AI日报:Claude自主任务超16小时,GPT5.5证明数学定理

2025年5月10日AI行业多项重磅突破,模型自主能力、数学推理和效率提升引发行业变革。
2025年5月10日,AI行业迎来密集突破:Claude Mythos Preview自主任务能力突破16小时门槛,GPT 5.5 Pro协助菲尔兹奖得主一小时内完成数周级数学证明,DeepSeek计划6月推出全模态V4.1模型,百度文心5.1将参数压缩至三分之一、成本降至6%,Cloudflare因AI效率提升裁员20%。这些动态表明模型自主能力、推理水平和效率正快速提升,AI对就业的冲击已从预测变为现实。
概览
2025年5月10日,AI行业迎来密集的重磅消息:Anthropic的Claude模型在自主任务上突破16小时门槛,GPT 5.5 Pro协助菲尔兹奖得主完成数学证明,DeepSeek加速多模态布局,百度文心5.1正式发布,Cloudflare因AI效率提升裁员20%。本文逐一梳理这些关键动态,并给出深度解读。
Claude Mythos Preview:自主任务能力跨入"隔夜"级别
Anthropic员工Alex Albert披露,评估机构METR近期对Claude Mythos Preview早期版本进行了风险评估。在228项任务套件中,该模型达到50%成功率对应的估计时长超过16小时,是此前最优模型的两倍以上。
这一数据的意义在于,前沿模型正从"数小时级"任务向"隔夜级"任务跨越。当模型能够在无人监督的情况下持续执行复杂任务超过半天,意味着我们正逐渐逼近无人托管部署的实际门槛。当然,METR也指出套件中超过16小时的任务样本较少,这一区间的测量统计存在不确定性,但趋势本身已经足够引人关注。
对于企业用户而言,这意味着未来的AI Agent可能真正胜任那些需要长时间自主运行的工作流——从代码审查到数据管道监控,从文档生成到复杂的多步骤研究任务。
GPT 5.5 Pro:一小时内完成数学家数周的证明工作
剑桥大学教授、菲尔兹奖得主Timothy Gowers在个人博客中透露,他使用尚未公开发布的ChatGPT 5.5 Pro,在一个小时内完成了关于合级直径上界估计的数学证明。此前该问题仅被证明存在指数级上界,而模型在多次交互迭代下自主将上界改进为多项式级。

审阅过该证明的MIT学生认为其"逻辑严密且思想巧妙",达到了人类数学家需要苦思数周才能产出的水平。不过需要注意两个关键限制:第一,模型尚未公开发布;第二,证明过程包含了人类交互引导,因此目前还无法进行独立的端到端复现。
尽管如此,这一案例标志着大语言模型在数学推理领域的能力已经从"辅助计算"迈向"协作创造"。如果GPT 5.5 Pro正式发布后能稳定复现类似表现,将对数学研究的工作范式产生深远影响。
DeepSeek:多模态内测开放,V4.1剑指全模态覆盖
DeepSeek近期大幅放开了实图模式的内测权限,多数账号已可在对话界面上传图片进行语义理解与跨媒介交互。据多家媒体报道,DeepSeek计划在6月推出V4.1模型,补齐图像与音频处理能力,实现全模态覆盖。新版本预计还将支持MCP协议,打通企业及工具链生态。
目前实图模式仍处于内测状态,具体能力边界和稳定性有待正式发布后观察。但从战略节奏来看,DeepSeek正在加速从"纯文本强者"向"全模态平台"转型,这与OpenAI、Google等国际厂商的路线趋同。
百度文心5.1:参数压缩三分之二,成本降至6%
百度正式推出文心大模型5.1,已上线千帆模型广场和文心一言。新版本采用多维弹性预训练技术,将总参数压缩至5.0版本的约三分之一,预训练成本降至同规模业界模型的6%。

在LMSYS Arena的搜索榜单中,文心5.1评分位列国内第一、全球第四。不过需要指出,搜索能力评测与实际搜索体验存在差异,其API服务的稳定性和并发吞吐表现还需开发者进一步测试反馈。
文心5.1的核心亮点不在于"更大",而在于"更高效"。在大模型竞争进入下半场的当下,参数效率和推理成本正成为比拼的关键维度。百度此举表明,国内头部厂商已经开始从"堆参数"转向"降成本、提效率"的务实路线。
Cloudflare裁员20%:AI替代人力的连锁反应开始了
Cloudflare宣布裁减约20%的员工,总计约1100人。CEO Matthew Prince明确表示,裁员并非因为业绩下滑,而是AI技术大幅提升了运营效率,使公司能在收入创下历史新高的同时以更精简的结构运作。

数据显示,Cloudflare内部的AI使用量在过去三个月内增长了600%。这是一个值得高度关注的信号:当头部科技公司将"AI替代人力"正式写入财报的成本核算逻辑中,可能会在企业服务赛道引发连锁反应。其他公司的管理层会开始思考——如果Cloudflare能用AI减少20%的人力,我们是否也可以?
其他值得关注的动态
阶月星辰语音模型全球第三
在第三方评测机构Artificial Analysis的语音竞技场盲测排行榜中,阶月星辰的Step Audio 2.5 TTS模型位列全球第三,成为该榜单排名最高的中国语音合成模型。该榜单基于真实用户双盲偏好投票,反映了模型在自然度与情感表达方面的社区认可度。
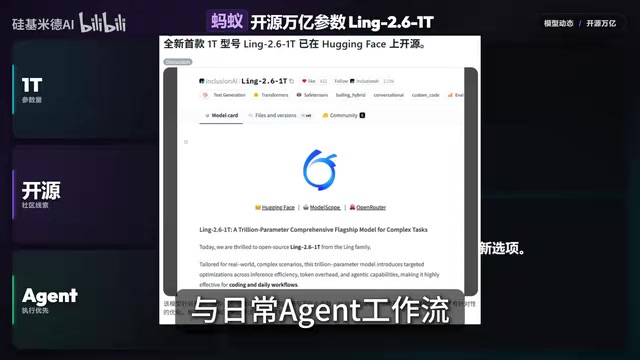
蚂蚁集团万亿参数模型现身Hugging Face
据Reddit社区线索,蚂蚁集团研究院已将名为Ling2.6-1T的万亿参数模型发布至Hugging Face。该模型针对实际复杂场景优化了推理效率和Token开销,特别适配编码与日常Agent工作流。不过目前暂未看到官方正式确认,实际表现有待权重验证和独立测试。
开源工具:GPT Image 2 PPT Skills
社区开发者Junyao在GitHub上开源了GPT Image 2 PPT Skills项目,利用GPT Image 2模型将文字或模板直接转换为视觉风格强烈的幻灯片。目前该项目强依赖特定模型的图像理解能力,文字渲染准确性和版式排版仍需人工校验。
肿瘤决策AI系统
Onco Agent研究团队在Hugging Face发布了技术预印本,展示了一个结合双模型架构、八节点拓扑与分级检索生成的肿瘤决策系统。由于基于合成数据且尚未经过大规模临床盲审,现阶段主要提供多智能体安全架构的工程参考,不能直接应用于实际医疗诊断。
总结与展望
今天的AI行业动态呈现出几个清晰的趋势:模型自主能力的时间尺度正在拉长(Claude 16小时+),数学推理能力正在接近专家水平(GPT 5.5 Pro),全模态覆盖成为标配(DeepSeek V4.1、文心5.1),而AI对就业市场的冲击已经从预测变为现实(Cloudflare裁员20%)。
对于从业者而言,关注模型能力边界的扩展固然重要,但更值得思考的是:当AI能够自主工作16小时、能够辅助完成顶级数学证明时,我们自身的工作方式和价值定位需要如何调整?
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。