行步骤,比如迁移脚本的生成流程。SOP源自制造业和医疗行业的质量管理体系,指将重复性工作分解为明确的、可执行的步骤序列。在AI辅助编程中,SOP被转化为AI可读取的结构化指令,例如"创建API端点时,先定义路由→编写请求验证→实现业务逻辑→添加错误处理→编写单元测试"。
- Skills(技能模块):可复用的能力单元,比如特定框架的代码生成模板。Skills是更细粒度的能力模块,类似于微服务架构中的单一职责原则——每个Skill封装一项特定能力,如"生成RESTful CRUD代码"或"编写Pytest测试用例"。SOP定义流程骨架,Skills填充每个步骤的具体执行能力,两者组合构成了Harness体系的核心执行层。
- 约束与规范:代码风格、架构规范、命名约定等
这些规范化的内容,最终会形成一个叫做**Harness(约束框架)**的体系。AI读取这些规范后,结合与人对齐的"做什么",就能自主完成具体的执行工作。
换句话说,你负责拍板"做什么",Harness负责告诉AI"按什么标准做",AI负责动手干活。三方各司其职,效率自然就上来了。
Harness工程:从AI对齐到自动化编程的桥梁
什么是Harness工程
Harness本质上是将所有"How to do"的知识沉淀为结构化的规范体系。当你把大量的"怎么做"都形成规范之后,这些规范就成为了一种工程资产——无论是企业级的还是个人的研发资产。
简单来说,Harness工程就是把团队积累的最佳实践、编码规范、架构模式等"怎么做"的经验,转化为AI可以直接读取和执行的结构化文档。这不是写给人看的Wiki,而是写给AI读的"操作手册"。这一点至关重要——传统的技术文档面向人类读者,允许模糊表述和隐含假设;而Harness文档面向AI执行者,要求每条规范都足够明确、无歧义、可机器解析。从某种意义上说,编写Harness文档更接近于编程而非写作。
举个例子:你的团队规定所有数据库迁移必须包含回滚脚本、所有API必须遵循RESTful规范、所有异常处理必须记录结构化日志——这些规则一旦沉淀进Harness,AI在执行任务时就会自动遵守,不需要你每次都重复交代。
Harness工程的核心价值
Harness工程之所以重要,在于它打通了AI全自动化编程的最后一环。整个逻辑链条是这样的:
- 人与AI对齐What to do:明确要做什么
- Harness提供How to do:告诉AI按什么规范去做
- AI自主执行:结合目标和规范,完成具体工作
当Harness足够完善时,一个功能的开发就可以完全通过自动化流程来完成,大幅提升AI辅助编程的效率和质量。你不再需要盯着AI的每一行输出做code review,因为规范已经内置在流程里了。
从单体到多智能体架构的演进
更进一步,当我们将AI自动化编程从单体模式升级为多智能体并发架构时,Harness的价值会被进一步放大。
多智能体(Multi-Agent)架构是当前AI工程领域的前沿方向,其核心思想是将一个复杂任务分解为多个子任务,由不同的AI智能体并行或协作完成。典型的框架包括微软的AutoGen、CrewAI、LangGraph等。每个智能体可以拥有不同的角色定义(如架构师Agent、编码Agent、测试Agent)、不同的工具集和不同的上下文窗口。相比单一大模型处理所有任务,多智能体架构的优势在于:降低单次推理的复杂度、支持并行处理提升速度、通过角色分工提高输出质量。但其挑战在于智能体间的协调成本——如何确保多个Agent的输出风格一致、接口兼容、不产生冲突,这正是Harness体系要解决的核心问题之一。
每个智能体负责解决一个拆分后的小问题,而Harness确保每个智能体都按照统一的规范执行。这样一来:
- AI的能力解决了问题拆分后的小任务
- Harness解决了规范性问题
- 有效的对齐确保了方向正确
三者结合,就能实现端到端的全自动化开发流程。一个需求进来,经过任务拆分、分配给多个智能体并行处理、最后汇总输出——整个过程中,人只需要在最开始把"做什么"说清楚就行。
实践建议:如何落地AI对齐策略
基于以上分析,在实际的AI工程化落地中,建议遵循以下原则:
- 识别对齐边界:拿到一个任务,先问自己——哪些是场景相关的(需要对齐),哪些是流程相关的(沉淀为Harness规范)。分不清的时候,想想这个信息AI能不能从已有规范中推导出来,能推导的就不用对齐。一个实用的判断标准是:如果换一个完全不同的业务场景,这条信息还成立吗?如果成立,它大概率属于"How",应该沉淀为Harness;如果不成立,它就是"What",需要每次对齐。
- 持续沉淀Harness:每次发现一个"How to do"的模式,就将其规范化,纳入Harness体系。这是一个渐进的过程,不要指望一步到位,但要保持积累的习惯。可以从最高频的重复性工作开始——比如项目初始化流程、CRUD接口生成、单元测试编写模板等,这些往往是投入产出比最高的Harness沉淀点。
- 聚焦What to do的表达:把精力花在如何更清晰地向AI传达意图和目标上,而不是手把手教AI写代码。描述越精准,AI的输出质量越高。好的What to do表达应该包含三个要素:业务背景(为什么做)、期望结果(做成什么样)、验收标准(怎么算做好了)。
- 特殊情况特殊处理:某些技术选型(如多智能体编排方式)虽然看似是"How",但因为直接影响架构决策,应当作为"What to do"来对齐。边界不是死的,需要根据实际情况灵活判断。
总结
AI与人的对齐,核心在于对齐What to do而非How to do。将"怎么做"沉淀为Harness规范,让AI在明确目标后自主按规范执行,这才是AI工程化落地的正确路径。
随着Harness体系的不断完善和多智能体架构的成熟,AI自动化编程的覆盖范围将持续扩大,最终实现从需求到交付的全流程自动化。对于每一位希望提升AI协作效率的开发者来说,学会区分"做什么"和"怎么做",是迈向高效AI工程化的第一步。
别再手把手教AI写代码了。告诉它你要什么,然后让它自己去干。
核心要点
- AI与人对齐的核心是对齐What to do(做什么),而非How to do(怎么做)
- How to do应被规范化为Harness(约束框架),作为可复用的工程资产沉淀下来
- Harness工程是实现AI全自动化的关键桥梁,连接人的意图与AI的执行能力
- 当Harness足够完善时,结合多智能体并发架构,可以实现端到端的全流程自动化开发
- 某些技术决策虽然看似是How,但因影响架构方向,仍需作为What to do与AI对齐
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。