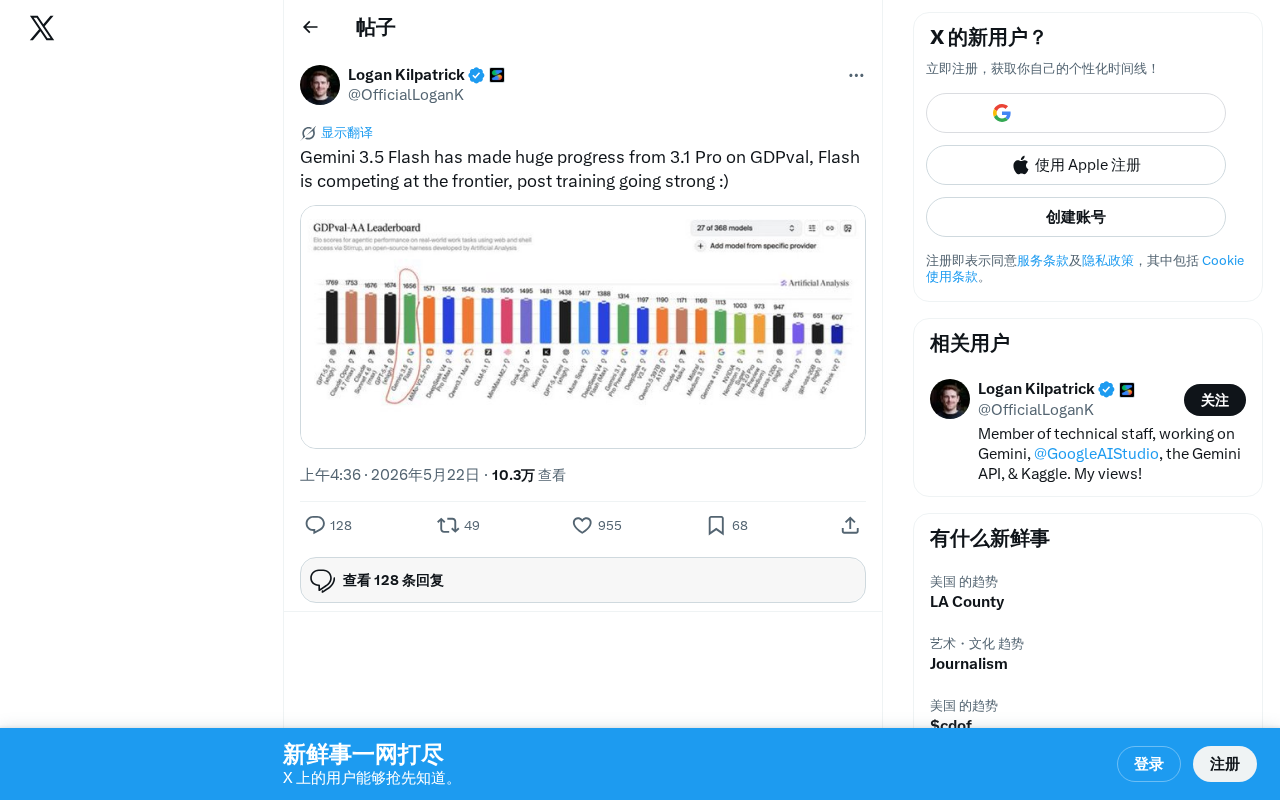
Gemini 3.5 Flash在GDPval基准上实现巨大飞跃

Gemini 3.5 Flash通过后训练技术实现性能飞跃,逼近前沿大模型水平。
Google发布的Gemini 3.5 Flash在GDPval综合基准上大幅超越上一代Gemini 3.1 Pro,标志着轻量级Flash模型正逼近前沿水平。这一突破主要得益于RLHF、指令微调、DPO等后训练技术的精进,能在不增加推理成本的前提下显著提升模型质量。Flash与Pro的传统定位界限正在模糊,高质量低成本模型的出现将降低AI大规模部署门槛,性价比"甜点"区间成为厂商竞争焦点。
核心发现:Flash模型正在逼近前沿水平
Google最新发布的Gemini 3.5 Flash模型在GDPval基准测试中展现出令人瞩目的进步,相比此前的Gemini 3.1 Pro实现了显著提升。这意味着一个定位为轻量级、高效率的"Flash"模型,正在性能上挑战前沿(frontier)级别的大模型。
GDPval(General Domain Performance Validation)是一个综合性的大语言模型评估基准,旨在衡量模型在多种通用任务上的实际表现能力,包括推理、知识问答、代码生成、多语言理解等维度。与单一维度的基准测试不同,GDPval试图提供一个更贴近真实使用场景的综合评分,因此被业界视为衡量模型"实战能力"的重要参考指标之一。Gemini 3.5 Flash在这一综合性基准上的突破,意味着它不是在某个单一任务上取巧,而是实现了全面的能力跃升。
后训练技术的强大推动力
从这次评测结果来看,Gemini 3.5 Flash的进步很大程度上得益于后训练(post-training)技术的持续优化。后训练是指在大语言模型完成预训练(即在海量文本数据上学习语言模式)之后,通过一系列精细化技术进一步提升模型表现的过程。核心技术包括:RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习),通过人类评估员对模型输出进行排序,训练奖励模型,再用强化学习优化生成策略;指令微调(Instruction Tuning),使用高质量的指令-回答对让模型更好地遵循用户意图;以及DPO(Direct Preference Optimization)等更新的对齐技术。
后训练的核心价值在于,它能在不增加模型参数量(即不增加推理成本)的前提下,显著提升模型的输出质量和安全性。这意味着Flash模型可以在保持其速度和成本优势的同时,通过更精细的后训练流程获得接近甚至超越上一代更大模型的表现。
这一趋势表明,Google在后训练阶段的投入正在产生显著回报。Flash系列模型本身在推理速度和成本效率上就具有优势,如今在质量维度上也开始追赶甚至超越上一代Pro级别模型,这对整个AI应用生态有着深远影响。
Flash vs Pro:模型定位的重新思考
传统上,Google的模型产品线中,Pro代表更强的能力,Flash代表更快的速度和更低的成本。Flash系列模型通常采用更小的参数规模、更高效的注意力机制(如多查询注意力MQA或分组查询注意力GQA),以及可能的模型蒸馏技术来实现高效推理。蒸馏是指将大模型(教师模型)的知识压缩到小模型(学生模型)中,使小模型在保持较高性能的同时大幅降低计算开销。这些技术使Flash模型在延迟(latency)和吞吐量(throughput)上远优于Pro级模型,每token的推理成本通常低一个数量级。
然而Gemini 3.5 Flash超越3.1 Pro的表现,正在模糊这一界限:
- 性能跨越:Flash不再只是"够用"的廉价替代品,而是在关键基准上达到前沿竞争力
- 效率红利:用户可能以更低的成本获得此前需要Pro级模型才能提供的质量
- 迭代加速:代际进步(3.1到3.5)的幅度超出预期,暗示Google的模型迭代节奏正在加快
这种定位的模糊化实际上反映了一个更深层的行业趋势:模型能力的"下沉"速度远超预期。今天旗舰模型的能力,可能在半年后就能被效率优化后的轻量模型复现。
对开发者和行业的意义
对于AI应用开发者而言,这是一个积极信号。高质量但低成本的模型意味着更多应用场景可以被经济地覆盖。当Flash级别的模型就能提供前沿水平的输出质量时,大规模部署AI应用的门槛将进一步降低。
当前大模型领域的前沿竞争主要集中在OpenAI(GPT-4o系列)、Google(Gemini系列)、Anthropic(Claude系列)和Meta(Llama系列)之间。竞争已从单纯的"谁的旗舰模型最强"演变为多维度的较量:旗舰性能、性价比、推理速度、多模态能力、长上下文支持等。特别是在"性价比甜点"区间——即以最低成本提供足够好的质量——已成为商业化落地的关键战场,因为绝大多数实际应用并不需要最顶级模型的全部能力。
这也加剧了大模型厂商之间的竞争——不仅要比拼旗舰模型的天花板,还要在性价比最优的"甜点"区间展开激烈角逐。Google通过后训练技术的精进,正在这一赛道上建立优势。对于开发者而言,选择模型的决策框架也需要随之更新:不再是简单地"用最贵的模型获得最好的效果",而是需要根据具体任务的质量要求、延迟敏感度和成本预算,在日益丰富的模型矩阵中找到最优解。
核心要点
- Gemini 3.5 Flash在GDPval基准上大幅超越Gemini 3.1 Pro,展现代际飞跃
- Flash级别模型正在性能上逼近前沿(frontier)水平,模糊了Pro与Flash的传统定位
- 后训练技术(包括RLHF、指令微调、DPO等)是此次性能提升的关键驱动力,能在不增加推理成本的前提下大幅提升质量
- 高质量低成本模型的出现将降低AI大规模部署的门槛,性价比"甜点"区间成为厂商竞争焦点
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。
 科技前沿
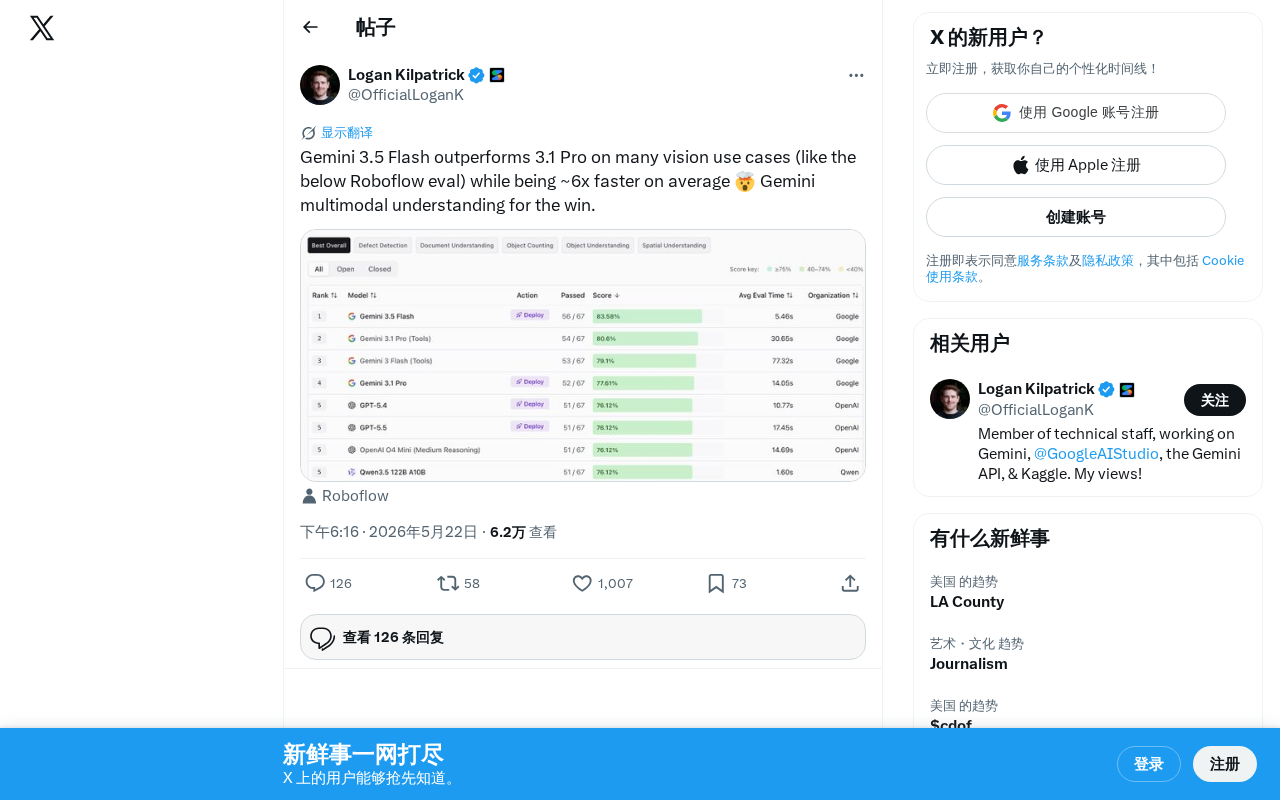
科技前沿Gemini 3.5 Flash视觉能力超越Pro版,速度快6倍
Roboflow评测显示Google Gemini 3.5 Flash在多项视觉理解任务中超越Gemini 3.1 Pro旗舰模型,推理速度快约6倍。轻量级模型实现性能与速度双赢,为开发者提供高性价比的多模态AI方案。